JSON Tutorial
Introduction
JSON (JavaScript Object Notation) offers a simple standard that makes it possible to encode data in a structured way and to transfer and store it in a human- and machine-readable form. Due to various advantages, such as the simplicity of the application and the simplified integration into JavaScript, the standard is very popular and is increasingly used in communication with web services.
To simplify the processing of JSON data, IGUASU offers various Processors, some of the most important of which will be illustrated in this tutorial. The aim here is to generate the following data flow, which is used to collect and process vulnerability information from the National Vulnerability Database (NVD).
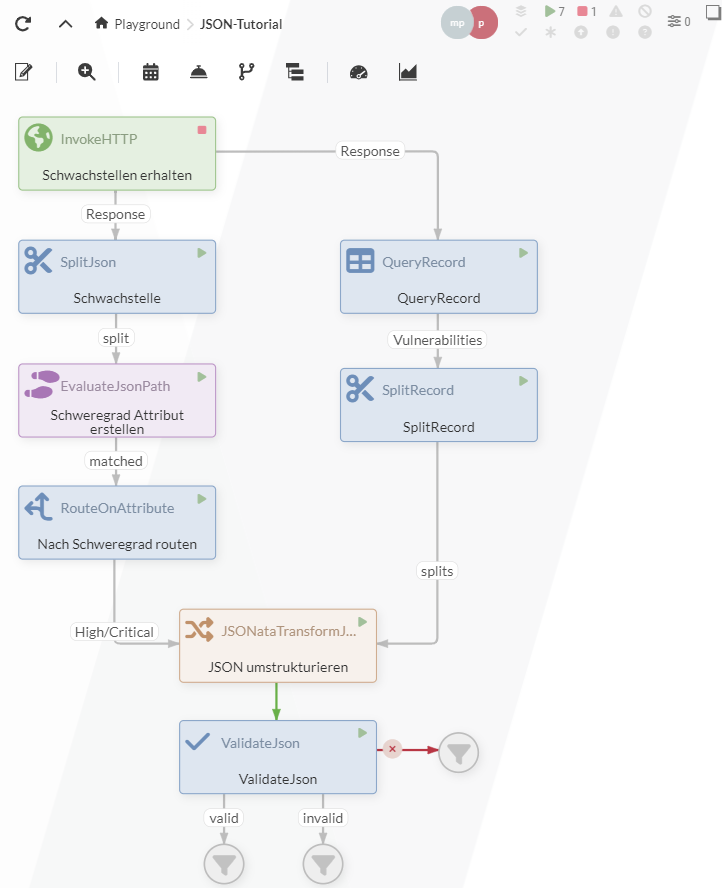
For this tutorial it is advantageous to have completed previous tutorials, as some steps are described more extensively there. An example of the completed tutorial can be downloaded with the following link: JSON-Tutorial.json.
Part 1: Collecting vulnerability information
1.1 InvokeHTTP-Processor
The NVD is the US government’s repository for standards-based vulnerability management data. The publicly provided interface makes it possible to retrieve and process information on identified vulnerabilities.
Since no API key needs to be created for this tutorial, the number of possible requests is limited. If the tutorial example is to be used and expanded further, individual API access would need to be requested.
For the tutorial, however, it is sufficient to send an HTTP GET request to the following URL
https://services.nvd.nist.gov/rest/json/cves/2.0.
To send an HTTP request, an HTTP Invoke Processor is therefore created, entered as HTTP Method GET and the URL is inserted.
For this example, we want to retrieve all vulnerabilities that have been modified in the last 24 hours.
To do this, the parameters lastModStartDate and lastModEndDate must be defined in the request.
They specify the time span for which we want to retrieve vulnerability data.
To ensure that we always retrieve the last 24 hours with each call, we generate these parameters dynamically with the NiFi Expression Language:
-
lastModStartDate:
${now():minus(86400000):format("yyyy-MM-dd’T’HH:mm:ss.SSS’Z'")} -
lastModEndDate:
${now():format("yyyy-MM-dd’T’HH:mm:ss.SSS’Z'")}
Inserted into the URL, we therefore receive:
https://services.nvd.nist.gov/rest/json/cves/2.0?&lastModStartDate=${now():minus(86400000):format("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")}&lastModEndDate=${now():format("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")}If you now execute this Processor in the isolated test execution, the results obtained can be viewed under Response.
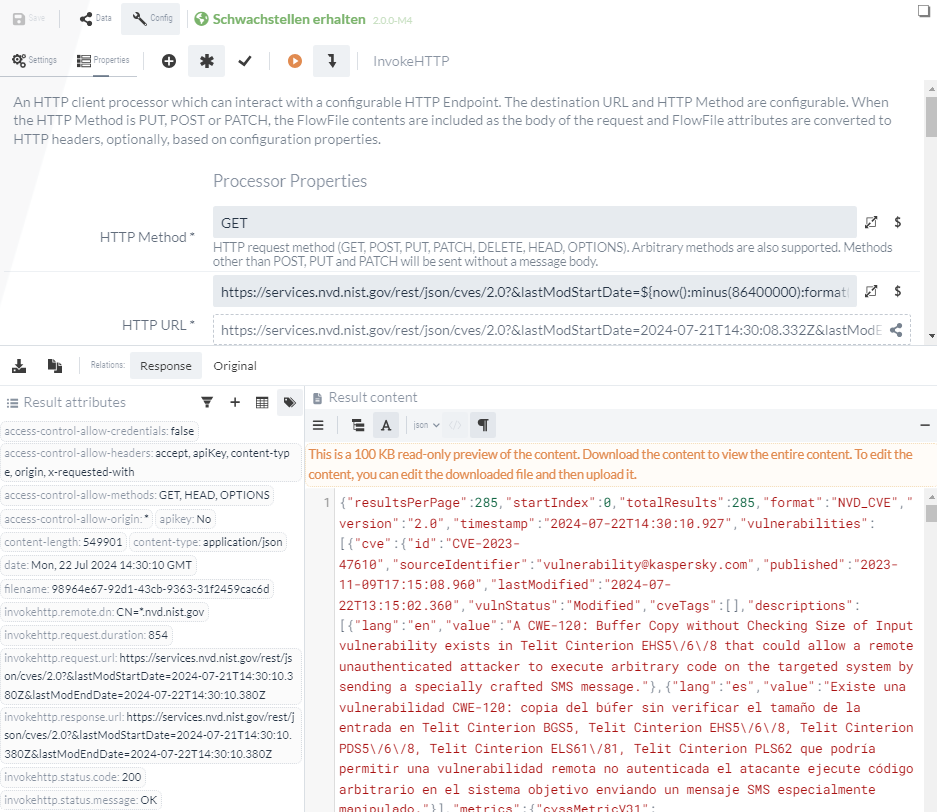
1.2 SplitJSON-Processor
The JSON object obtained contains an vulnerabilities array in which the modified vulnerabilities of the last 24 hours are given.
For this tutorial, the bundled structure is to be resolved and individual FlowFiles are to be generated for the individual vulnerabilities for further processing.
The SplitJson-Processor, which can be used to split JSON structures, can be used for this purpose.
To configure the SplitJson Processor, the point at which the data is to be split must be specified.
As the required information is located in the vulnerabilities array within the result object, the desired path can be specified to retrieve the information.
$.vulnerabilitiesIn addition, it must be determined how null values are to be stored, which can be set to empty string for this tutorial.
With the complete configuration, the Processor should look as follows:
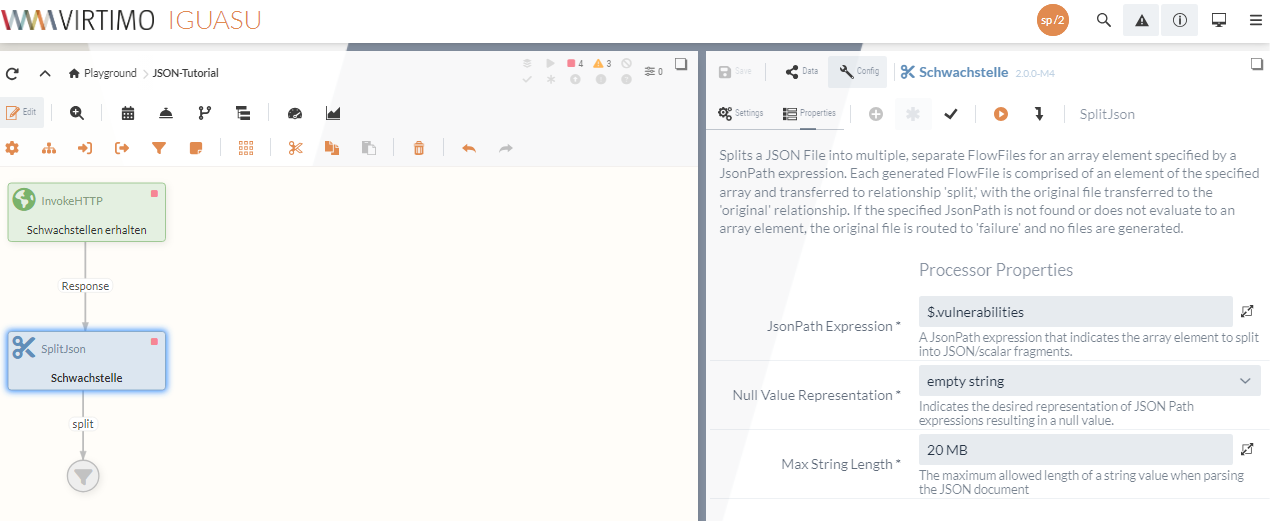
Part 2: Processing the JSON data
The data, which has been split into individual FlowFiles in this way, now looks something like this (shortened for better readability):
{
"cve": {
"id": "CVE-2021-1262",
"sourceIdentifier": "ykramarz@cisco.com",
"published": "2021-01-20T20:15:14.970",
"lastModified": "2024-03-21T20:02:29.753",
"vulnStatus": "Analyzed",
"descriptions": [
{
"lang": "en",
"value": ...
},
...
],
"metrics": {
"cvssMetricV31": [
{
"source": "nvd@nist.gov",
"type": "Primary",
"cvssData": {
"version": "3.1",
"vectorString": "CVSS:3.1/AV:L/AC:L/PR:L/UI:N/S:U/C:H/I:H/A:H",
"attackVector": "LOCAL",
"attackComplexity": "LOW",
"privilegesRequired": "LOW",
"userInteraction": "NONE",
"scope": "UNCHANGED",
"confidentialityImpact": "HIGH",
"integrityImpact": "HIGH",
"availabilityImpact": "HIGH",
"baseScore": 7.8,
"baseSeverity": "HIGH"
},
"exploitabilityScore": 1.8,
"impactScore": 5.9
}
],
"cvssMetricV30": [
...
],
"cvssMetricV2": [
...
]
},
"weaknesses": [
...
],
"configurations": [
....
],
"references": [
...
]
}
}In den weiteren Bearbeitungsschritten sollen nun die relevanten Daten identifiziert werden.
Um den Schweregrad einer Schwachstelle besser einzuordnen, existieren unterschiedliche Bewertungssysteme.
Die NVD bietet dabei für jede Schwachstelle die Bewertung nach dem Common Vulnerability Scoring System (CVSS) V2.0 und V3.X an.
In diesem Tutorial sollen die Schwachstellen ermittelt werden, die nach CVSS V3.X mit High oder Critical bewertet wurden (Severity Score 6.9 oder höher).
2.1 EvaluateJsonPath
Für formatabhängige Datenabfragen in JSON eignet sich der EvaluateJsonPath-Processor. Durch dynamische Properties können JSONPath-Abfragen durchgeführt werden, um bestimmte Inhalte zu ermitteln. Die ermittelten Inhalte können zusätzlich im Anschluss in einem FlowFile-Attribut oder im Content gespeichert werden.
Um eine schnellere Bewertung des Schweregrads der Schwachstellen zu ermöglichen, soll der CVSS V3.X Score als Attribut gespeichert werden.
Um dies zu erreichen, wird unter der Angaben Destination die Option flowfile-attribute ausgewählt.
Über eine neu angelegte dynamische Property kann dann der Name des Attributes und der Inhalt definiert werden.
Als Name wird in diesem Tutorial Severity ausgewählt und der Inhalt ist die JSONPath-Abfrage auf die CVSS V3.X Bewertung, die mit dem folgenden JSONPath abgerufen werden kann:
$.cve.metrics.cvssMetricV31[0].cvssData.baseSeverity.
Mit der vollständigen Konfiguration wird nun in jedem FlowFile das Attribut Severity erstellt, in dem die Bewertung der jeweiligen Schwachstelle eingetragen werden.
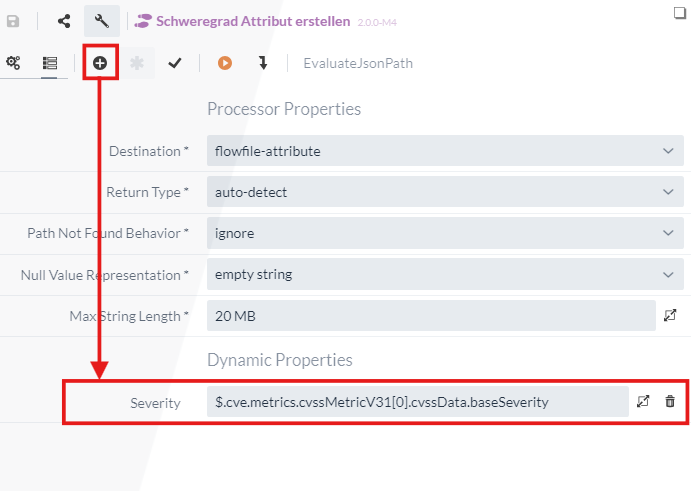
Als Relation für die weitere Verarbeitung wird im Anschluss matched ausgewählt, da die Daten weitergeleitet werden sollen, die eine Information in der angegebenen JSON-Struktur beinhalten.
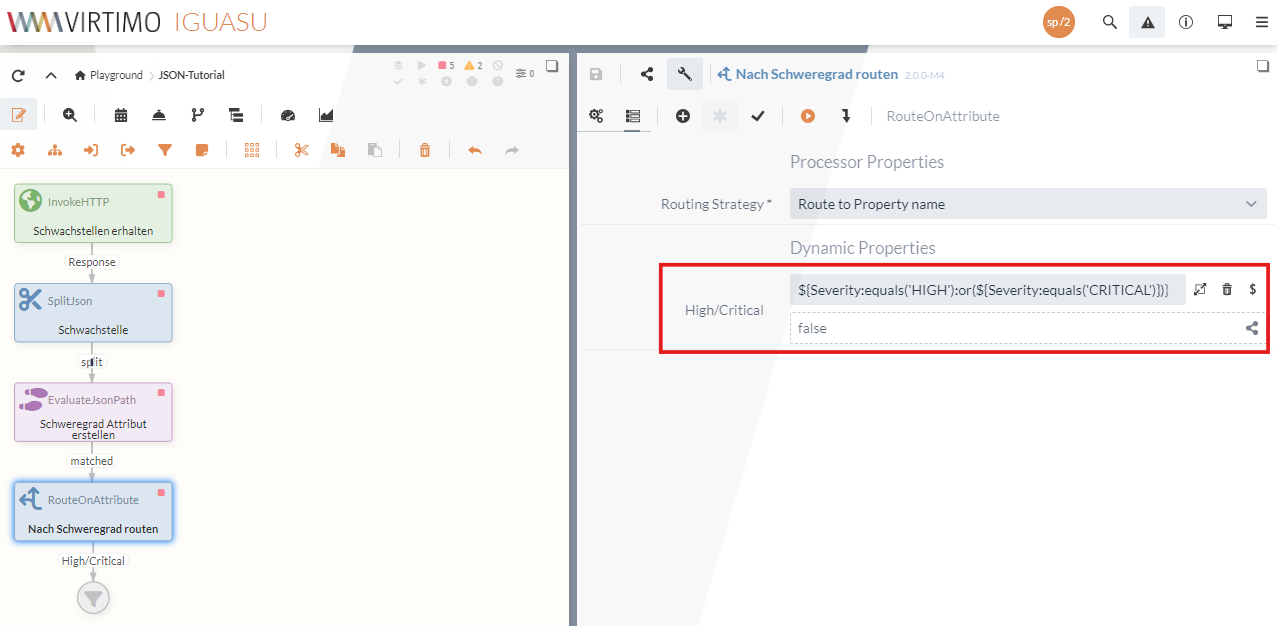
2.2 RouteOnAttribute
Das neu angelegte Attribut kann im Anschluss genutzt werden, um die Schwachstellen mit einer hohen oder kritischen Bewertung herauszufiltern. Für diesen Zweck kann der RouteOnAttribute-Processor genutzt werden, durch den das Routen von FlowFiles ermöglicht wird.
|
Der RouteOnAttribute-Processor ist ein formatunabhängiger Processor und kann ebenfalls für andere Datenformate wie beispielsweise XML- oder CSV-Daten genutzt werden. |
Die Routing Strategy kann hier standardmäßig bei Route to Property name belassen werden.
Ähnlich wie beim EvaluateJsonPath-Processor wird über eine dynamische Property eine Abfrage durch die NiFi Expression Language durchgeführt.
Somit kann die Schwachstellen-Bewertung überprüft werden.
Im Rahmen des Tutorials wird High/Critical als Property-Name ausgewählt.
Durch die Abfrage ${Severity:equals('HIGH'):or(${Severity:equals('CRITICAL')})} kann nach den entsprechenden Schwachstellen gefiltert und zugewiesen werden.
Die dadurch vorhandene High/Critical-Relation kann im Anschluss genutzt werden, um die gefilterten Schwachstellen an den nächsten Processor weiterzuleiten.
|
Da es sich um aktuelle und echte Schwachstellen handelt, kann es passieren, dass keine Schwachstellen mit hohem oder kritischen Schweregrad vorhanden sind.
In diesen Fällen sollte |
2.3 JSONataTransformJSON
In einem letzten Verarbeitungsschritt sollen die vorhandenen Daten umstrukturiert werden, da viele der vorhandenen Informationen nicht benötigt werden. Für diesen Zweck kann der JSONataTransformJSON-Processor genutzt werden.
Bei der Konfiguration des Processors kann ausgewählt werden, welche Daten umstrukturiert werden sollen.
Zur Auswahl stehen hierbei die FlowFile Attribute, der Content und eine leere JSON-Struktur.
Da es in diesem Fall auf den Content ausgeführt werden soll, muss als Input Data Content ausgewählt werden.
Zusätzlich muss ein Haken bei dem Property Write Output gesetzt sein, damit die Ergebnisse ebenfalls im Content abgespeichert werden.
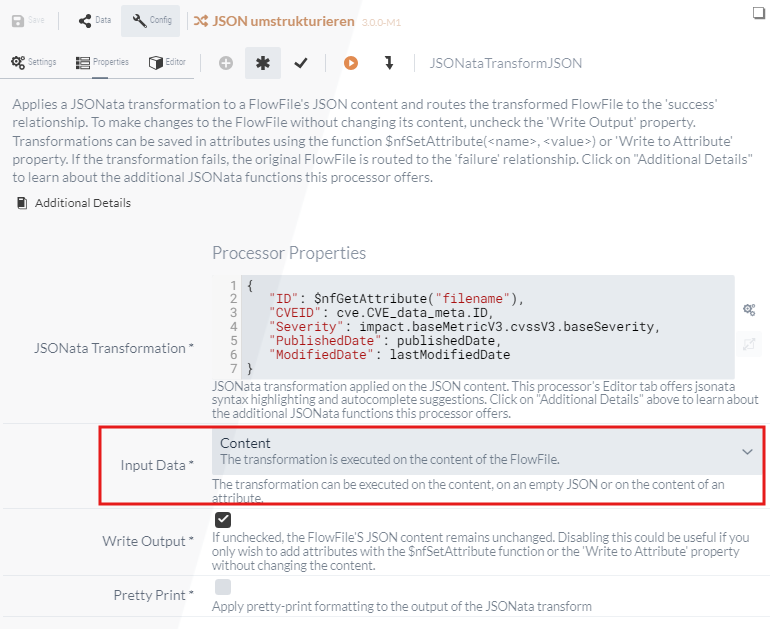
Um die Struktur anzupassen, kann der Editor genutzt werden.
In diesem Abschnitt kann die Umstrukturierung umgesetzt werden, wobei zusätzlich verschiedene Funktionen zur Verfügung stehen.
Beispielsweise kann mit der Funktion $nfGetAttribute("filename") auf das Attribut filename des FlowFiles zugegriffen werden.
Angaben des Eingangs-FlowFiles können auf ähnliche Weise neu zugewiesen werden, indem der Pfad der gewünschten Informationen eingetragen wird und dadurch einem neuen Schlüssel zugeordnet werden kann.
Im Folgenden ist eine solche Umstrukturierung ersichtlich, indem die FlowFile Dateinamen als ID genutzt werden und einige der relevanten Informationen einer Schwachstelle neu zugewiesen werden:
{
"ID": $nfGetAttribute("filename"),
"CVEID": cve.id,
"Severity": $nfGetAttribute("Severity"),
"Published": cve.published,
"Modified": cve.lastModified
}A comprehensive description of the JSONataTransformJSON Processor and other possible functions can also be found under JSONataTransformJSON.
Once the configuration is complete, the data flow is used to generate new JSON files containing only the essential information. After naming the individual Processors, the flow looks as follows:
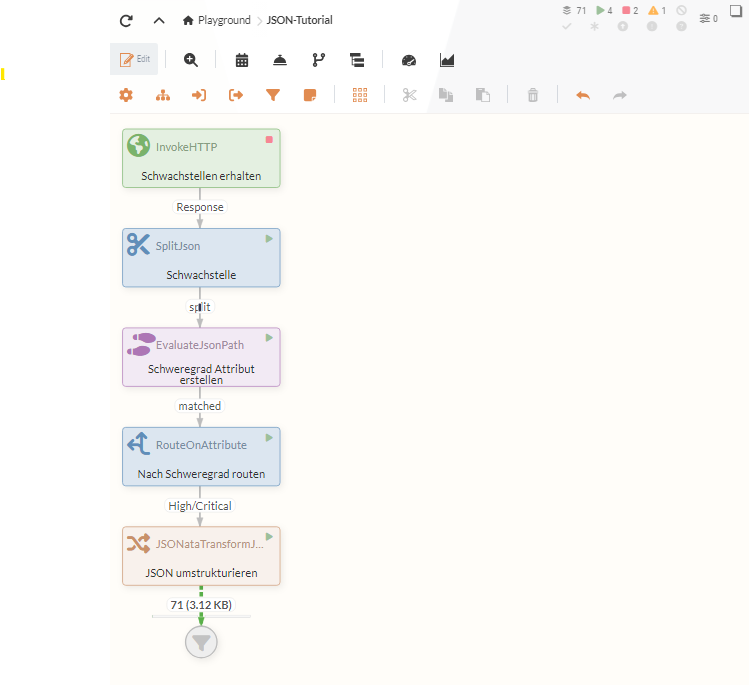
This data could now be used to create database entries or to use other Services.
Part 3: Record-oriented processing of JSON data
In addition to the procedure shown above, IGUASU offers the option of simplified processing of record-oriented data, i.e. the compilation of distinct units. Since not only JSON data enables a record-oriented structure, the Processors can also be used for other formats such as XML, CSV or similar formats.
Since individual weak points can be seen as records in this example, record-oriented processing of JSON data is a good idea. The functionalities illustrated in Part 2 for working with JSON data are nevertheless essential for handling complex JSON structures and cannot be completely replaced by record processors.
In this example, however, some of the intermediate steps shown above can be combined within the QueryRecord Processor, which means that record-oriented processing promises better performance in this case.
3.1 QueryRecord
When configuring the Processor, a number of points must be taken into account, which are described below. As already described in section 1.2, the weak points are located in an array within the data structure.
For the processing of multiple records, it is therefore important to start at this point - which can be ensured via a JSONTreeReader Service.
The data point at which reading is to be initiated can be defined as Starting Field Strategy.
As the desired data is located in the array at vulnerabilities, this can be entered as input.
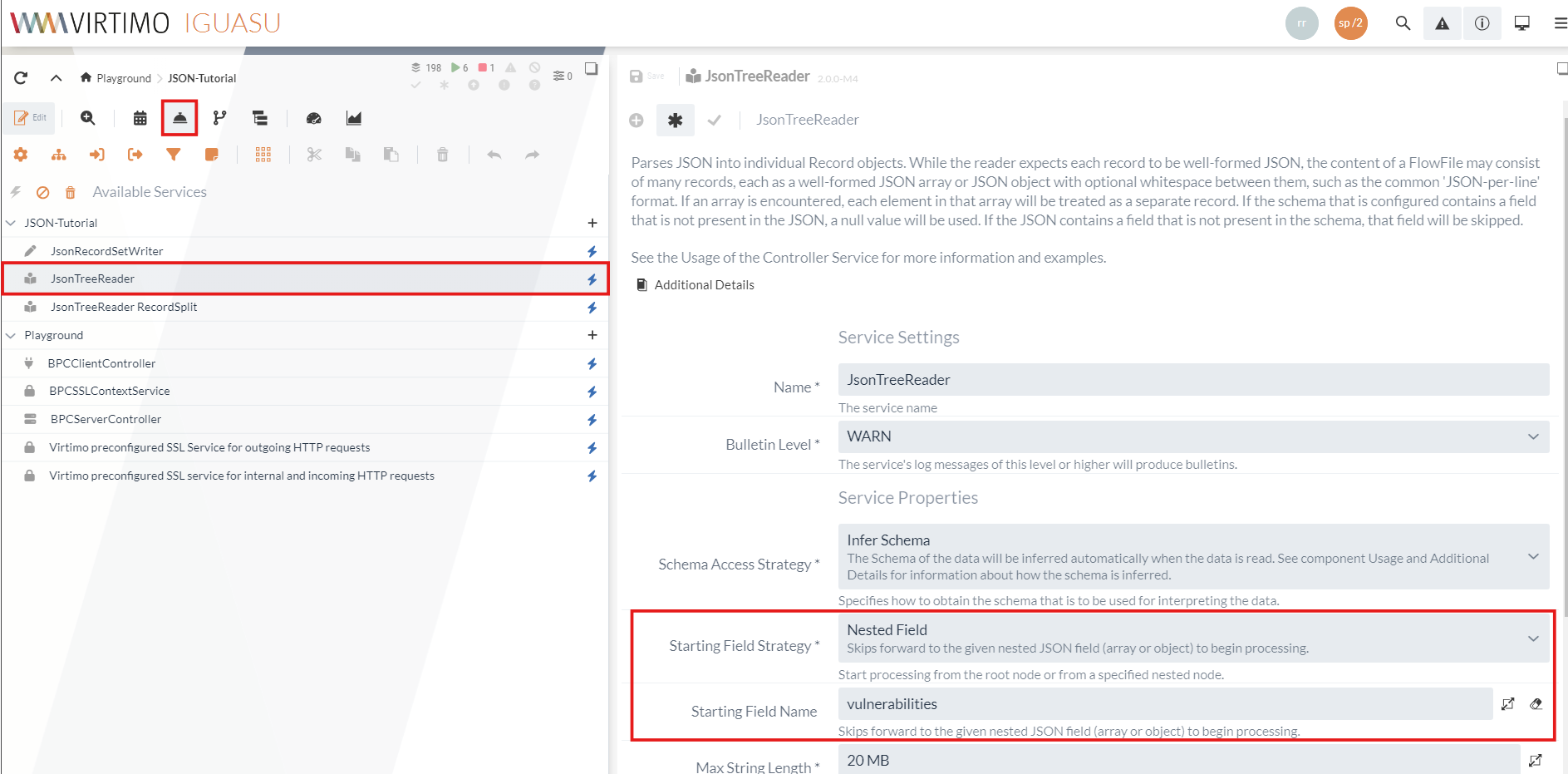
The configured JSONTreeReader service can then be defined as a reader in the QueryRecords Processor.
The Processor also requires a Writer, for which a JSONRecordSetWriter service must be created. The default settings can be retained and the Service can be selected in the Processor.
This ensures that the record-oriented vulnerabilities can be read and also generated as JSON output. However, similar to Part 2, filtering based on severity should also take place.
For this purpose, a dynamic property can be created via which a query can be made.
As the queries are made via SQL statements and SQL was originally developed for flat and not hierarchical data structures, it is often necessary to work with RPATH (record path) for JSON data.
In order to obtain the desired severity rating in this example, the following query can therefore be made:
SELECT *
FROM FLOWFILE
WHERE RPATH(cve, '/metrics/cvssMetricV31[0]/cvssData/baseScore') > 6.9Further information and examples on the use of RPATH can be found in the NiFi documentation.
The completed configuration looks as follows:
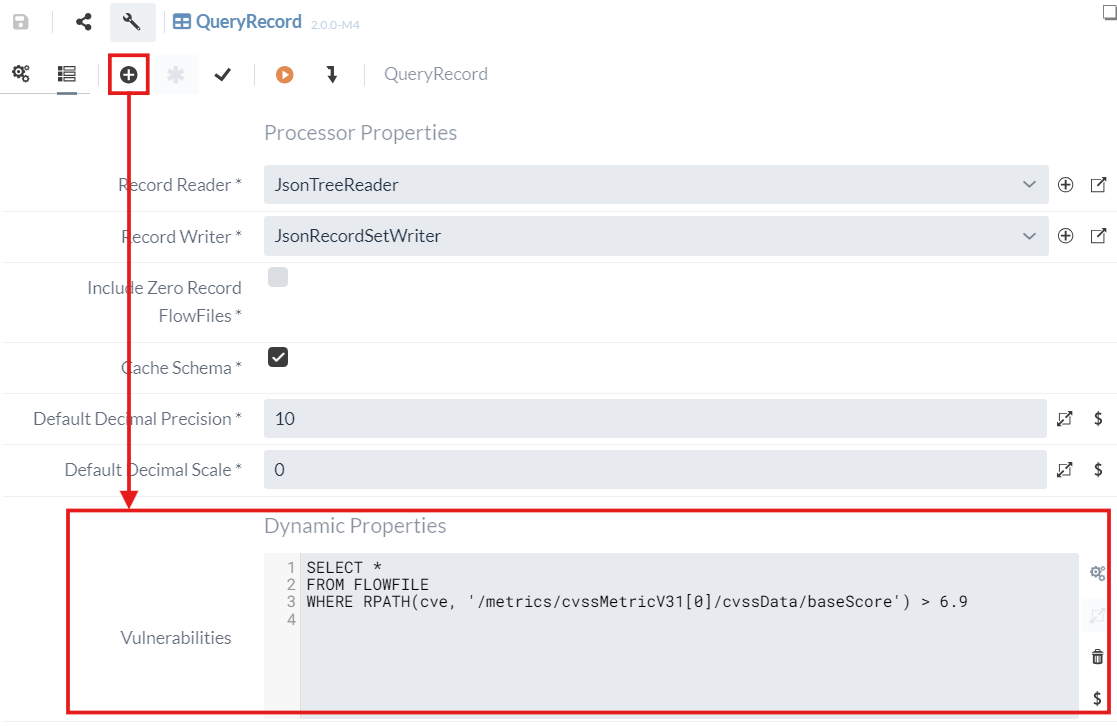
The QueryRecord Processor now determines the vulnerabilities that have received either a high or a critical rating.
However, the last step is to restructure the records in a similar way to section 2.3. The JSONataTransformJSON Processor can be used again for this purpose.
At this point, it would be possible to process the individual records as a single array and use the JSONataTransformJSON Processor to adjust the individual vulnerabilities within the array.
This could be achieved using the following JSON structure to transform the vulnerability data by combining the individual vulnerabilities in an array at entries:
{
"entries": [*.
{
"ID": $nfGetAttribute("filename"),
"CVEID": cve.id,
"Severity": $nfGetAttribute("Severity"),
"Published": cve.published,
"Modified": cve.lastModified
}
]
}However, to ensure better comparability with the original data flow, the individual records should be reintegrated into individual FlowFiles.
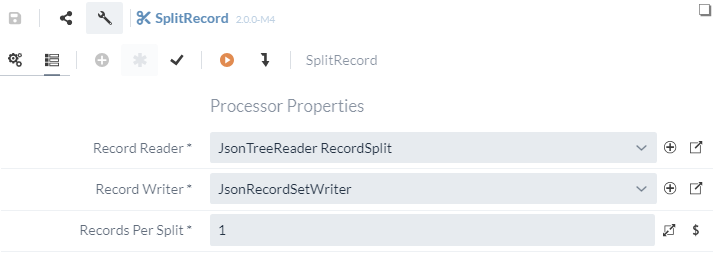
3.2 SplitRecord
The SplitRecord-Processor can be used to split records of any format. Unlike the previously used SplitJSON Processor, any format can be split by using Services for reading and writing FlowFiles, which means that this Processor can be used more universally. Similar to the QueryRecord Processor, the Reader and Writer must be defined for the configuration.
In this case, the originally created Writer can be used, as the functionality is also suitable at this point.
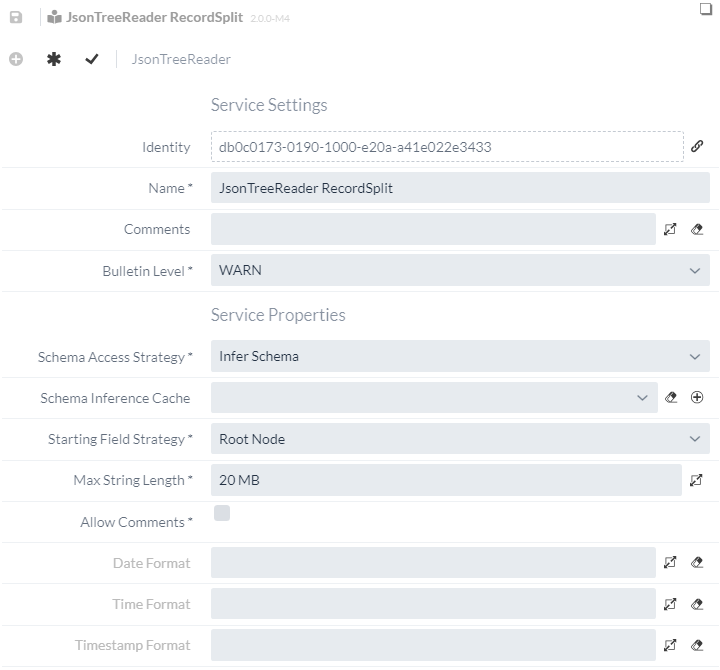
However, a new reader must be defined, as the Starting Field Name was defined in the previously configured Service, which no longer exists at this point.
Similar to the last section, a new JsonTreeReader service is therefore generated, whereby no further adjustments are necessary this time.
It should only be ensured that a different name is chosen for the Service for better differentiation.
In addition to the Reader and Writer, the SplitRecord Processor can be used to configure how many records should be contained in each split FlowFile.
As a vulnerability should be contained in each FlowFile, 1 can be entered here.
This completes the configuration of the Processor and should look like the following figure.
As the individual FlowFiles have a similar structure to the first data flow, the data can then be forwarded to the JSONataTransformJson Processor again, where it is restructured once more.
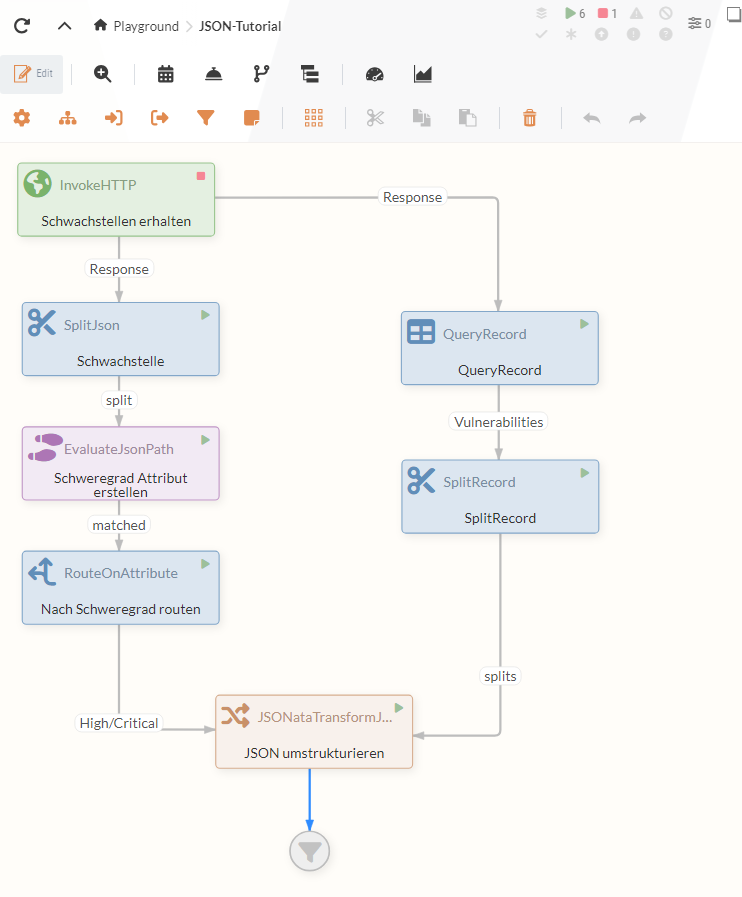
|
In this case, both data flows originating from the InvokeHTTP Processor fulfill the same function. To prevent the results from being duplicated at the end, the data flow should be stopped at one of the two sections. |
At this point in the flow, the data on existing vulnerabilities is available in the desired form. To ensure that the information contained also corresponds to your own expectations, a corresponding validation can be carried out.
Part 4: Validation of JSON data
The ValidateJson Processor can be used to validate JSON data.
This Processor is used to specify schemas that can be used to define a desired structure for the data.
This enables the JSON data format to be used safely and reliably.
To configure this Processor, the declarative programming language must be used to specify a schema for this purpose. The standards for creating a schema with the specifications and the different versions can be viewed at JSON schema. For the purposes of this tutorial, it is initially sufficient to create a simple schema for the existing FlowFiles in order to illustrate how the Processors work.
In general, general information such as a title and a description of the type of JSON files that are to be validated by the schema are defined first when creating the schema. Individual keys that occur in the JSON file and what they should look like can then be described under "Properties". Individual restrictions can also be defined, although only mandatory fields are to be defined under "Required" for the purposes of the tutorial.
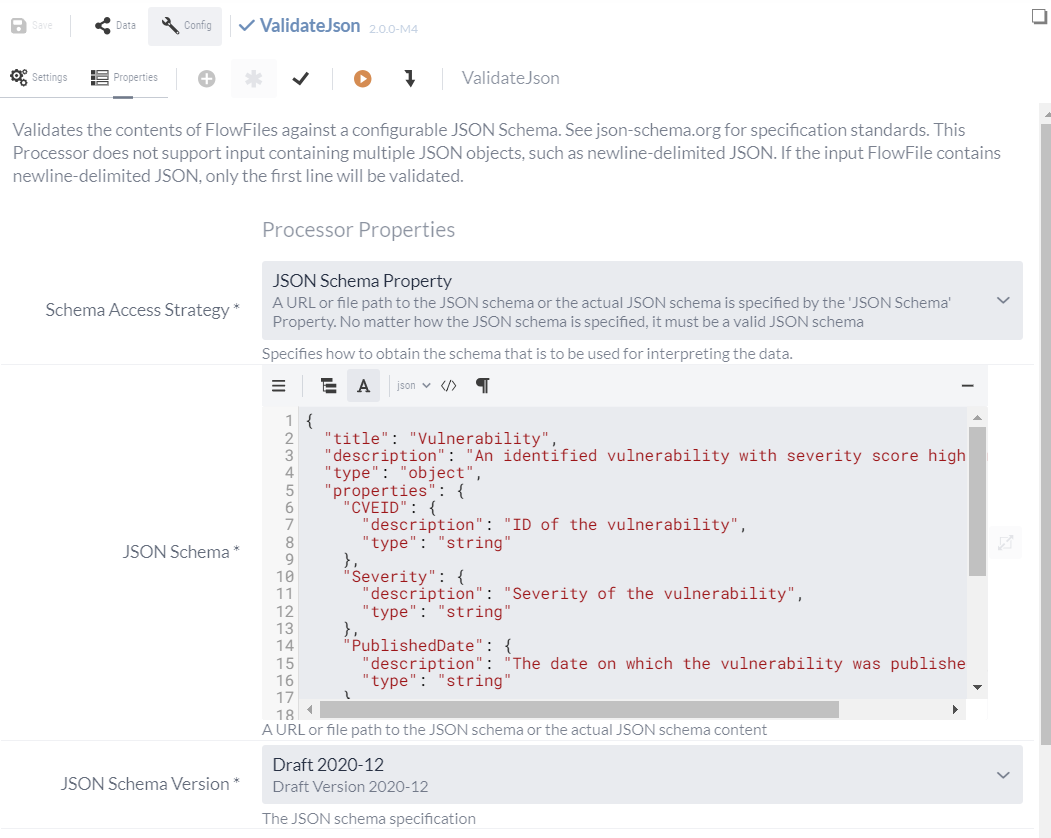
For example, a schema for validating the previously generated data could look like this:
{
"title": "Vulnerability",
"description": "An identified vulnerability with severity score high or critical",
"type": "object",
"properties": {
"ID": {
"description": "General ID of the request",
"type": "string"
},
"CVEID": {
"description": "ID of the vulnerability",
"type": "string"
},
"Severity": {
"description": "Severity of the vulnerability",
"type": "string"
},
"Published": {
"description": "The date on which the vulnerability was published",
"type": "string"
},
"Modified": {
"description": "The date on which the vulnerability was last modified",
"type": "string"
}
},
"required": [
"CVEID",
"Severity",
"Published"
]
}This simple schema specifies that all existing data must be available as a string and that CVEID, Severity and PublishedDate are mandatory fields.
This schema is then entered in the ValidateJson Processor at JSON Schema and the default value Draft 2020-12 can be left unchanged as Schema Version.
With the adjustments, the Processor is already configured and still needs to be integrated into the existing data flow. To do this, the success relation of the JSONataTransformJSON Processor is dragged to the Processor and the results still need to be routed. The valid, invalid and failure relations are available in the ValidateJson Processor. These connections can be routed to individual Funnels to display the results in the data flow.
This concludes the tutorial on processing JSON files.
This tutorial has shown various processing options that can be used to customize, process and validate JSON structures.