DynamoDB Tutorial
Introduction
This article describes how to establish a connection to an AWS DynamoDB database with the following Processors.
-
PutDynamoDB (or PutDynamoDBRecord) to enter data into a table.
-
GetDynamoDB to retrieve data from a table.
-
DeleteDynamoDB to delete data from a table. == Prerequisites To use the DynamoDB Processors, you first need an existing AWS DynamoDB table DeleteDynamoDB to delete data from a table.
Prerequisites
In order to use the DynamoDB Processors, you first need an existing AWS DynamoDB table. To establish a connection to this, the following prerequisites must be given or known:
-
the name/address of the DynamoDB table to be accessed.
-
a form of authentication for AWS
-
The name of the hash and range keys of the table.
Authentication
For authentication, we recommend using the Services AWSCredentialsProviderControllerService.
Alternatively, the authentication data can also be specified directly in the individual Processors.
|
Even if the authentication for the Processors runs via the AWSCredentialsProviderControllerService, the correct value for the "Region" property must always be given in the Processors. |
Basic Put and Get operations
This paragraph explains the basic functionality of the PutDynamoDB and GetDynamoDB Processors. We will look at the following small example.
|
DynamoDB is a NoSQL database. Data is stored here using a primary (hash key) and a secondary (range key) key. |
Given is a DynamoDB table in which information about users is to be stored. The table has a hash key and a range key:
-
Hash key:
User -
Range key:
Range
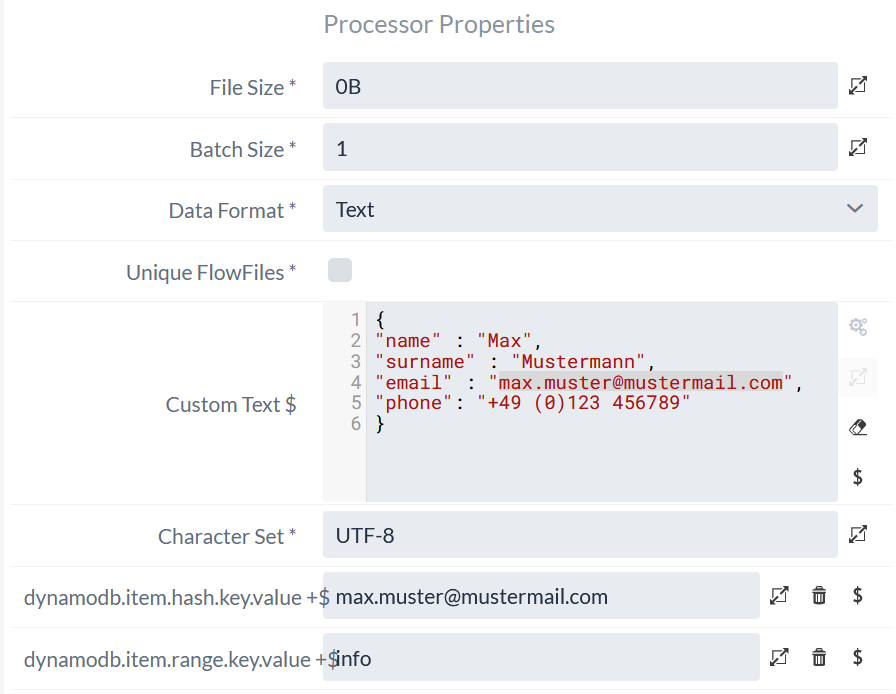
Now we want to enter basic information about our users in the table using the PutDynamoDB Processor. In this example, we assume that the information is given in the form of a JSON object:
{
"name" : "Max",
"surname" : "Mustermann",
"email" : "max.muster@mustermail.com",
"phone": "+49 (0)123 456789"
}To store this data in the DynamoDB table, we set this object as the content of a FlowFile. In addition, the FlowFile requires the following attributes for the hash and range key:
-
dynamodb.item.hash.key.value -
dynamodb.item.range.key.value
In this example, we use the user’s email for the hash key and the string info as the range key.
Here you can see how to generate a corresponding FlowFile using a GenerateFlowFile Processor.
Now we need to configure the PutDynamoDB Processor.
In addition to the already known properties, we also need to specify the name of the attribute under which the incoming data is to be stored.
This is done using the property Json Document Attribute.
In this example, we simply call this attribute data.
|
Both PutDynamoDB and |
PutDynamoDB
A configuration for a PutDynamoDB Processor could then look like this:

If you now use this configuration in a flow together with the previously generated FlowFile as follows, the data is inserted into the table (or changed if it already exists).
If executed successfully, the FlowFile is forwarded to the Success Relation without any changes.
After execution, the table could look like this:
| User | Range | data |
|---|---|---|
info |
|
GetDynamoDB
The GetDynamoDB Processor works in the same way as the PutDynamoDB Processor. A configuration could look like this.

As before, the hash key, range key and attribute are read from the (FlowFile) attributes of an incoming FlowFile.
If the corresponding data is available in the table, it is entered as content in the FlowFile and this is forwarded to the success relation.
If the data cannot be found in the table, the FlowFile is forwarded to the not found relation instead.
|
The property |
Deleting data from the database
To delete data from the table, use the DeleteDynamoDB Processor. As before, the attributes of an incoming FlowFile specify the hash and range key of the data to be deleted. All attributes of the corresponding data are deleted.
The configuration is analogous to the GetDynamoDB processor.
Special case PutDynamoDBRecord
The PutDynamoDBRecord Processor allows several pieces of data (in record format) to be written to the database at once.
Data with different range keys and different attributes can be written simultaneously.
The data must be given in a format that can be read by a record reader and must be given in the correct format depending on the application.
The properties of this Processor differ significantly from the conventions of the previously explained Processors.
-
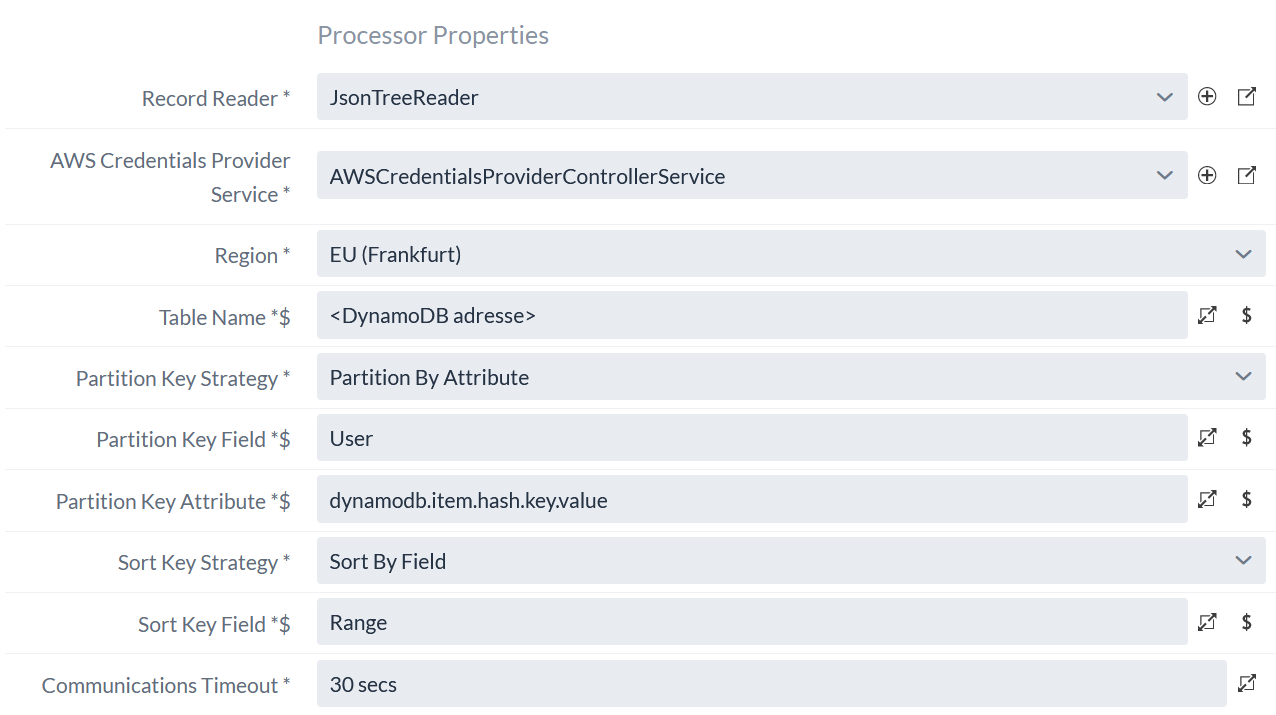
Partition Key Fieldis the name of the hash key of the table. In our caseUser. -
Sort Key Fieldis the name of the range key of the table. In our caseRange.
For both keys it is possible to determine them dynamically and with different strategies.
-
The hash key can either be given as a FlowFile attribute as usual, read as a field from the incoming record or generated dynamically from a UUID.
-
The range key can either be omitted (only possible for tables without a range key), read from a field in the incoming record or created using a counter.
Example
As before, we use a table with:
-
Hash*Key:*
User -
Range Key:
Range
In this example, we want to store payment information for our user in addition to basic information. We therefore have not one, but two JSON objects that we want to store. So that we can use these with the PutDynamoDBRecord Processor, we need to put them in the correct format:
[
{
"Range" : "info",
"data" : {
"name" : "Max",
"surname" : "Mustermann",
"email" : "max.muster@mustermail.com",
"phone": "+49 (0)123 456789"
}
},
{
"Range" : "payment",
"paymentMethod" : "credit card",
"data" : {
"paymentMethod": "credit card",
"lastFourDigits": "5678",
"expirationDate": "12/28",
"billingZip": "54321"
}
}
]This is a list of 2 records, both of which are to be entered in the table.
As both records have the same hash key, we will specify this using an attribute in the FlowFile.
To do this, we again use the attribute dynamodb.item.hash.key.value and set the value to the E-Mmail max.muster@mustermail.com.
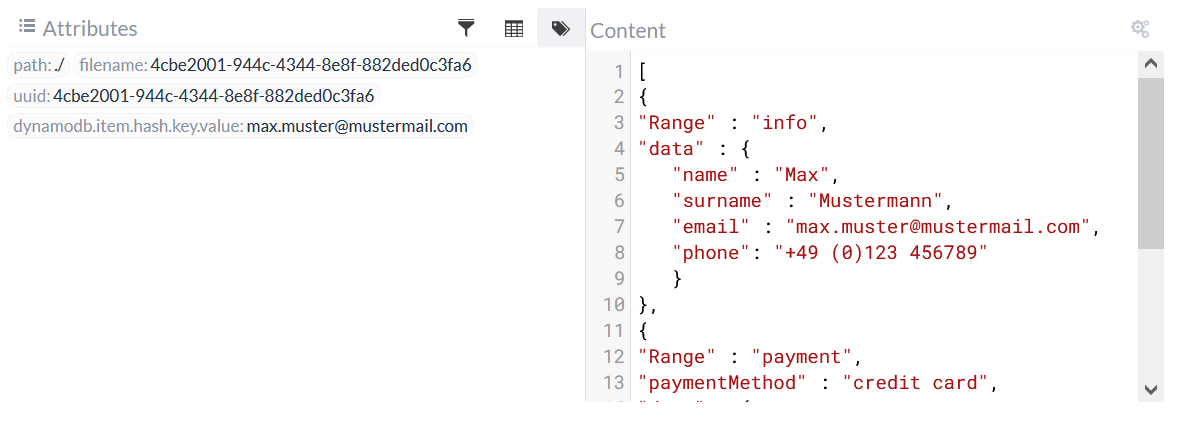
The range key is specified here by the fields Range in the records and each additional record field is used as an attribute.
(The name of this field must correspond to the name of the Sort Key Field property)
In this example, this means:
The first record in the list is entered in the database with the hash key max.muster@mustermail.com and range key info and has an attribute with the name data.
For the second record with the range key payment, the attribute paymentMethod is also entered in addition to the data attribute.
The corresponding configuration for the PutDynamoDBRecord Processor: