Selected Processors
This section contains some selected Processors that have special properties and are therefore described in more detail.
JSONataTransformJSON
The JSONataTransformJSON Processor is used to transform JSON using a JSONata script.
Queries or transformations can be executed on incoming content in JSON.
The Processor has the following extra functions in IGUASU:
-
$nfUuid()generates a UUID of type 4 (pseudo-random number generator). The UUID is generated with a cryptographically strong pseudo-random number generator. -
Attributes from the input FlowFile can be read/processed (in addition to the input content):
$nfGetAttribute(<name>) -
Results can be written to attributes in addition to or instead of the output content:
$nfSetAttribute(<name>,<value>) -
All attributes from the input FlowFile can be read as an entire object. This is useful, for example, for iterating and filtering over the attributes:
$nfGetAttributes() -
The NiFi Expression Language can be used:
$nfEl(<expression>) -
A lookup service can be used if this has been defined on the Processor:
$nfLookup(<key>)
The JSONataTransformJSON Processor has a specific editor that allows easy editing of the entire script.
|
You can quickly try out your transformation by using the "Test/run" button |
More general information about JSONata:
-
JSONatahttps://docs.jsonata.org/overview.html[documentation]
|
How this Processor implements JSONata transformations is slightly different from try.jsonata.org! |
The advanced functions are now explained in detail.
Simple transformation
Input message (also for the other examples; taken from jsonata.org ):
{
"FirstName": "Fred",
"Surname": "Smith",
"Age": 28,
"Address": {
"Street": "Hursley Park",
"City": "Winchester",
"Postcode": "SO21 2JN"
}
}Converting some of this data to another form of address:
{
"name": FirstName & " " & Surname,
"mobile": Phone[type = "mobile"].number,
"address": Address.City
}Result:
{
"name": "Fred Smith",
"mobile": "077 7700 1234",
"address": "Winchester"
}Write result to attributes
If you want to put the same results in attributes instead of in the source content, you can use the following function:
-
nfSetAttribute(<name>,<value>)
In addition, you can deactivate on the Processor that the result of the script is written to the output:
Write Output |
false |
The content is thus left untouched. This makes sense in this case, as only the attributes are to be created.
The script now looks like this:
$nfSetAttribute("name", FirstName & " " & Surname) &
$nfSetAttribute("mobile", Phone[type = "mobile"].number) &
$nfSetAttribute("city", Address.City)The attributes then appear in the result:
name |
Fred Smith |
mobile |
077 7700 1234 |
city |
Winchester |
There is also a property in the Processor to write the entire result of the transformation to an attribute:
Write to Attribute |
<name of attribute> |
Read Attributes
In the first case, for example, if you want to access the attribute filename to set it as the ID in the result, the script looks like this:
{
"id": $nfGetAttribute("filename"),
"name": FirstName & " " & Surname,
"mobile": Phone[type = "mobile"].number,
"address": Address.City
}If you want to filter across all attributes to get only some with a prefix, you can do this as described here. The prefix 'http.headers.' used here is used by the HandleHttpRequest processor - so you could only operate on the Http header fields:
$nfGetAttributes().$sift(function($v, $k) { $contains($k, 'http.headers.') }).*Using the NiFi Expression Language
If you want to use the NiFi Expression Language within a JSONata, this can be done via the corresponding function nfEl(<expression>).
In the following example, the NiFi Expression Language is used to check with a regular expression whether the name is correct (i.e. only contains corresponding characters).
{
"name": FirstName & " " & Surname,
"isValidName": $nfEl("${literal('" & FirstName & " " & Surname & "'):matches('^[\\p{L} \\p{Nd}_]+$')}"),
"mobile": Phone[type = "mobile"].number,
"address": Address.City
}The function can include any number of name/value pairs in addition to the expression.
These are provided to the Expression Language for execution as temporary attributes.
This means that, unlike $nfSetAttribute(<name>,<value>), they are not set beyond the execution.
This can be used, for example, to provide values from the input for the $nfEl() execution as attributes.
Instead of the literal in the last example, the following could also be written:
{
...
"isValidName": $nfEl("${name:matches('^[\\p{L} \\p{Nd}_]+$')}", "name", FirstName & " " & Surname )
...
}TransformXml
The TransformXml Processor is used to transform XML using an XSLT script.
The Processor has the following special features in IGUASU:
-
The latest version of the Saxon XSLT Processor with XSLT 3.0/XPath 3.1 is supported
-
The licensed Saxon EE incl. its extended features is included. its extended features is included
-
the XSLT script can be saved directly in a property (in addition to the variants of the external file or the lookup service) - this makes it easier to use and deploy
-
the direct processing of JSON by
fn:json-to-xml()orfn:xml-to-json()is facilitated by the possibility of embedding the incoming JSON in an XML root tag -
Result documents (
xsl:result-document) can be used to:-
Create relations/outputs of the module
-
Create attributes in the success/failure output(the name of the href must start with
a:for this)
-
-
Use of the NiFi Expression Language in XPath expressions
-
The namespace
xmlns:nf="http://nifi.org"is declared for this -
The method to be called is called el() - e.g. The TransformXml is declared in the namespace .E.g.
<xsl:value-of select="nf:el('${UUID()}')"/>
-
The TransformXml Processor has a specific editor that allows the entire script to be edited easily.
The functions are explained in detail below.
Use of result documents
Prerequisite:
Support result documents |
true |
In XSLT it looks like this:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0">
<xsl:output method="xml" name="xml" indent="yes"/>
<xsl:output method="text" name="text"/>
<xsl:template match="/">
<xsl:result-document href="relationOne" format="xml">
<resultOne><xsl:copy-of select="/"/></resultOne>
</xsl:result-document>
<xsl:result-document href="relationTwo" format="text">
number of nodes: <xsl:value-of select="count(//*)"/>
</xsl:result-document>
<xsl:result-document href="a:attributeOne" format="text">something</xsl:result-document>
</xsl:template>
</xsl:stylesheet>The results of the result-documents of relationOne and relationTwo are written to the corresponding relations (outputs) of the Processors.
These become available by creating the result-document tags in the script and then saving the script.
The result of result-document from a:attributeOne is written as an attribute in the success/failure relation due to the prefix a:.
NiFi Expression Language
The NiFi Expression Language can be used both when passing Parameters via Dynamic Properties and within XPath expressions.
EL in Parameters
By adding any Dynamic Property (via the button), the content of this property is passed to the XSLT script as a Parameter (xsl:param).
The Expression Language may be used within the value.
This can, for example, also access the attributes of the incoming FlowFile:
testParam |
the filename is ${filename} |
This can then be used in the XSLT:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0">
<xsl:output method="text"/>
<xsl:param name="testParam"/>
<xsl:template match="/">
<xsl:value-of select="$testParam"/>
</xsl:template>
</xsl:stylesheet>As the filename in NiFi is typically a UUID, the result is:
the filename is 8ec0e87a-56dc-425f-b4c5-1de7f515ddea
EL in XPath expressions*
To use the NiFi Expression Language within XPath, this must first be activated using the corresponding property:
Allow NiFi EL in XPath |
true |
The namespace must still be set in the XSLT script (xmlns:nf="http://nifi.org").
The function (nf:el()) can then be called wherever XPath expressions are permitted:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0"
xmlns:nf="http://nifi.org">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:value-of select="nf:el('${UUID()}')"/>
</xsl:template>
</xsl:stylesheet>The result is:
2560fc8c-3581-4732-8862-6bb191eb0dcc
In order to use values from the input within the nf:el() execution, they can still be passed as temporary attributes by taking any number of name/value pairs as arguments.
For example, the author of a book can be read from the input and used as an attribute within a NiFi Expression Language function.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:nf="http://nifi.org" version="3.0">
<xsl:output method="text" />
<xsl:template match="/">
<xsl:value-of select="nf:el('${author:toUpper()}', 'author', /library/book[1]/author)" />
</xsl:template>
</xsl:stylesheet>JSON processing
To be able to read JSON directly, the corresponding property must be set:
Surround input with <xml> tag |
true |
This turns the incoming JSON into an XML, to which the XPath 3.0 function can then be applied:
Input JSON:
{
"name": "Harry",
"age": 23,
"address": {
"city": "London"
}
}XSLT script:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fn="http://www.w3.org/2005/xpath-functions"
exclude-result-prefixes="fn" version="3.0">
<xsl:output indent="yes"/>
<xsl:template match="/">
<xsl:copy-of select="fn:json-to-xml(.)"/>
</xsl:template>
</xsl:stylesheet>Result:
<map xmlns="http://www.w3.org/2005/xpath-functions">
<string key="name">Harry</string>
<number key="age">23</number>
<map key="address">
<string key="city">London</string>
</map>
</map>To turn such an XML structure back into JSON, you can use fn:xml-to-json().
ListenBPCFlowStarter
The ListenBPCFlowStarter Processor enables the seamless linking of IGUASU with a Virtimo Business Process Center instance. Here, the BPC Services in IGUASU mentioned at the beginning are used to establish a connection based on the configurations. The ListenBPCFlowStarter then acts as the listener and starting point of a flow to which the data and input of the BPC user is transferred.
The Processor has the following special features in IGUASU:
-
The selected BPC Listener Base Path is displayed as an ID in the BPC under the IGUASU settings.
-
For better differentiation of the stored ListenBPCFlowStarter Processors, the
Flow Starter NameandFlow Starter Desc.are also displayed in the BPC. -
By using different HybridRESTServerController Services, the ListenBPCFlowStarter Processors in the BPC can be grouped into different components.
Further information on connecting IGAUSU and BPC can be found in the BPC connection tutorial.
PutBPCProcessLog
The PutBPCProcessLog processor enables the creation of BPC Process Logs, which are transmitted from the IGUASU Processor to the desired BPC instance.
For this purpose, a BPC Controller, which contains the BPC URL and the created API key, and the desired BPC Logger must be selected.
You also have the option of changing the Input Type to determine whether the content of the FlowFile or the file in the BPC Entries JSON property should be logged.
This is the format of the expected LOG data:
{
"entries": [
{
"parent": {
"process-id": "448f1867-b4ef-4fb8-9db6-cf0f26acc384",
...
},
"children": [
{
"process-id": "448f1867-b4ef-4fb8-9db6-cf0f26acc384",
"child-id": "a18b56f8-5312-3c81-779d-4c08bd4ee29f",
...
}
]
}
]
}| In BPC version 5.0, the array where the child entries are expected was renamed from "children" to "children". If your BPC is older than version 5.0, you should therefore use "childs" instead of "children". |
The Processor has the following special features in IGUASU:
-
The loggers that were previously created in the BPC are stored in the selection options of the
Choose BPC Loggerproperty. If the BPC instance cannot be reached, the ID of the logger can also be specified.
Further information on connecting IGAUSU and BPC can be found in the BPC connection tutorial and in the BPC documentation.
PutBPCAuditLog
The PutBPCAuditLog Processor is used to write data to the BPC audit log. The BPC audit level, audit originator and action can be selected for configuration. The HybridRESTClientController Service is used to link the IGUASU flow with a BPC instance, in which the BPC URL and the generated BPC API key are stored.
The Processor has the following special features in IGUASU:
-
The NiFi Expression Language can be used to read the required log information from the FlowFiles.
Further information on connecting IGAUSU and BPC can be found in the BPC connection tutorial and in the BPC documentation.
Metro-Processors
Metro-Processors open up the basic possibility of routing FlowFiles directly from one Processor (PutMetro) to another (GetMetro/ExitMetro) without having to connect them to a Connection. This opens up completely new possibilities for implementation in various scenarios. These different scenarios are described here:
Accessing a FlowFile from an earlier step in the flow (GetMetro)
It is often necessary to need a FlowFile from an earlier processing step again later. However, only the FlowFile that resulted from the last processing step is available.
To solve this problem, there are also the following options, which are first presented here with their disadvantages before we show the Metro solution:
Existing solution approaches
-
Write data to attributes, which are then dragged along until they are used
-
Attributes should not contain large amounts of data
-
You have to convert the data to attributes and then possibly write it back to the content if the Processor used requires this
-
Attributes are always passed along to each Processor and potentially processed
-
-
Create a bypass - e.g.B. with ForkEnrichment/JoinEnrichment or MergeContent
-
This is primarily intended for enriching structured content such as JSON
-
The structure is therefore then different and you potentially have to transform it again
-
The Diagram is bloated and you have to draw a connection from the original occurrence to the use, which can be much later
-
-
Storage in a third-party system
-
You need a third-party system
-
You have to take care of the cleanup yourself or make sure that the data is trans be sure that the data is available in the same transactional form as in the flow itself
-
Makes deployments/staging more difficult
-
Solution with PutMetro/GetMetro
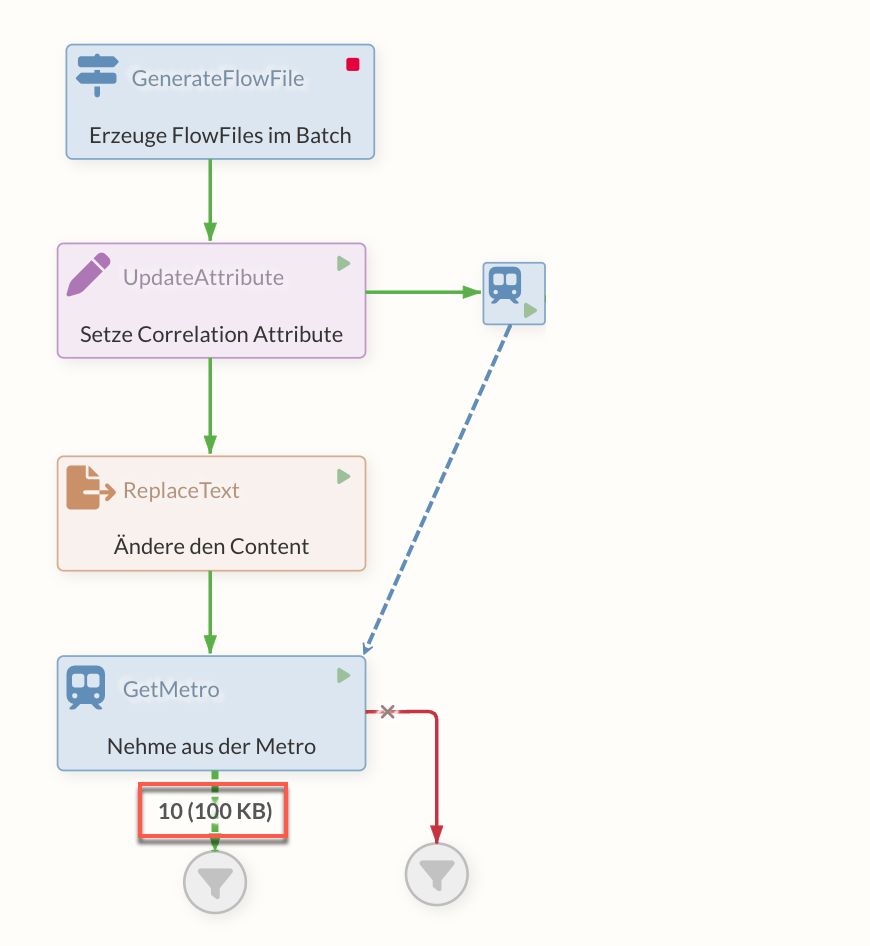
The FlowFile, which is needed later, is written to the queue before a PutMetro Processor in addition to normal processing. This Processor has a MetroLineController Service, which it shares with the later GetMetro Processor - this creates the subway path between these Processors, so to speak, which is not directly visible in the Diagram.
If the original FlowFile now comes to the GetMetro Processor, it asks the PutMetro Processor connected to the Service for a FlowFile in its queue that has the same value of an attribute as the original FlowFile. This is the relevant configuration on the GetMetro - the name of the correlation attribute from which this correlation can be established.
The FlowFile that is located before the PutMetro Processor now comes out at the output of the GetMetro Processor. Here it is taken out of the queue (and also into the success relation of the PutMetro, if this should have a connection).
|
If the cached FlowFiles have already been retrieved by a GetMetro Processor, they are no longer available. This can result in errors during further access attempts. |
Dynamic properties can be set on the Processors, which are then added as attributes to the FlowFiles.
Advantages of this solution
-
The Diagram remains clear
-
No external systems are required
-
Everything is solved with Flow means
-
The transactionality remains - the FlowFile before the PutMetro is only removed, when the FlowFile has been passed on by the GetMetro
-
The processing speed is high
-
Limits of Process Groups can be overcome
Disadvantages of the solution
-
Compared to a bypass, you cannot see the connection directly when you look at the diagram
-
Limits of Process Groups can be overcome .. this is not only an advantage, but also a disadvantage if using them leads to confusing flows. This should be considered.
Calling another flow (ExitMetro)
If I want to call another flow at many points in a flow, there are the following options with their disadvantages:
-
Modeling via a (versioned) Process Group, which is always directly integrated at the points
-
Relatively complex to model and maintain
-
Each sub-process group is its own instance and has, for example also has its own queues and sequences → therefore not really ONE other flow is called, but many of the same
-
-
Call via external options, e.g. HTTP/REST
-
An external protocol is used, which is potentially slow and requires authentication
-
The transfer of content+attributes must be taken into account
-
The flow engine is abandoned
-
Provenance is more difficult to track
-
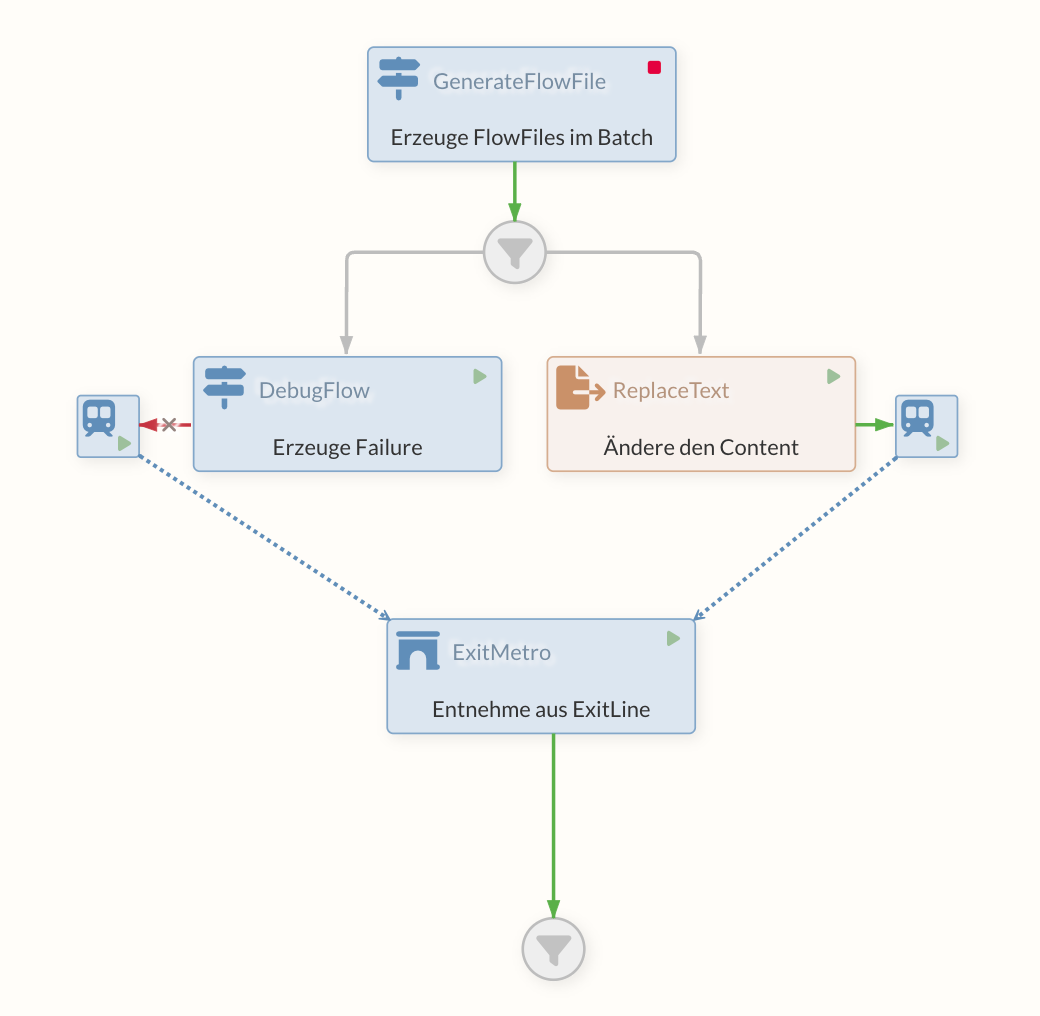
Solution with PutMetro/ExitMetro
A "subway" is created via the PutMetro and an ExitMetro connected via the MetroService. Many PutMetros can also refer to one ExitMetro. As soon as a FlowFile goes into the PutMetro, it is routed directly to the ExitMetro and comes out of the "success" relation there.
Attributes can still be set on the PutMetro via Dynamic Properties.
A typical use case for this construct is, for example, process logging in an external system such as the Business Process Center. At various points in the flow, you want to log data (from attributes and/or the content) uniformly to the BPC in order to record the status of the higher-level business process. In this example, there is a Processor behind the ExitMetro that writes the status to the BPC.
How-To
A further application example of the Processors described can also be found in the How-Tos section under Metro.
Merge-Processors
Different Processors are available to merge independent or previously separated FlowFiles.
Depending on the Processor, different strategies and formats are offered, which can be customized according to individual requirements. This section provides an overview of some Processors that can be used to merge FlowFiles
MergeContent and MergeRecord
The two Processors MergeContent and MergeRecord have many setting options that can be used to merge FlowFiles. Many of the options are available in both Processors, although there are small differences. For example, a Reader and a Writer can also be defined by the MergeRecord Processor for record-oriented processing, which could also result in a conversion during merging. The configuration options and how the options work are described below:
-
Merge Strategy
The Merge Strategy can be used to define the criteria according to which the FlowFiles are to be combined. Two different procedures are available that can be selected for this purpose.-
Bin-Packing Algorithm
The Bin-Packing Algorithm is the strategy that is initially selected by default. Here, FlowFiles are collected in individual containers (bins) until the defined threshold values are reached. The parameterMinimum Number of Entriescan be used to define how many FlowFiles must be present for them to be combined into one FlowFile. If the configurationMaximum Group Sizeis not defined, the size of the bins generated is not limited and each time theMinimum Number of Entriesthreshold is reached, all FlowFiles in the Processor’s queue are integrated into one FlowFile.In addition to the quantitative definition of the desired size of the bins, it is also possible to perform the merging of FlowFiles depending on the time. With the option
Max Bin Age, a positive integer value can be defined as a duration or a time unit in seconds, minutes or hours, according to which the FlowFiles are combined.In addition, a
Correlation Attribute Namecan be defined to group FlowFiles in the queue according to each other. This makes it possible to exclude independent FlowFiles from the combination and to create thematically related FlowFiles by combining them. However, it should be noted that only one correlation attribute can be defined. All FlowFiles that do not have the defined attribute are not processed and therefore remain in the queue. -
Defragment
The second strategy offered for combining individual FlowFiles is the defragment strategy, in which specific attributes are used for merging. If the individual FlowFiles were previously contained in just one FlowFile and were separated during the flow by a split Processor, for example, there are individual attributes that are used with this strategy. The attributesfragment.identifier,fragment.countandfragment.indexgenerated by splitting are used to reunite the associated FlowFiles. This strategy can be used well together with _ Split_ Processors (e.g. SplitJson), which then automatically add the required attributes.
-
-
Merge Format
TheMerge Formatsetting can be used to specify the format in which the individual FlowFiles are to be merged. By default, this option is set toBinary Concatenation, whereby different FlowFiles are combined into a single one. Optionally, the data can also be merged in ZIP, TAR or other formats. -
Attribute Strategy
In addition, the Processors provide the option of selecting a strategy for the existing attributes. Two options are available here, which are described below:-
Keep All Unique Attributes
With this strategy, all unique attributes are retained in the resulting FlowFile. If several individual FlowFiles share an attribute that also has the same value before processing, the attribute is also adopted if not all FlowFiles have the attribute.If the FlowFiles have different values for a common attribute, this attribute is not adopted. -
Keep Only Common Attributes
Attributes that are to be kept must be present in all individual FlowFiles that are combined. If the attribute is missing in one of the FlowFiles, the attribute is not integrated in the result.
-