JSON Tutorial
Einführung
JSON (JavaScript Object Notation) bietet einen einfachen Standard, der es ermöglicht, Daten strukturiert zu kodieren und in menschen- und maschinenlesbarer Form zu übertragen und zu speichern. Aufgrund unterschiedlicher Vorteile, wie beispielsweise die Einfachheit der Anwendung und die vereinfachte Einbindung in JavaScript, ist der Standard sehr beliebt und wird vermehrt in der Kommunikation mit Webdiensten genutzt.
Um die Verarbeitung von JSON-Daten zu vereinfachen, bietet IGUASU verschiedene Processors an, von denen einige wichtige im Rahmen dieses Tutorials veranschaulicht werden sollen. Ziel ist hierbei, den folgenden Datenfluss zu generieren, mit dem Schwachstellen-Informationen von der National Vulnerability Database (NVD) gesammelt und verarbeitet werden.
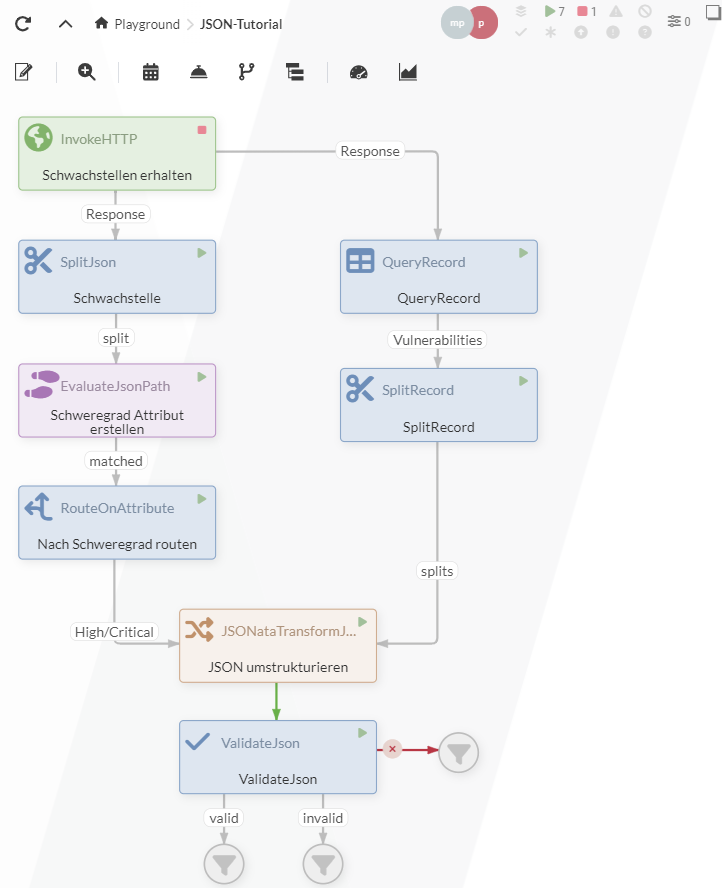
Für dieses Tutorial ist es vorteilhaft, vorangegangene Tutorials abgeschlossen zu haben, da einige Schritte dort umfangreicher beschrieben werden. Ein Beispiel des abgeschlossenen Tutorials kann mit folgendem Link heruntergeladen werden: JSON-Tutorial.json.
Teil 1: Das Sammeln der Schwachstellen-Informationen
1.1 InvokeHTTP-Processor
Die NVD ist das Repository der US-Regierung für standardbasierte Schwachstellenmanagement-Daten. Die öffentlich zur Verfügung gestellte Schnittstelle ermöglicht es, Informationen zu identifizierten Schwachstellen abzurufen und zu verarbeiten.
Da für dieses Tutorial kein API-Key angelegt werden muss, ist die Anzahl der möglichen Anfragen begrenzt. Falls das Beispiel des Tutorials weiterhin genutzt und ausgebaut werden soll, müsste ein individueller API-Zugang angefragt werden.
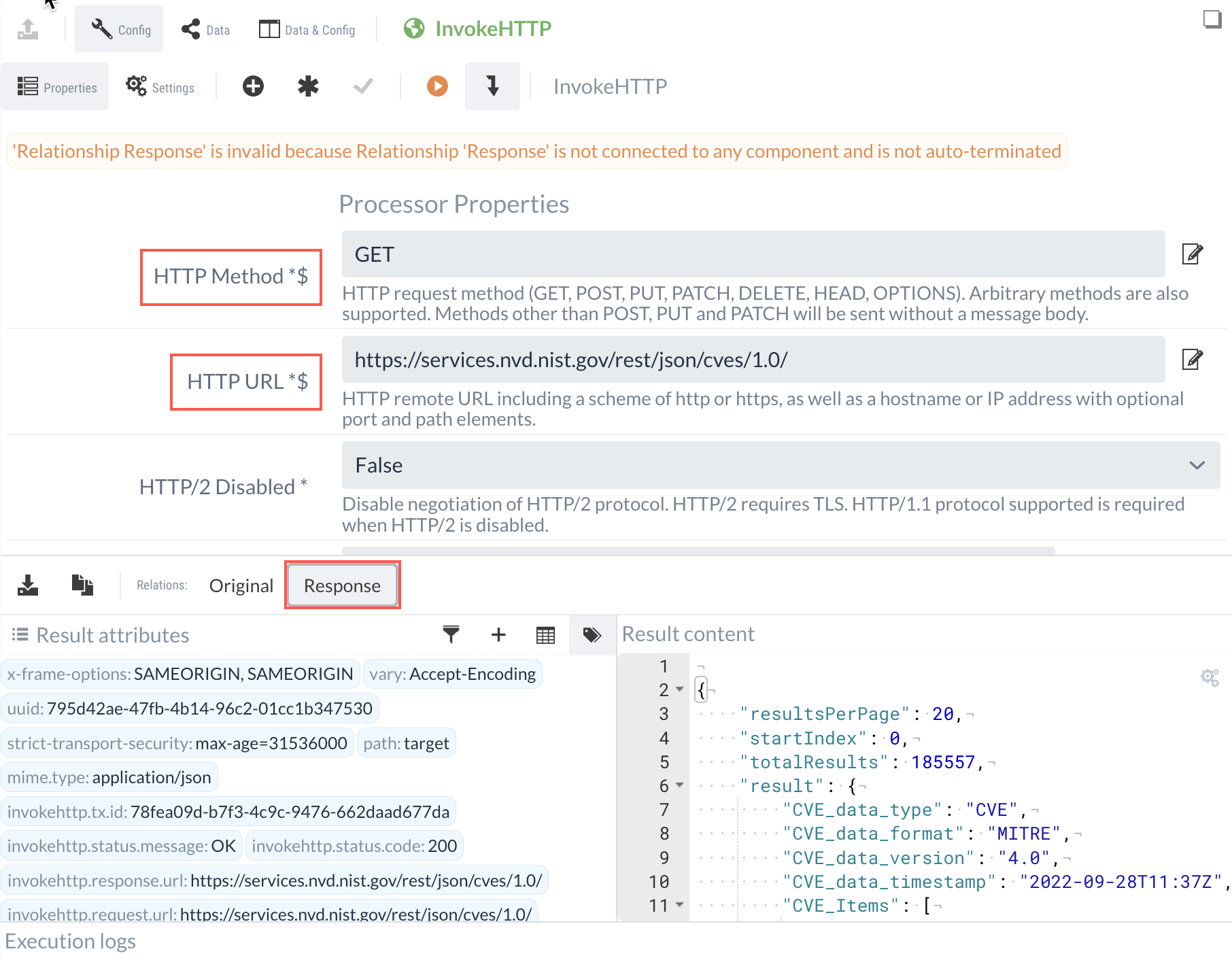
Für das Tutorial reicht es allerdings aus, eine HTTP GET Anfrage an die folgende URL zu senden
https://services.nvd.nist.gov/rest/json/cves/2.0.
Um eine HTTP-Anfrage zu senden, wird daher ein HTTP-Invoke-Processor erstellt, als HTTP Method GET eingetragen und die URL eingefügt.
Für dieses Beispiel wollen wir alle Schwachstellen, die in den letzten 24 Stunden modifiziert wurden abrufen.
Dafür müssen bei der Anfrage noch die Parameter lastModStartDate und lastModEndDate definiert werden.
Sie geben die Zeitspanne an, für die wir Schwachstellen-Daten abrufen wollen.
Damit wir bei jedem Aufruf immer die letzten 24 Stunden abrufen, erzeugen wir diese Parameter dynamisch mit der NiFi Expression Language:
-
lastModStartDate:
${now():minus(86400000):format("yyyy-MM-dd’T’HH:mm:ss.SSS’Z'")} -
lastModEndDate:
${now():format("yyyy-MM-dd’T’HH:mm:ss.SSS’Z'")}
In die URL eingefügt erhalten wir also:
https://services.nvd.nist.gov/rest/json/cves/2.0?&lastModStartDate=${now():minus(86400000):format("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")}&lastModEndDate=${now():format("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")}Führt man diesen Processor nun in der isolierten Testausführung aus, können die erhaltenen Ergebnisse unter Response eingesehen werden.
1.2 SplitJSON-Processor
Das erhaltene JSON-Objekt beinhaltet ein vulnerabilities Array, in dem die modifizierten Schwachstellen der letzten 24 Stunden gegeben sind.
Für dieses Tutorial soll die gebündelte Struktur aufgelöst werden und es sollen individuelle FlowFiles für die einzelnen Schwachstellen zur weiteren Verarbeitung generiert werden.
Dazu kann der SplitJson-Processor genutzt werden, mit dem JSON-Strukturen aufgeteilt werden können.
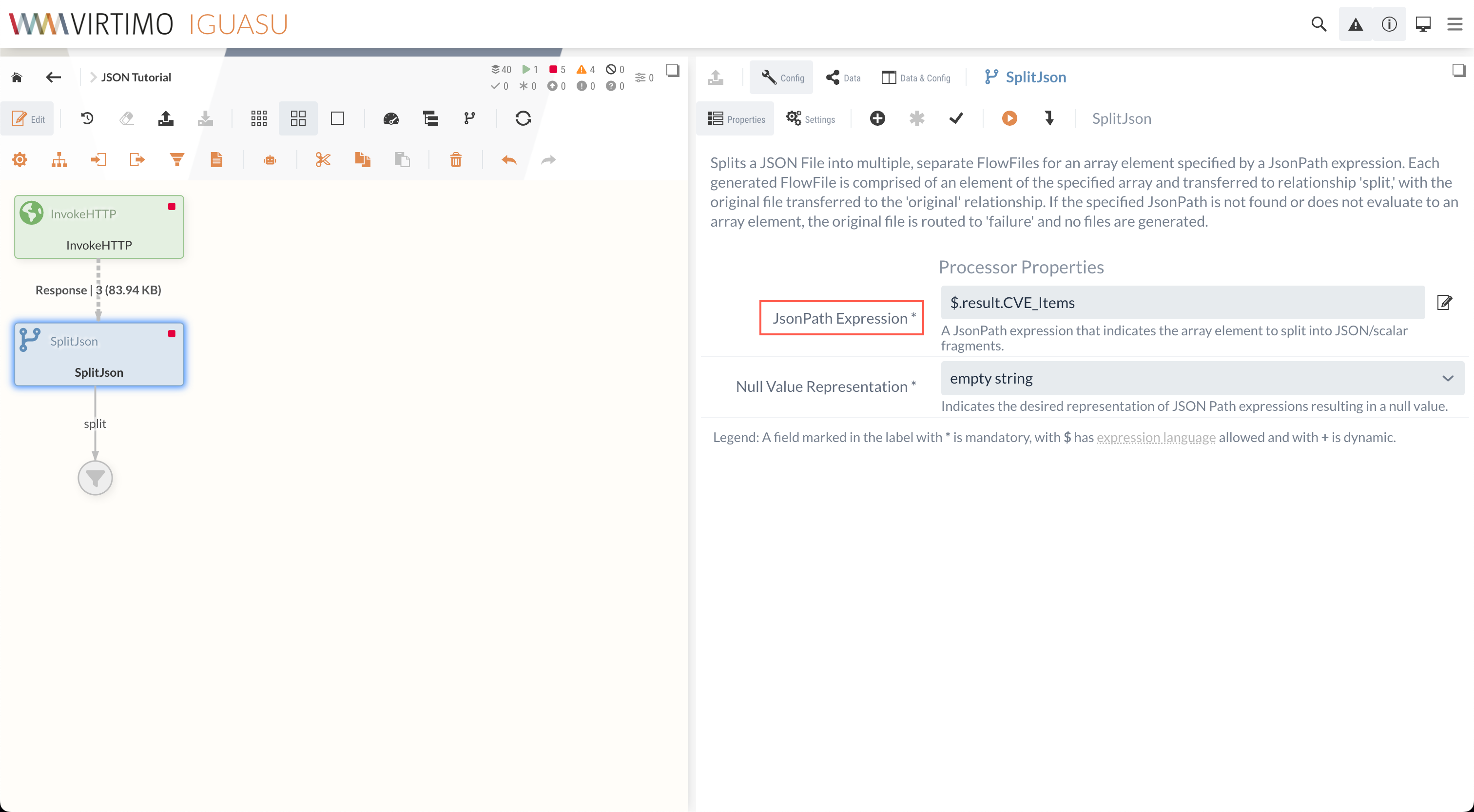
Zur Konfiguration muss für den SplitJson-Processor angegeben werden, an welchem Punkt die Daten aufgeteilt werden sollen.
Da sich die benötigten Informationen im vulnerabilities Array innerhalb des result Objekts befinden, kann der gewünschte Pfad angegeben werden, um die Information abzurufen.
$.vulnerabilitiesZusätzlich muss bestimmt werden, wie null-Werte gespeichert werden sollen, was für dieses Tutorial auf empty string gesetzt werden kann.
Mit der vollständigen Konfiguration sollte der Processor wie folgt aussehen:
Teil 2: Verarbeitung der JSON-Daten
Die Daten, die so in einzelne FlowFiles aufgeteilt wurden, sehen nun ungefähr wie folgt aus (gekürzt für bessere Lesbarkeit):
{
"cve": {
"id": "CVE-2021-1262",
"sourceIdentifier": "ykramarz@cisco.com",
"published": "2021-01-20T20:15:14.970",
"lastModified": "2024-03-21T20:02:29.753",
"vulnStatus": "Analyzed",
"descriptions": [
{
"lang": "en",
"value": ...
},
...
],
"metrics": {
"cvssMetricV31": [
{
"source": "nvd@nist.gov",
"type": "Primary",
"cvssData": {
"version": "3.1",
"vectorString": "CVSS:3.1/AV:L/AC:L/PR:L/UI:N/S:U/C:H/I:H/A:H",
"attackVector": "LOCAL",
"attackComplexity": "LOW",
"privilegesRequired": "LOW",
"userInteraction": "NONE",
"scope": "UNCHANGED",
"confidentialityImpact": "HIGH",
"integrityImpact": "HIGH",
"availabilityImpact": "HIGH",
"baseScore": 7.8,
"baseSeverity": "HIGH"
},
"exploitabilityScore": 1.8,
"impactScore": 5.9
}
],
"cvssMetricV30": [
...
],
"cvssMetricV2": [
...
]
},
"weaknesses": [
...
],
"configurations": [
....
],
"references": [
...
]
}
}In den weiteren Bearbeitungsschritten sollen nun die relevanten Daten identifiziert werden.
Um den Schweregrad einer Schwachstelle besser einzuordnen, existieren unterschiedliche Bewertungssysteme.
Die NVD bietet dabei für jede Schwachstelle die Bewertung nach dem Common Vulnerability Scoring System (CVSS) V2.0 und V3.X an.
In diesem Tutorial sollen die Schwachstellen ermittelt werden, die nach CVSS V3.X mit High oder Critical bewertet wurden (Severity Score 6.9 oder höher).
2.1 EvaluateJsonPath
Für formatabhängige Datenabfragen in JSON eignet sich der EvaluateJsonPath-Processor. Durch dynamische Properties können JSONPath-Abfragen durchgeführt werden, um bestimmte Inhalte zu ermitteln. Die ermittelten Inhalte können zusätzlich im Anschluss in einem FlowFile-Attribut oder im Content gespeichert werden.
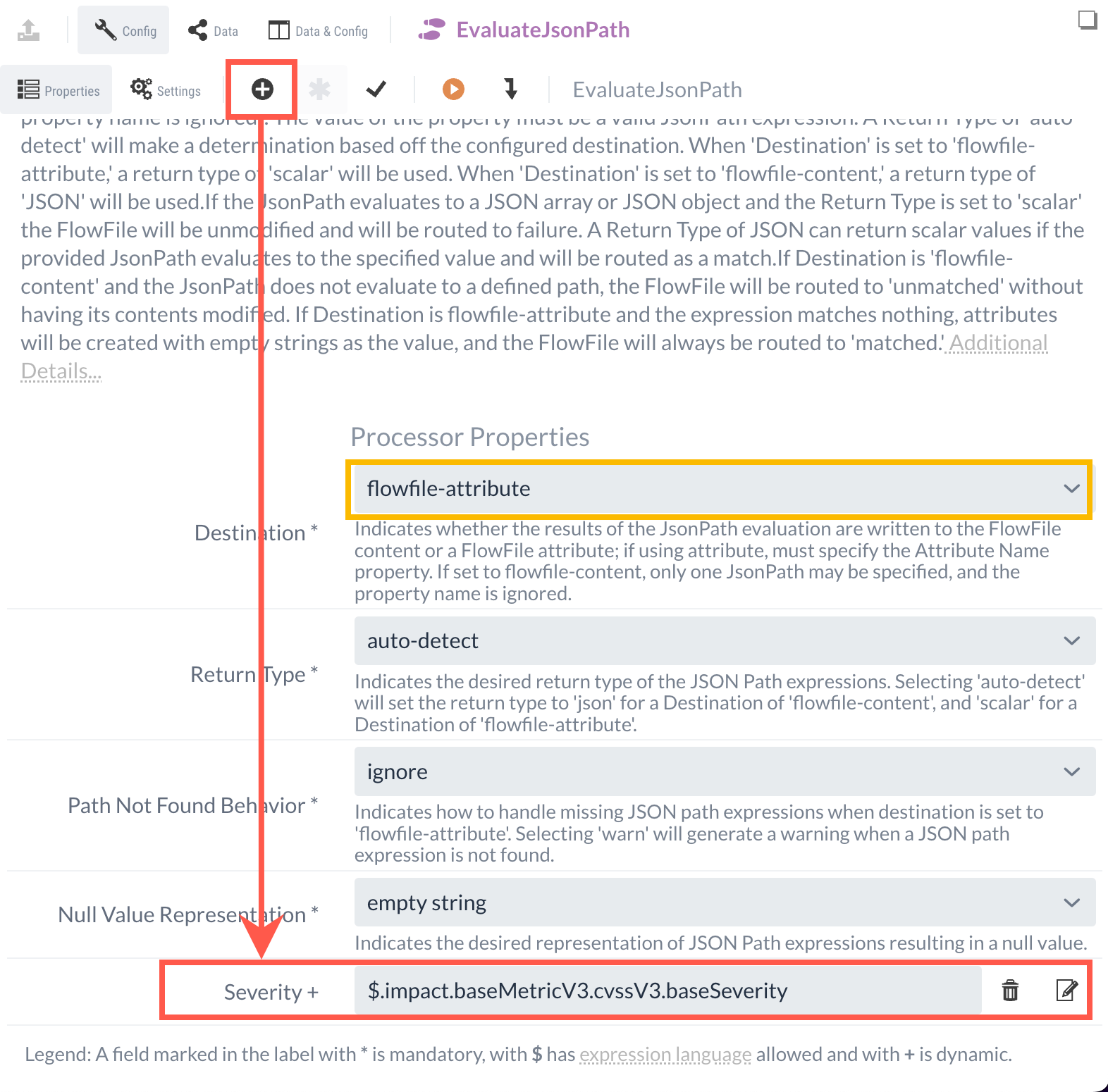
Um eine schnellere Bewertung des Schweregrads der Schwachstellen zu ermöglichen, soll der CVSS V3.X Score als Attribut gespeichert werden.
Um dies zu erreichen, wird unter der Angaben Destination die Option flowfile-attribute ausgewählt.
Über eine neu angelegte dynamische Property kann dann der Name des Attributes und der Inhalt definiert werden.
Als Name wird in diesem Tutorial Severity ausgewählt und der Inhalt ist die JSONPath-Abfrage auf die CVSS V3.X Bewertung, die mit dem folgenden JSONPath abgerufen werden kann:
$.cve.metrics.cvssMetricV31[0].cvssData.baseSeverity.
Mit der vollständigen Konfiguration wird nun in jedem FlowFile das Attribut Severity erstellt, in dem die Bewertung der jeweiligen Schwachstelle eingetragen werden.
Als Relation für die weitere Verarbeitung wird im Anschluss matched ausgewählt, da die Daten weitergeleitet werden sollen, die eine Information in der angegebenen JSON-Struktur beinhalten.
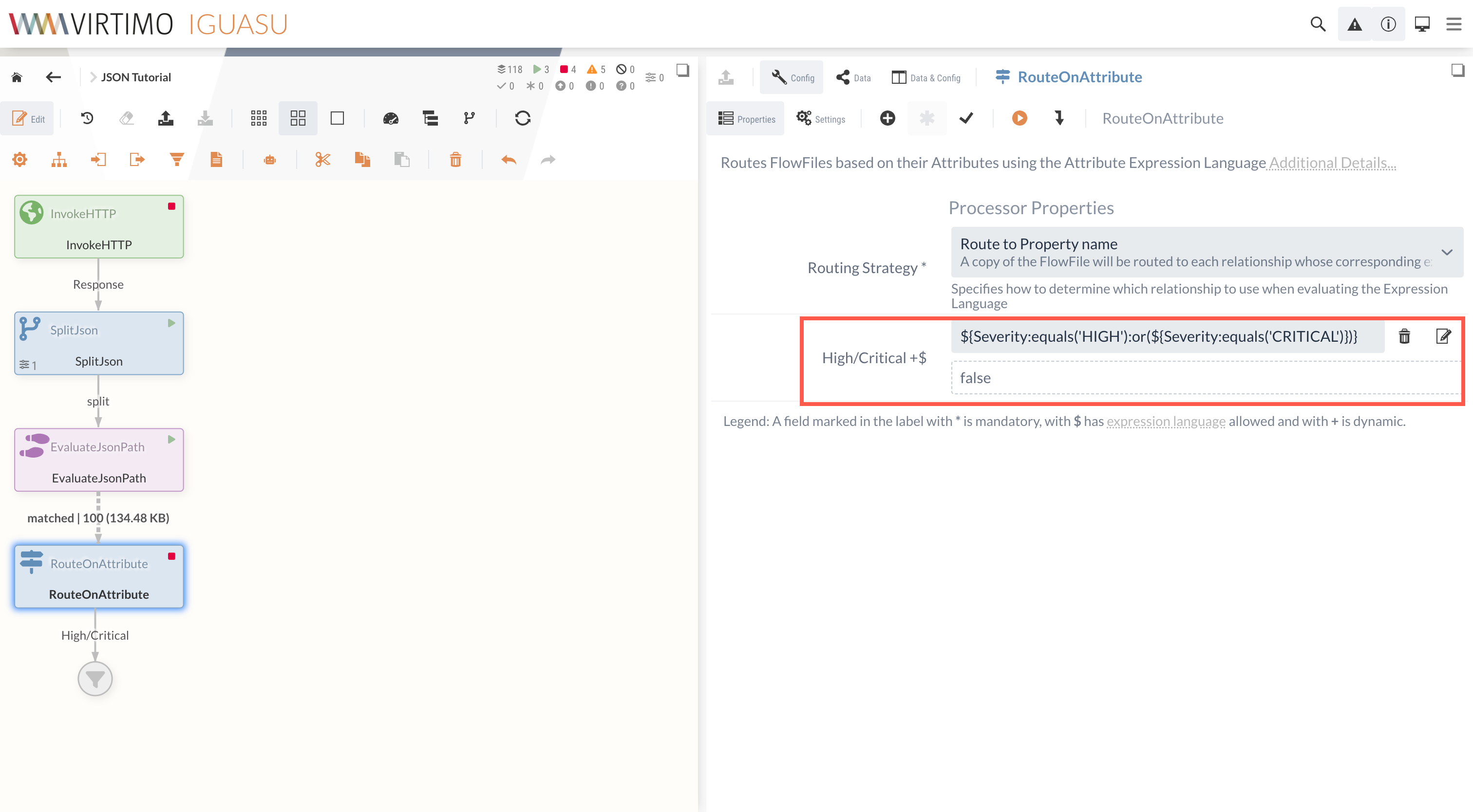
2.2 RouteOnAttribute
Das neu angelegte Attribut kann im Anschluss genutzt werden, um die Schwachstellen mit einer hohen oder kritischen Bewertung herauszufiltern. Für diesen Zweck kann der RouteOnAttribute-Processor genutzt werden, durch den das Routen von FlowFiles ermöglicht wird.
|
Der RouteOnAttribute-Processor ist ein formatunabhängiger Processor und kann ebenfalls für andere Datenformate wie beispielsweise XML- oder CSV-Daten genutzt werden. |
Die Routing Strategy kann hier standardmäßig bei Route to Property name belassen werden.
Ähnlich wie beim EvaluateJsonPath-Processor wird über eine dynamische Property eine Abfrage durch die NiFi Expression Language durchgeführt.
Somit kann die Schwachstellen-Bewertung überprüft werden.
Im Rahmen des Tutorials wird High/Critical als Property-Name ausgewählt.
Durch die Abfrage ${Severity:equals('HIGH'):or(${Severity:equals('CRITICAL')})} kann nach den entsprechenden Schwachstellen gefiltert und zugewiesen werden.
Die dadurch vorhandene High/Critical-Relation kann im Anschluss genutzt werden, um die gefilterten Schwachstellen an den nächsten Processor weiterzuleiten.
|
Da es sich um aktuelle und echte Schwachstellen handelt, kann es passieren, dass keine Schwachstellen mit hohem oder kritischen Schweregrad vorhanden sind.
In diesen Fällen sollte |
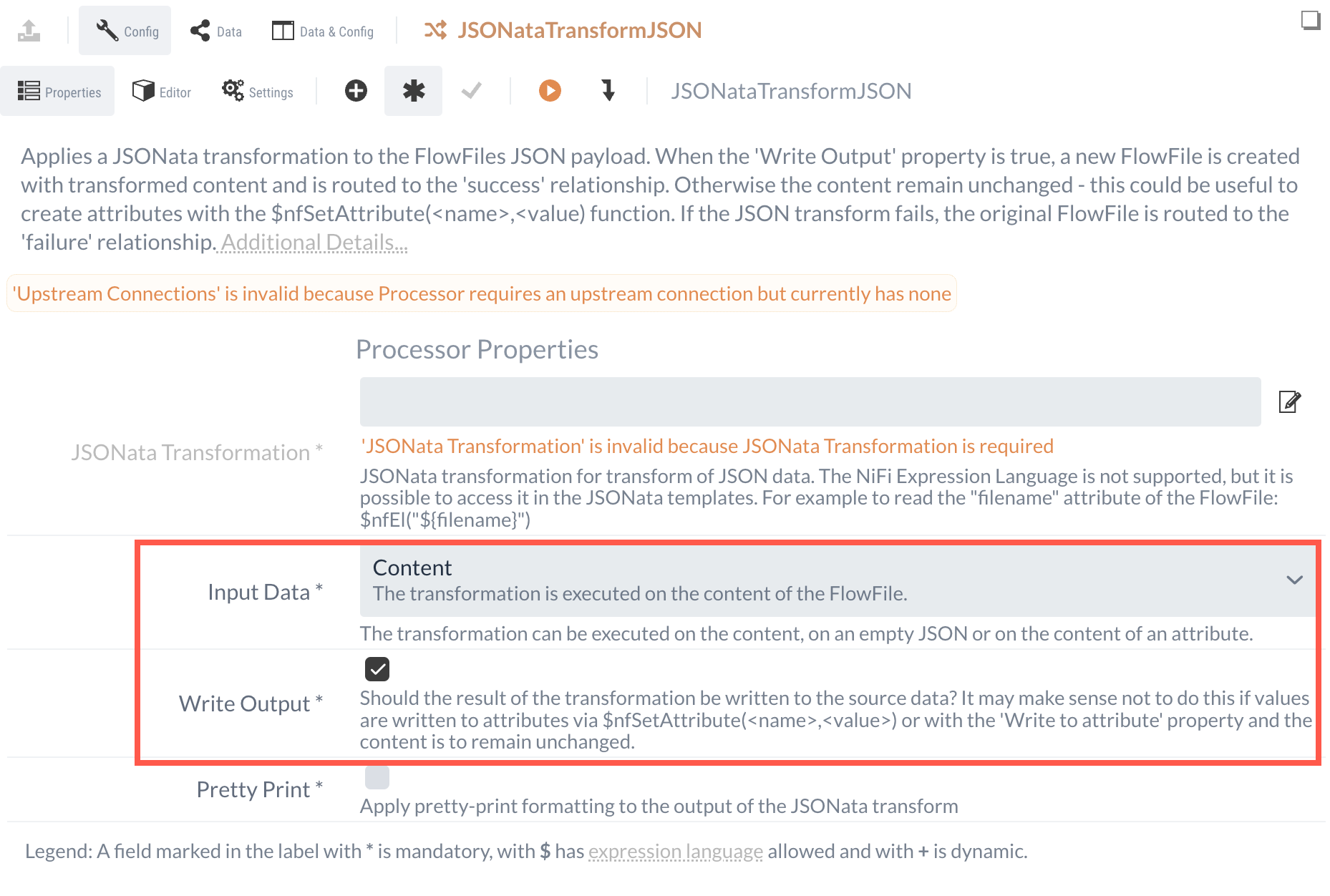
2.3 JSONataTransformJSON
In einem letzten Verarbeitungsschritt sollen die vorhandenen Daten umstrukturiert werden, da viele der vorhandenen Informationen nicht benötigt werden. Für diesen Zweck kann der JSONataTransformJSON-Processor genutzt werden.
Bei der Konfiguration des Processors kann ausgewählt werden, welche Daten umstrukturiert werden sollen.
Zur Auswahl stehen hierbei die FlowFile Attribute, der Content und eine leere JSON-Struktur.
Da es in diesem Fall auf den Content ausgeführt werden soll, muss als Input Data Content ausgewählt werden.
Zusätzlich muss ein Haken bei dem Property Write Output gesetzt sein, damit die Ergebnisse ebenfalls im Content abgespeichert werden.
Um die Struktur anzupassen, kann der Editor genutzt werden.
In diesem Abschnitt kann die Umstrukturierung umgesetzt werden, wobei zusätzlich verschiedene Funktionen zur Verfügung stehen.
Beispielsweise kann mit der Funktion $nfGetAttribute("filename") auf das Attribut filename des FlowFiles zugegriffen werden.
Angaben des Eingangs-FlowFiles können auf ähnliche Weise neu zugewiesen werden, indem der Pfad der gewünschten Informationen eingetragen wird und dadurch einem neuen Schlüssel zugeordnet werden kann.
Im Folgenden ist eine solche Umstrukturierung ersichtlich, indem die FlowFile Dateinamen als ID genutzt werden und einige der relevanten Informationen einer Schwachstelle neu zugewiesen werden:
{
"ID": $nfGetAttribute("filename"),
"CVEID": cve.id,
"Severity": $nfGetAttribute("Severity"),
"Published": cve.published,
"Modified": cve.lastModified
}Eine umfangreiche Beschreibung des JSONataTransformJSON-Processors und weitere mögliche Funktionen befinden sich zusätzlich unter JSONataTransformJSON.
Nach der fertigen Konfiguration werden mit dem Datenfluss nun neue JSON-Dateien generiert, in denen nur noch die essenziellen Informationen enthalten sind. Nach einer Benennung der einzelnen Processors sieht der Flow wie folgt aus:
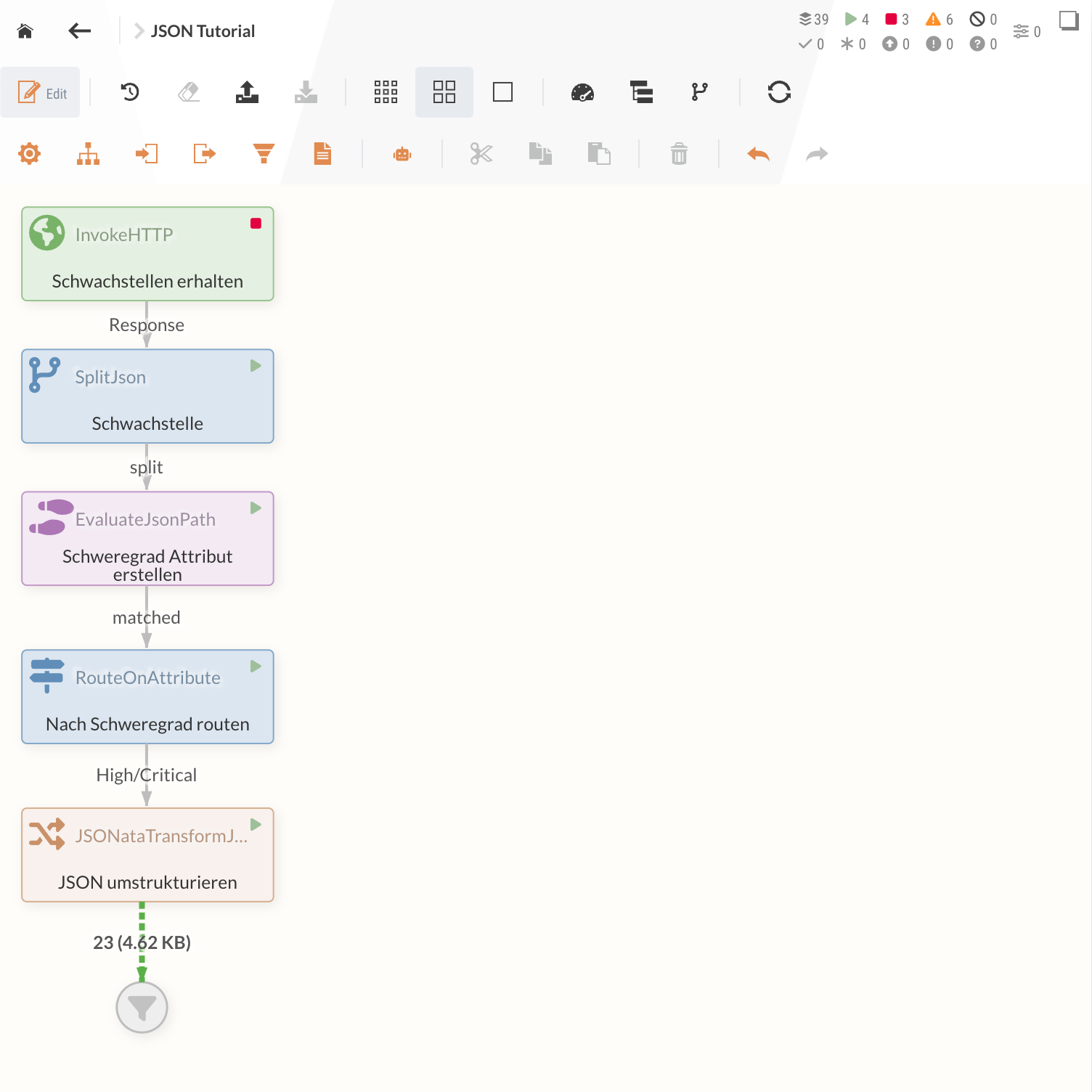
Diese Daten könnten nun genutzt werden, um Datenbank-Einträge zu erstellen oder andere Services zu benutzen.
Teil 3: Record-orientierte Verarbeitung von JSON-Daten
Zusätzlich zu der zuvor gezeigten Vorgehensweise bietet IGUASU die Möglichkeit, Record-orientierte Daten vereinfacht zu verarbeiten, also die Zusammenstellung von distinkten Einheiten. Da nicht nur JSON-Daten eine Record-orientierte Struktur ermöglicht, können die Processors ebenfalls für andere Formate wie beispielsweise XML, CSV oder ähnliche Formate genutzt werden.
Da in diesem Beispiel einzelne Schwachstellen als Records gesehen werden können, bietet sich die Record-orientierte Verarbeitung der JSON-Daten an. Die in Teil 2 veranschaulichten Funktionalitäten, um mit JSON-Daten zu arbeiten, sind dennoch essenziell für den Umgang mit komplexen JSON-Strukturen und können nicht gänzlich durch Record-Processors ersetzt werden.
In diesem Beispiel können allerdings einige der zuvor gezeigten Zwischenschritte innerhalb des QueryRecord-Processors zusammengefasst werden, wodurch die Record-orientierte Verarbeitung in diesem Fall eine performantere Leistung verspricht.
3.1 QueryRecord
Bei der Konfiguration des Processors müssen einige Punkte beachtet werden, die im Folgenden beschrieben sind. Wie bereits in Abschnitt 1.2 beschrieben, befinden sich die Schwachstellen in einem Array innerhalb der Datenstruktur.
Für die Verarbeitung von mehreren Records ist es daher wichtig, an dieser Stelle bereits einzusteigen - was über einen JSONTreeReader-Service gewährleistet werden kann.
Als Starting Field Strategy kann hierbei definiert werden, an welchem Datenpunkt das Lesen eingeleitet werden soll.
Da sich die gewünschten Daten im Array unter vulnerabilities befinden, kann das als Eingabe eingetragen werden.
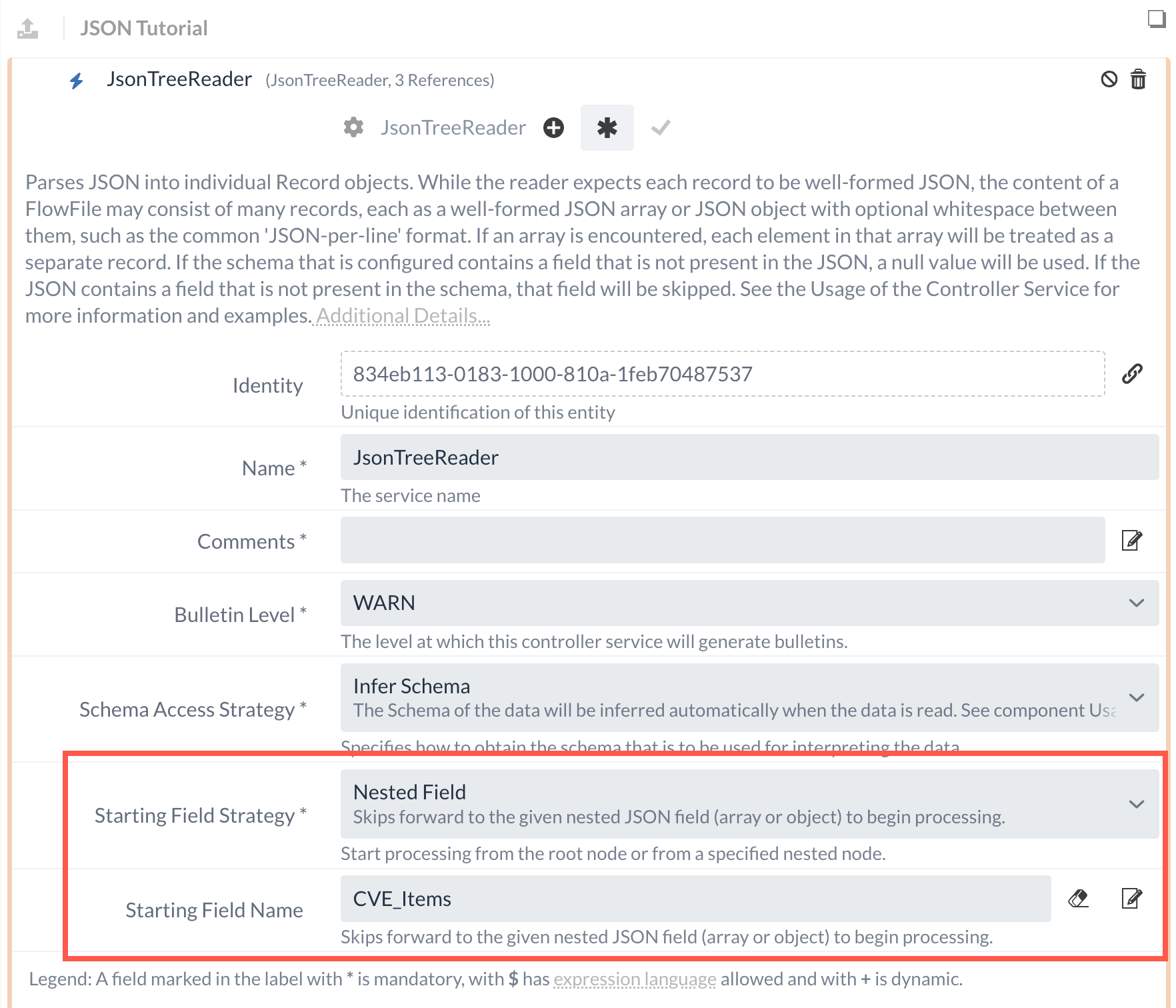
Der konfigurierte JSONTreeReader-Service kann im Anschluss als Reader im QueryRecords-Processor festgelegt werden.
Zusätzlich benötigt der Processor einen Writer, für den ein JSONRecordSetWriter-Service erstellt werden muss. Hierbei können die Standardeinstellungen behalten und der Service kann im Processor ausgewählt werden.
Somit ist gewährleistet, dass die Record-orientierten Schwachstellen gelesen und ebenfalls als JSON-Output generiert werden können. Zusätzlich soll allerdings, ähnlich wie in Teil 2, ein Filtern basierend auf dem Schweregrad erfolgen.
Für diesen Zweck kann eine dynamische Property erstellt werden, über die eine Abfrage erfolgen kann.
Da die Abfragen über SQL-Statements erfolgen und SQL ursprünglich für flache und nicht für hierarchische Datenstrukturen entwickelt wurde, muss bei JSON-Daten oftmals mit RPATH (Record Path) gearbeitet werden.
Um in diesem Beispiel die gewünschte Bewertung des Schweregrads zu erfahren, kann daher die folgende Abfrage getätigt werden:
SELECT *
FROM FLOWFILE
WHERE RPATH(cve, '/metrics/cvssMetricV31[0]/cvssData/baseScore') > 6.9Weitere Angaben und Beispiele zur Verwendung von RPATH befinden sich in der NiFi Dokumentation.
Die abgeschlossene Konfiguration sieht wie folgt aus:
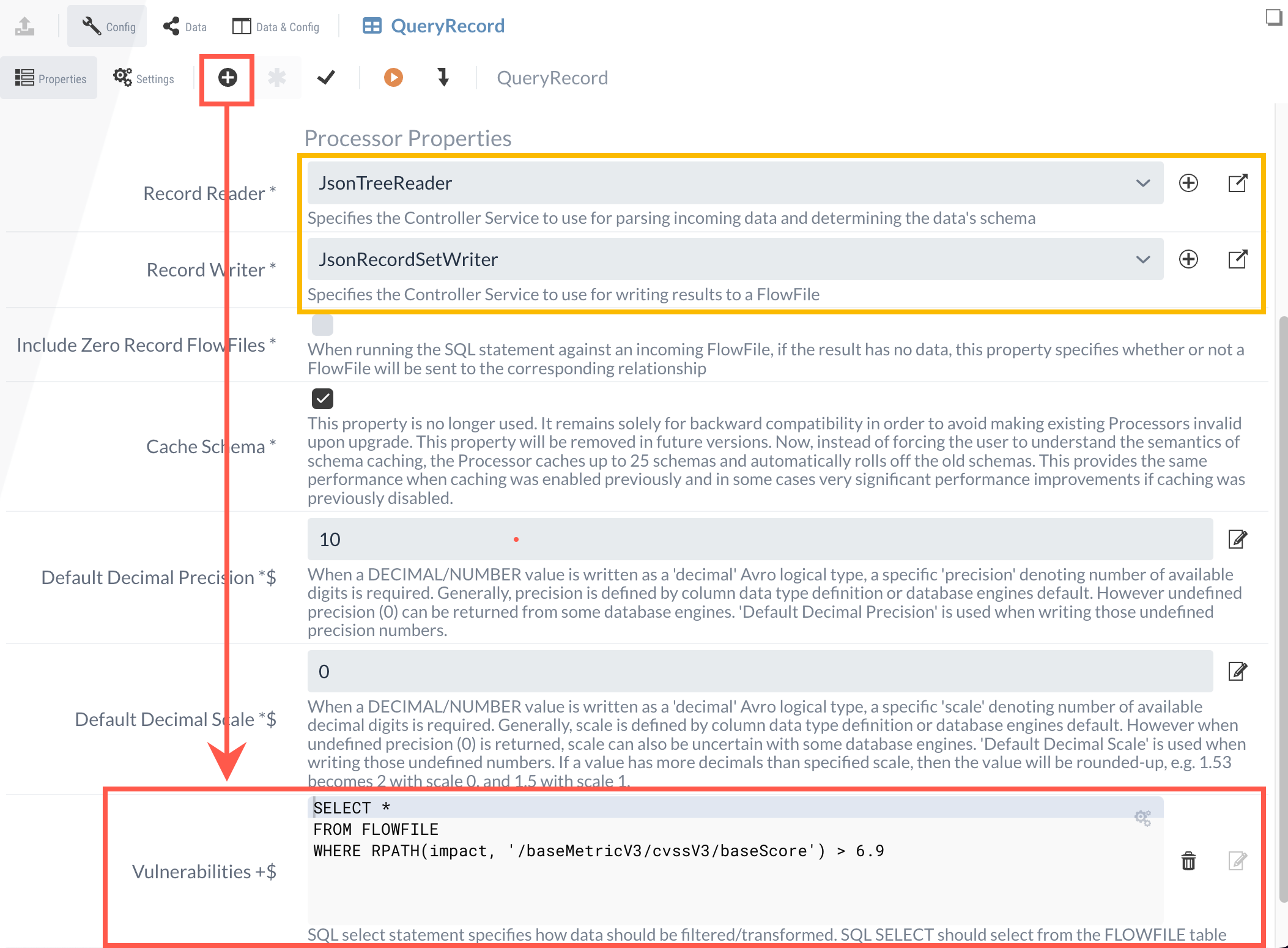
Durch den QueryRecord-Processor werden nun die Schwachstellen ermittelt, die entweder einen hohe oder eine kritische Bewertung erhalten haben.
Als letzter Schritt muss allerdings ähnlich wie in Abschnitt 2.3 eine Umstrukturierung erfolgen. Für diesen Zweck kann erneut der JSONataTransformJSON-Processor genutzt werden.
An dieser Stelle wäre es möglich, die einzelnen Records als einzelnen Array weiterzuverarbeiten und den JSONataTransformJSON-Processor zu verwenden, um die einzelnen Schwachstellen innerhalb des Arrays anzupassen.
Dies wäre durch folgende JSON-Struktur zur Transformation der Schwachstellen-Daten erreichbar, in dem die einzelnen Schwachstellen in einem Array unter entries zusammengefasst werden:
{
"entries": [*.
{
"ID": $nfGetAttribute("filename"),
"CVEID": cve.id,
"Severity": $nfGetAttribute("Severity"),
"Published": cve.published,
"Modified": cve.lastModified
}
]
}Um eine bessere Vergleichbarkeit zu dem ursprünglichen Datenfluss zu gewährleisten, sollen die einzelnen Records allerdings erneut in individuelle FlowFiles integriert werden.
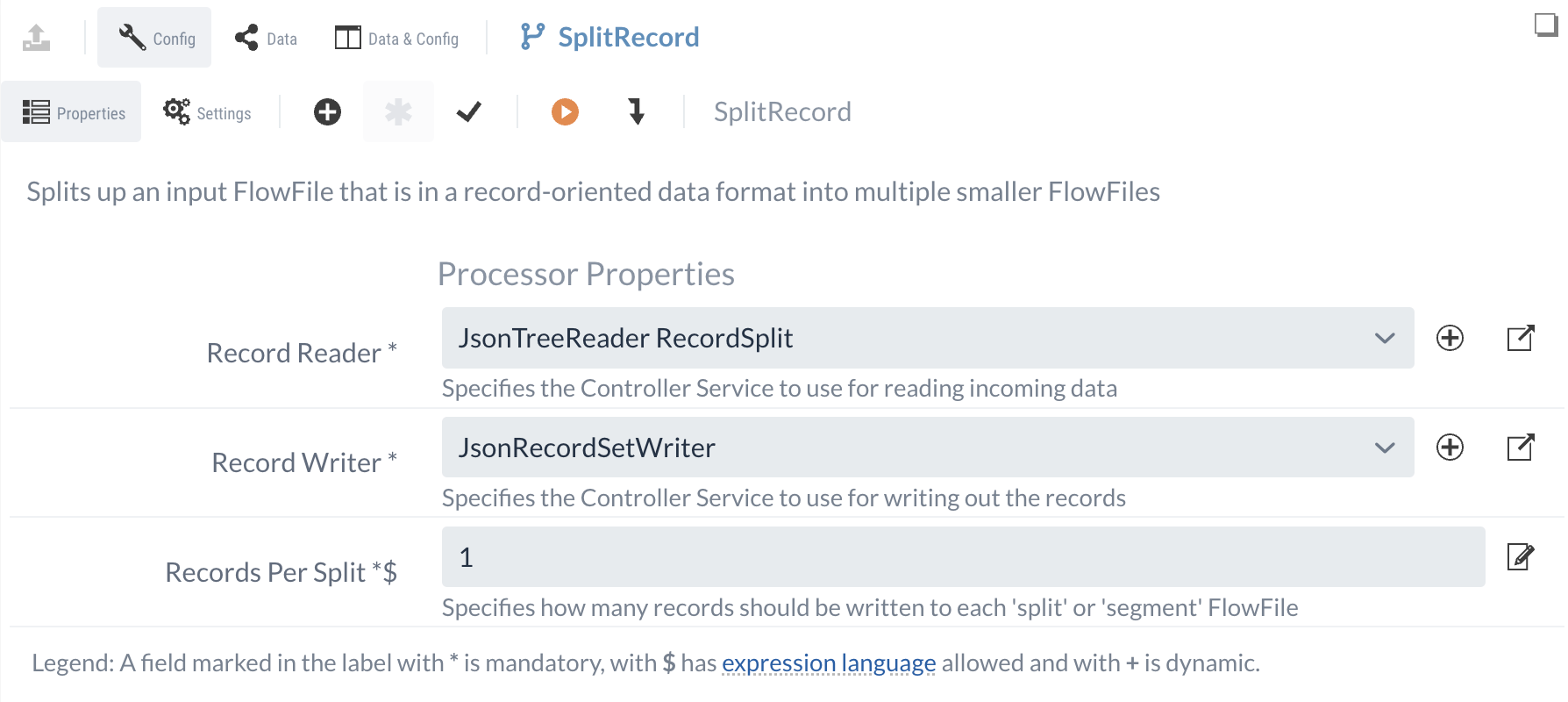
3.2 SplitRecord
Zum Aufteilen von Records beliebiger Formate kann der SplitRecord-Processor verwendet werden. Anders als mit den zuvor verwendeten SplitJSON-Processor können durch den Einsatz von Services zum Lesen und Schreiben von FlowFiles beliebige Formate aufgeteilt werden, wodurch dieser Processor universeller eingesetzt werden kann. Ähnlich wie zuvor bei dem QueryRecord-Processor müssen für die Konfiguration der Reader und der Writer definiert werden.
In diesem Fall kann der ursprünglich erstellte Writer übernommen werden, da die Funktionalität an dieser Stelle ebenfalls passend ist.
Als Reader muss allerdings ein neuer definiert werden, da bei dem zuvor konfigurierten Service der Starting Field Name definiert wurde, der an dieser Stelle nicht mehr vorhanden ist.
Ähnlich wie im letzten Abschnitt wird daher ein neuer JsonTreeReader-Service generiert, wobei diesmal keine weiteren Anpassungen notwendig sind.
Es sollte nur darauf geachtet werden, dass zur besseren Unterscheidung ein anderer Name für den Service gewählt wird.
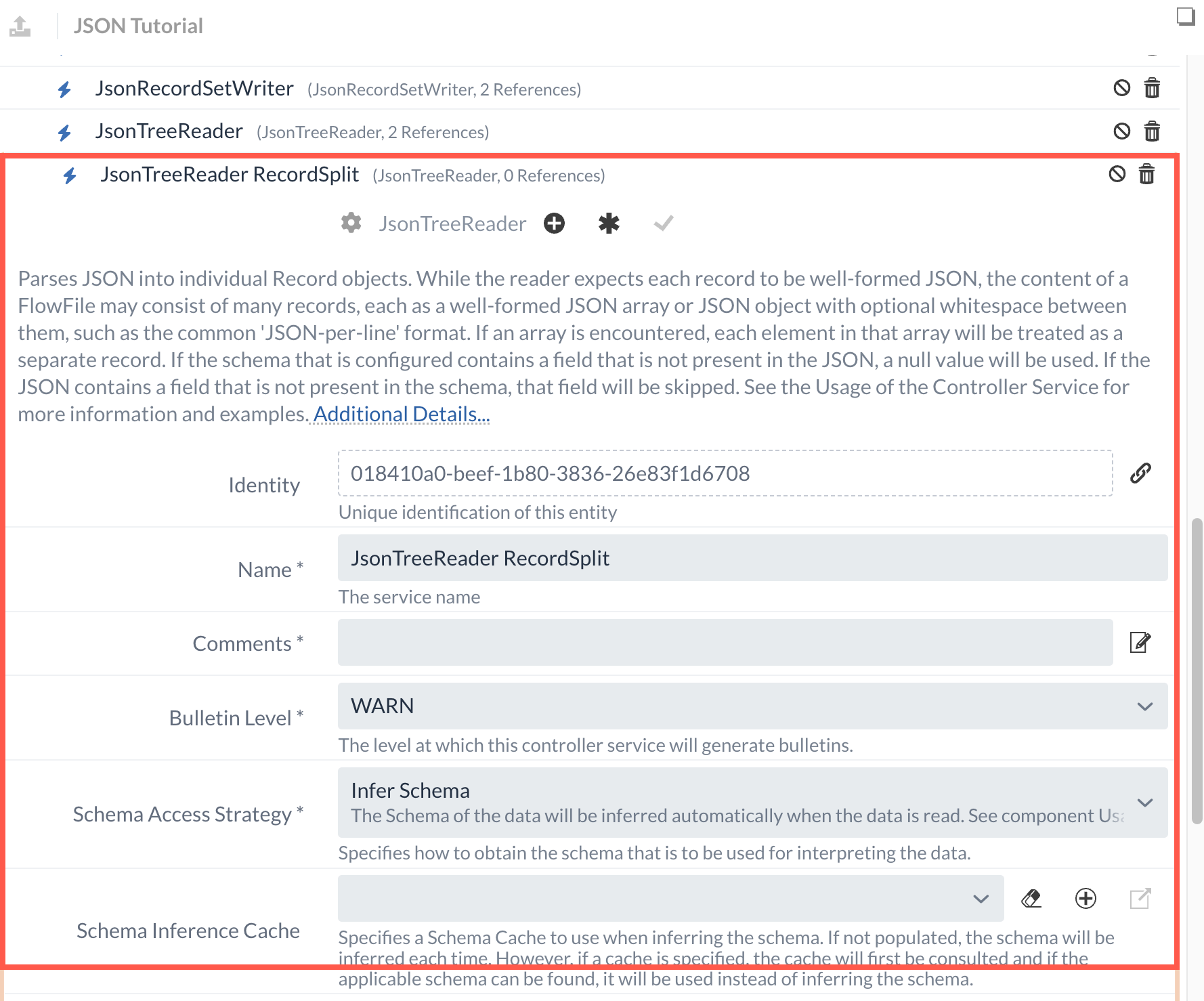
Zusätzlich zum Reader und Writer kann im SplitRecord-Processor konfiguriert werden, wie viele Records pro aufgeteiltem FlowFile enthalten sein sollen.
Da in jedem FlowFile eine Schwachstelle enthalten sein soll, kann an dieser stelle 1 eingetragen werden.
Damit ist die Konfiguration des Processors abgeschlossen und sollte wie in der folgenden Abbildung aussehen.
Da die einzelnen FlowFiles eine ähnliche Struktur aufweisen wie im ersten Datenfluss, können die Daten im Anschluss erneut an den JSONataTransformJson-Processor weitergeleitet werden, wodurch sie erneut umstrukturiert werden.
|
In diesem Fall erfüllen beide Datenflüsse, die vom InvokeHTTP-Processor ausgehen, dieselbe Funktion. Um zu verhindern, dass die Ergebnisse am Ende doppelt vorhanden sind, sollte das Durchlaufen der Daten an einem der beiden Abschnitte gestoppt werden. |
An dieser Stelle des Flows sind die Daten zu vorhandenen Schwachstellen in der gewünschten Form vorhanden. Um sicherzustellen, dass die enthaltenen Informationen ebenfalls den eigenen Vorstellungen entsprechen, kann eine entsprechende Validierung durchgeführt werden.
Teil 4: Validierung von JSON-Daten
Zur Validierung von JSON-Daten kann der ValidateJson-Processor verwendet werden.
Mit diesem Processor werden Schemata festgelegt, durch die eine gewünschte Struktur für die Daten definiert werden kann.
Dadurch wird ermöglicht, dass das JSON-Datenformat sicher und zuverlässig eingesetzt werden kann.
Zur Konfiguration dieses Processors muss für diesen Zweck die deklarative Programmiersprache genutzt werden, um ein Schema zu spezifizieren. Die Standards für die Erstellung eines Schemas mit den Spezifikationen und den unterschiedlichen Versionen können unter JSON-Schema angesehen werden. Im Rahmen dieses Tutorials ist es zunächst ausreichend, ein simples Schema für die vorhandenen FlowFiles zu erstellen, um die Funktionsweise des Processors zu veranschaulichen.
Im Allgemeinen werden beim Aufbau des Schemas zunächst allgemeine Informationen definiert wie beispielsweise ein Titel und eine Beschreibung des Typs der JSON-Dateien, die durch das Schema validiert werden soll. Unter dem Punkt "Properties" können im Anschluss einzelne Keys beschrieben werden, die in der JSON-Datei vorkommen und wie diese aussehen sollen. Zusätzlich können individuelle Restriktionen definiert werden, wobei im Rahmen des Tutorials nur Pflichtfelder unter dem Punkt "required" festgelegt werden sollen.
Ein Schema zur Validierung von den zuvor generierten Daten könnte beispielsweise wie folgt aussehen:
{
"title": "Vulnerability",
"description": "An identified vulnerability with severity score high or critical",
"type": "object",
"properties": {
"ID": {
"description": "General ID of the request",
"type": "string"
},
"CVEID": {
"description": "ID of the vulnerability",
"type": "string"
},
"Severity": {
"description": "Severity of the vulnerability",
"type": "string"
},
"Published": {
"description": "The date on which the vulnerability was published",
"type": "string"
},
"Modified": {
"description": "The date on which the vulnerability was last modified",
"type": "string"
}
},
"required": [
"CVEID",
"Severity",
"Published"
]
}Mit diesem simplen Schema wird festgelegt, dass alle vorhandenen Daten als Zeichenkette (String) vorliegen müssen und dass CVEID, Severity und PublishedDate Pflichtfelder sind.
Dieses Schema wird im Anschluss im ValidateJson-Processor unter JSON Schema eingetragen und als Schema Version kann der Standardwert Draft 2020-12 unverändert gelassen werden.
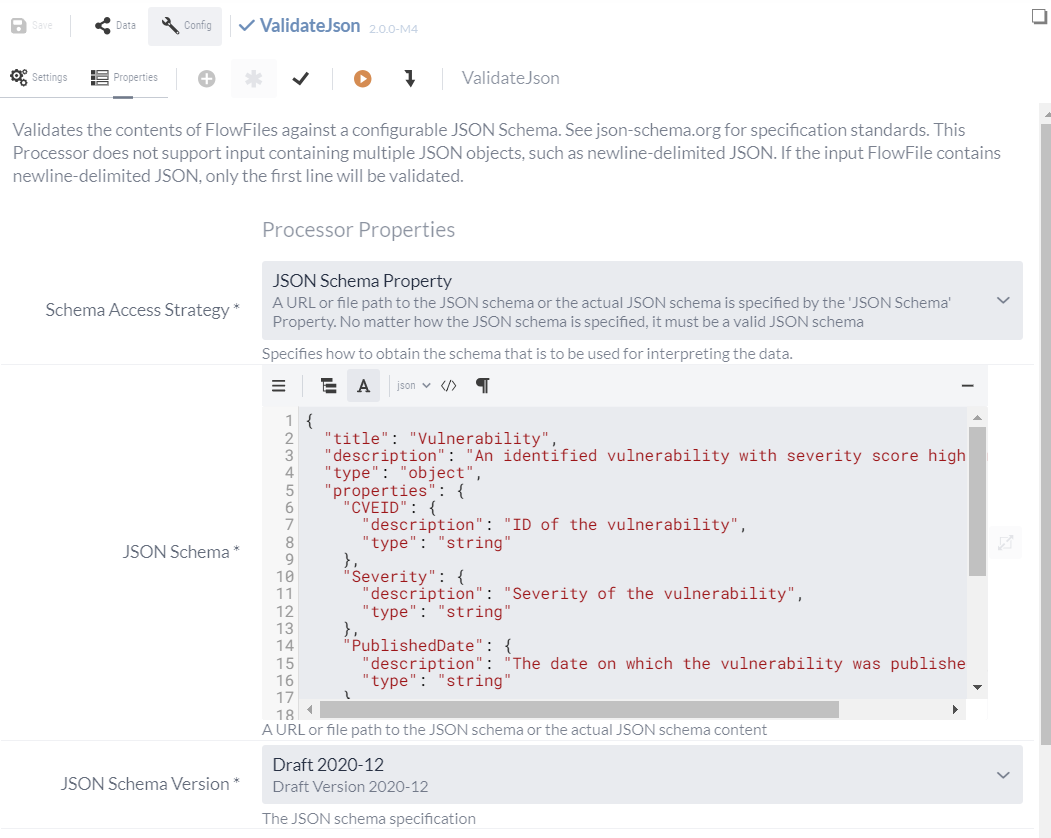
Mit den Anpassungen ist der Processor bereits konfiguriert und muss noch an den vorhandenen Datenfluss integriert werden. Dazu wird die Success-Relation des JSONataTransformJSON-Processors zum Processor gezogen und es müssen noch die Ergebnisse geroutet werden. Im ValidateJson-Processor steht hierbei die valid-, invalid und failure-Relationen zur Verfügung. Diese Verbindungen können an individuelle Funnel geroutet werden, um die Ergebnisse im Datenfluss anzuzeigen.
Dadurch ist das Tutorial zur Verarbeitung von JSON-Dateien abgeschlossen.
In diesem Tutorial wurden unterschiedliche Verarbeitungsmöglichkeiten gezeigt, mit denen man JSON-Strukturen anpassen, verarbeiten und validieren kann.