Ausgewählte Processors
In diesem Abschnitt befinden sich einige ausgewählte Processors, die besondere Eigenschaften aufweisen und daher detaillierter beschrieben werden.
JSONataTransformJSON
Der JSONataTransformJSON-Processor dient dazu, mithilfe eines JSONata-Skriptes JSON zu transformieren.
Auf eingehendem Content in JSON können Queries bzw. Transformationen ausgeführt werden.
Der Processor hat in IGUASU folgende extra Funktionen:
-
$nfUuid()erzeugt eine UUID vom Typ 4 (Pseudozufallsgenerator). Die UUID wird mit einem kryptografisch starken Pseudozufallszahlengenerator erzeugt. -
Attribute aus dem Eingangs-FlowFile können (neben dem Eingangs-Content) gelesen/verarbeitet werden:
$nfGetAttribute(<name>) -
Neben bzw. auch anstelle des Ausgangs-Contents können Ergebnisse in Attribute geschrieben werden:
$nfSetAttribute(<name>,<value>) -
Alle Attribute aus dem Eingangs-FlowFile können als ganzes Object gelesen werden. Dies ist zum Beispiel sinnvoll, um über die Attribute zu iterieren und zu filtern:
$nfGetAttributes() -
Die NiFi Expression Language kann verwendet werden:
$nfEl(<expression>) -
Es kann ein Lookup-Service verwendet werden, wenn dieser am Processor definiert wurde:
$nfLookup(<key>)
Der JSONataTransformJSON-Processor hat einen spezifischen Editor, der das einfache Bearbeiten des gesamten Skriptes erlaubt.
|
Sie können Ihre Transformation schnell ausprobieren, indem Sie den "Test/run"-Button verwenden |
Mehr allgemeine Information über JSONata:
|
Wie dieser Processor JSONata-Transformationen implementiert, unterscheidet sich leicht von try.jsonata.org! |
Die erweiterten Funktionen werden nun im Detail erläutert.
Einfache Transformation
Eingangsnachricht (auch für die weiteren Beispiele; von jsonata.org übernommen):
{
"FirstName": "Fred",
"Surname": "Smith",
"Age": 28,
"Address": {
"Street": "Hursley Park",
"City": "Winchester",
"Postcode": "SO21 2JN"
}
}Überführung einiger dieser Daten in eine andere Form der Adresse:
{
"name": FirstName & " " & Surname,
"mobile": Phone[type = "mobile"].number,
"address": Address.City
}Ergebnis:
{
"name": "Fred Smith",
"mobile": "077 7700 1234",
"address": "Winchester"
}Ergebnis in Attribute schreiben
Wollen Sie die gleichen Ergebnisse in Attribute statt in den Ausgangs-Content setzen, können Sie die folgende Funktion verwenden:
-
nfSetAttribute(<name>,<value>)
Zusätzlich können Sie am Processor deaktivieren, dass das Ergebnis des Skriptes in den Ausgang geschrieben wird:
Write Output |
false |
Der Content wird also unangetastet gelassen. In diesem Fall ist das sinnvoll, da nur die Attribute erstellt werden sollen.
Das Skript sieht nun so aus:
$nfSetAttribute("name", FirstName & " " & Surname) &
$nfSetAttribute("mobile", Phone[type = "mobile"].number) &
$nfSetAttribute("city", Address.City)Im Ergebnis erscheinen dann die Attribute:
name |
Fred Smith |
mobile |
077 7700 1234 |
city |
Winchester |
Es gibt am Processor auch noch ein Property, um das gesamte Ergebnis der Transformation in ein Attribut zu schreiben:
Write to Attribute |
<name of attribute> |
Attribute lesen
Wollen Sie im ersten Fall beispielsweise auf das Attribut filename zugreifen, um dieses als ID in das Ergebnis zu setzen, sieht das Skript folgendermaßen aus:
{
"id": $nfGetAttribute("filename"),
"name": FirstName & " " & Surname,
"mobile": Phone[type = "mobile"].number,
"address": Address.City
}Möchten Sie über alle Attribute filtern, um nur einige zu mit einem Prefix zu erhalten, geht das wie hier beschrieben. Der hier verwendete Prefix 'http.headers.' wird vom HandleHttpRequest Prozessor verwendet - somit könnte man nur auf den Http-Header Feldern operieren:
$nfGetAttributes().$sift(function($v, $k) { $contains($k, 'http.headers.') }).*Nutzung der NiFi Expression Language
Wollen Sie die NiFi Expression Language innerhalb eines JSONata verwenden, geht dies über die entsprechende Funktion nfEl(<expression>).
Im folgenden Beispiel wird die NiFi Expression Language verwendet, um mit einer Regular Expression zu prüfen, ob der Name korrekt ist (also nur entsprechende Zeichen enthält).
{
"name": FirstName & " " & Surname,
"isValidName": $nfEl("${literal('" & FirstName & " " & Surname & "'):matches('^[\\p{L} \\p{Nd}_]+$')}"),
"mobile": Phone[type = "mobile"].number,
"address": Address.City
}Die Funktion kann zusätzlich zu der Expression eine beliebige Anzahl von name/value-Paaren aufnehmen.
Diese werden der Expression Language für die Ausführung als temporäre Attribute bereitgestellt.
Das heißt, dass sie im Gegensatz zu $nfSetAttribute(<name>,<value>) nicht über die Ausführung hinaus gesetzt werden.
Das kann beispielsweise genutzt werden, um Werte aus dem Input für die $nfEl()-Ausführung als Attribute mitzugeben.
Anstelle des Literals im letzten Beispiel könnte also auch Folgendes geschrieben werden:
{
...
"isValidName": $nfEl("${name:matches('^[\\p{L} \\p{Nd}_]+$')}", "name", FirstName & " " & Surname )
...
}TransformXml
Der TransformXml-Processor dient dazu, mithilfe eines XSLT-Skriptes XML zu transformieren.
Der Processor hat in IGUASU folgende Besonderheiten:
-
die neueste Version des Saxon XSLT-Processors mit XSLT 3.0/XPath 3.1 wird unterstützt
-
der lizenzierte Saxon EE inkl. seiner erweiterten Features wird mitgeliefert
-
das XSLT-Skript kann direkt in einem Property gespeichert werden (neben den Varianten des externen Files bzw. des Lookup-Service) - dies erleichtert die Verwendung und das Deployment
-
die direkte Verarbeitung von JSON durch
fn:json-to-xml()bzw.fn:xml-to-json()wird durch die Möglichkeit der Einbettung des eingehenden JSON in einen XML-Root-Tag erleichtert -
Ergebnis-Dokumente (
xsl:result-document) können verwendet werden, um:-
Relationen/Ausgänge des Moduls zu erstellen
-
Attribute im success/failure-Ausgang zu erstellen (hierzu muss der Name des href mit
a:starten)
-
-
Nutzung der NiFi Expression Language in XPath-Ausdrücken
-
dazu wird der Namespace
xmlns:nf="http://nifi.org"deklariert -
die aufzurufende Methode heißt el() - z.B.
<xsl:value-of select="nf:el('${UUID()}')"/>
-
Der TransformXml-Processor hat einen spezifischen Editor, der das einfache Bearbeiten des gesamten Skriptes erlaubt.
Die Funktionen werden folgend im Detail erläutert.
Nutzung von Ergebnis-Dokumenten
Voraussetzung:
Support result documents |
true |
Im XSLT sieht das dann so aus:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0">
<xsl:output method="xml" name="xml" indent="yes"/>
<xsl:output method="text" name="text"/>
<xsl:template match="/">
<xsl:result-document href="relationOne" format="xml">
<resultOne><xsl:copy-of select="/"/></resultOne>
</xsl:result-document>
<xsl:result-document href="relationTwo" format="text">
number of nodes: <xsl:value-of select="count(//*)"/>
</xsl:result-document>
<xsl:result-document href="a:attributeOne" format="text">something</xsl:result-document>
</xsl:template>
</xsl:stylesheet>Die Ergebnisse der result-documents von relationOne und relationTwo werden in die entsprechenden Relationen (Ausgänge) des Processors geschrieben.
Diese werden verfügbar, indem Sie im Skript die result-document-Tags erstellen und das Skript dann speichern.
Das Ergebnis des result-document von a:attributeOne wird aufgrund des Prefix a: als Attribut in die success/failure-Relation geschrieben.
NiFi Expression Language
Die NiFi Expression Language kann sowohl bei der Übergabe von Parametern über Dynamic Properties als auch innerhalb von XPath-Ausdrücken verwendet werden.
EL in Parametern
Durch das Hinzufügen eines beliebigen Dynamic Properties (über den -Button) wird der Inhalt dieses Properties als Parameter (xsl:param) an das XSLT-Skript übergeben.
Innerhalb des Wertes darf die Expression Language verwendet werden.
Diese kann dabei z.B. auch auf die Attribute des herein gehenden FlowFiles zugreifen:
testParam |
the filename is ${filename} |
Dies kann dann im XSLT verwendet werden:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0">
<xsl:output method="text"/>
<xsl:param name="testParam"/>
<xsl:template match="/">
<xsl:value-of select="$testParam"/>
</xsl:template>
</xsl:stylesheet>Da der filename in NiFi typischerweise eine UUID ist, kommt als Ergebnis heraus:
the filename is 8ec0e87a-56dc-425f-b4c5-1de7f515ddea
EL in XPath Ausdrücken*
Um die NiFi Expression Language innerhalb von XPath zu verwenden, muss dies zunächst durch das entsprechende Property eingeschaltet werden:
Allow NiFi EL in XPath |
true |
Im XSLT-Skript muss noch der Namespace gesetzt werden (xmlns:nf="http://nifi.org").
Dann kann die Funktion (nf:el()) überall dort, wo XPath-Ausdrücke erlaubt sind, aufgerufen werden:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="3.0"
xmlns:nf="http://nifi.org">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:value-of select="nf:el('${UUID()}')"/>
</xsl:template>
</xsl:stylesheet>Das Ergebnis ist:
2560fc8c-3581-4732-8862-6bb191eb0dcc
Um Werte aus dem Input innerhalb die nf:el()-Ausführung zu verwenden, können die noch als temporäre Attribute mitgegeben, in dem eine beliebige Anzahl von name/value-Paaren als Argumente aufgenommen werden.
So kann z.B. als folgende den Autor eines Buchs vom Input ausgelesen werden, und gleich innerhalb eine NiFi Expression Language Funktion als Attribut verwenden.
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:nf="http://nifi.org" version="3.0">
<xsl:output method="text" />
<xsl:template match="/">
<xsl:value-of select="nf:el('${author:toUpper()}', 'author', /library/book[1]/author)" />
</xsl:template>
</xsl:stylesheet>JSON-Verarbeitung
Um JSON direkt lesen zu können, muss das entsprechende Property gesetzt sein:
Surround input with <xml> tag |
true |
Dadurch wird das eingehende JSON zu einem XML, auf welches dann die XPath-3.0-Funktion angewendet werden kann:
Eingangs-JSON:
{
"name": "Harry",
"age": 23,
"address": {
"city": "London"
}
}XSLT Skript:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fn="http://www.w3.org/2005/xpath-functions"
exclude-result-prefixes="fn" version="3.0">
<xsl:output indent="yes"/>
<xsl:template match="/">
<xsl:copy-of select="fn:json-to-xml(.)"/>
</xsl:template>
</xsl:stylesheet>Ergebnis:
<map xmlns="http://www.w3.org/2005/xpath-functions">
<string key="name">Harry</string>
<number key="age">23</number>
<map key="address">
<string key="city">London</string>
</map>
</map>Um aus einer solchen XML-Struktur wieder JSON zu machen, können Sie fn:xml-to-json() nutzen.
ListenBPCFlowStarter
Der ListenBPCFlowStarter-Processor ermöglicht die nahtlose Verknüpfung von IGUASU mit einer Virtimo Business-Process-Center-Instanz. Hierbei werden die anfangs erwähnten BPC-Services in IGUASU genutzt, um anhand der Konfigurationen eine Verbindung aufzubauen. Der ListenBPCFlowStarter fungiert im Anschluss als Listener und Startpunkt eines Flows, an den die Daten und der Input des BPC-Nutzers übergeben wird.
Der Processor hat in IGUASU folgende Besonderheiten:
-
Der gewählte BPC Listener Base Path wird im BPC unter den IGUASU-Einstellungen als ID angezeigt.
-
Zur besseren Unterscheidung der hinterlegten ListenBPCFlowStarter-Processors werden zudem im BPC der
Flow Starter Nameund dieFlow Starter Desc.angezeigt. -
Durch den Einsatz von unterschiedlichen HybridRESTServerController-Services können die ListenBPCFlowStarter-Processors im BPC in verschiedene Komponenten gruppiert werden.
Weitere Informationen zur Verbindung von IGAUSU und BPC finden sie im BPC Anbindung Tutorial.
PutBPCProcessLog
Der PutBPCProcessLog-Processor ermöglicht das Erstellen von BPC Process Logs, die vom IGUASU-Processor an die gewünschte BPC-Instanz übermittelt werden.
Für diesen Zweck müssen einerseits ein BPC Controller, in dem die BPC-URL und der angelegte API Key enthalten sind, und andererseits der gewünschte BPC Logger ausgewählt werden.
Zusätzlich wird die Möglichkeit angeboten, den Input Type zu ändern und dadurch zu bestimmen, ob der Inhalt des FlowFiles oder die Datei in der BPC Entries JSON-Property geloggt werden soll.
Dies ist das Format der erwarteten LOG-Daten:
{
"entries": [
{
"parent": {
"process-id": "448f1867-b4ef-4fb8-9db6-cf0f26acc384",
...
},
"children": [
{
"process-id": "448f1867-b4ef-4fb8-9db6-cf0f26acc384",
"child-id": "a18b56f8-5312-3c81-779d-4c08bd4ee29f",
...
}
]
}
]
}| In BPC Version 5.0 wurde das Array, wo die Child-Einträge erwartet sind, von "childs" in "children" umbenannt. Wenn Ihre BPC noch älter als die Version 5.0 ist, sollten Sie daher "childs" anstelle von "children" verwenden. |
Der Processor hat in IGUASU folgende Besonderheiten:
-
In den Auswahlmöglichkeiten der Property
Choose BPC Loggersind die Logger hinterlegt, die zuvor im BPC erstellt wurden. Falls die BPC-Instanz nicht erreichbar sein sollte, kann zudem die ID des Loggers angegeben werden.
Weitere Informationen zur Verbindung von IGAUSU und BPC finden sie im BPC Anbindung Tutorial und in der BPC Dokumentation.
PutBPCAuditLog
Der PutBPCAuditLog-Processor dient dazu, Daten in das BPC Audit Log zu schreiben. Zur Konfiguration können dabei das BPC Audit Level, Audit Originator und die Action gewählt werden. Zur Verknüpfung des IGUASU-Flows mit einer BPC-Instanz wird hierbei der HybridRESTClientController-Service genutzt, in dem die BPC-URL und der generierte BPC API Key hinterlegt sind.
Der Processor hat in IGUASU folgende Besonderheiten:
-
Es kann die NiFi Expression Language verwendet werden, um die benötigten Log-Informationen aus den FlowFiles auszulesen.
Weitere Informationen zur Verbindung von IGAUSU und BPC finden sie im BPC Anbindung Tutorial und in der BPC Dokumentation.
Metro-Processors
Mit den Metro-Processors wird die grundsätzliche Möglichkeit eröffnet FlowFiles direkt von einem Processor (PutMetro) an einen anderen (GetMetro/ExitMetro) zu leiten, ohne diese mit einer Connection verbinden zu müssen. Dies eröffnet in verschiedenen Szenarien ganz neue Möglichkeiten der Umsetzung. Diese verschiedenen Szenarien werden hier beschrieben:
Zugriff auf ein FlowFile aus einem früheren Schritt im Flow (GetMetro)
Man hat des Öfteren die Notwendigkeit, ein FlowFile aus einem früheren Verarbeitungsschritt später noch einmal zu benötigen. Es steht aber nur das FlowFile zur Verfügung, das aus dem letzten Verarbeitungsschritt hervorging.
Um dieses Problem zu lösen, gibt auch folgende Möglichkeiten, die hier zunächst mit ihren Nachteilen dargestellt werden, bevor wir die Metro Lösung zeigen:
Bestehende Lösungsansätze
-
Daten in Attribute schreiben, die dann bis zur Verwendung mitgeschleift werden
-
In Attributen sollten keine großen Datenmengen stehen
-
Man muss die Daten in Attribute konvertieren und dann möglicherweise wieder zurück in den Content schreiben, wenn der verwendete Prozessor das so verlangt
-
Attribute werden immer in jeden Processor mitgegeben und potenziell verarbeitet
-
-
Einen Bypass legen - z.B. mit ForkEnrichment/JoinEnrichment oder MergeContent
-
Das ist primär für eine Anreicherung von strukturierten Inhalten wie z.B. JSON gedacht
-
Die Struktur ist daher dann eine andere und man muss potenziell noch einmal transformieren
-
Das Diagramm wird aufgebläht und man muss eine Verbindung von dem ursprünglichen Vorkommen bis zur Verwendung ziehen, was viel später sein kann
-
-
Ablage in einem Dritt-System
-
Man benötigt ein Drittsystem
-
Man muss sich selbst um das Aufräumen kümmern bzw. sicher sein, dass die Daten genauso transaktional vorhanden sind, wie im Flow selbst
-
Erschwert Deployments/Staging
-
Lösung mit PutMetro/GetMetro
Das FlowFile, das man später noch benötigt, wird zusätzlich zur normalen Verarbeitung zusätzlich vor einen PutMetro Processor in die Queue geschrieben. Dieser Processor hat einen MetroLineController Service, den er mit dem späteren GetMetro Prozessor teilt – hierüber wird sozusagen die Untergrundbahn zwischen diesen Processors gelegt, die man im Diagramm nicht direkt sieht.
Kommt nun das originale FlowFile zum GetMetro Processor fragt dieser den mit dem Service verbundenen PutMetro Processor nach einem FlowFile in seiner Queue, das den gleichen Wert eines Attributes hat, wie das originale FlowFile. Dies ist die relevante Konfiguration am GetMetro – der Name des Correlations-Attributes, aus dem dieser Zusammenhang hergestellt werden kann.
Im Ausgang des GetMetro Processors kommt nun das FlowFile heraus, das vor dem PutMetro Processor liegt. Hier wird es aus der Queue genommen (und ausserdem in die success Relation des PutMetro, wenn diese eine Verbindung haben sollte).
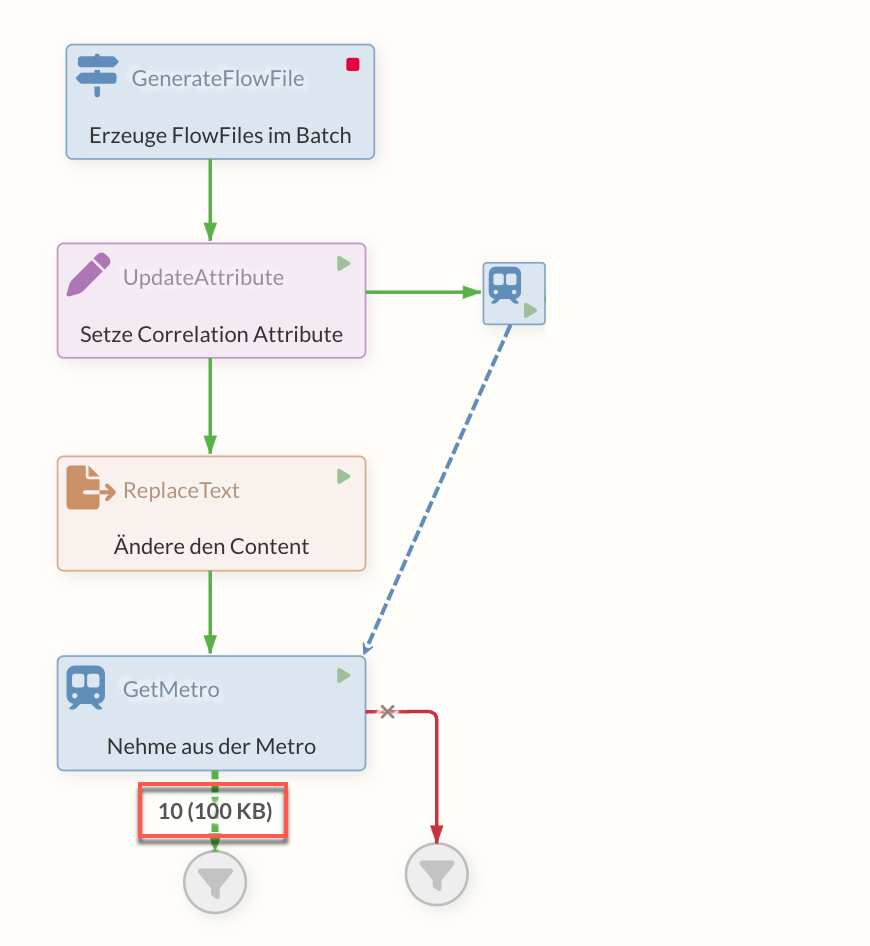
|
Wurden die zwischengespeicherten FlowFiles bereits durch einen GetMetro-Processor abgerufen, sind diese nicht mehr verfügbar. Dadurch können Fehler bei weiteren Zugriffsversuchen entstehen. |
An den Processors können Dynamic Properties gesetzt werden, die dann als Attribute zu den FlowFiles hinzugefügt werden.
Vorteile dieser Lösung
-
Das Diagramm bleibt übersichtlich
-
Man benötigt keien externen Systeme
-
Alles wird mit Flow-Mitteln gelöst
-
Die Transaktionalität bleibt bestehen – das FlowFile vor dem PutMetro wird erst entfernt, wenn das FlowFile von dem GetMetro weitergegeben wurde
-
Die Geschwindigkeit der Verarbeitung ist hoch
-
Es können Grenzen von Process Groups überwunden werden
Nachteile der Lösung
-
Gegenüber einem Bypass sieht man hier nicht direkt den Zusammenhang, wenn man auf das Diagram guckt
-
Es können Grenzen von Process Groups überwunden werden … dies ist neben dem Vorteil eben auch ein Nachteil, wenn die Nutzung darüber zu unübersichtlichen Flows führt. Das sollte bedacht werden.
Aufruf eines anderen Flows (ExitMetro)
Wenn ich an vielen Stellen eines Flows einen anderen Flow aufrufen möchte, gibt es dafür bisher folgende Möglichkeiten mit ihren Nachteilen:
-
Modellierung über eine (versionierte) Process-Group, die an den Stellen immer direkt eingebunden wird
-
Relativ aufwändig in der Modellierung und Pflege
-
Jede Subprozessgruppe ist eine eigene Instanz und hat z.B. auch ihre eigenen Qeueus und Reihenfolgen → es wird also nicht wirklich EIN anderer Flow aufgerufen, sondern viele gleiche
-
-
Aufruf über externe Möglichkeiten wie z.B. HTTP/REST
-
Es wird über ein externes Protokoll gegangen, was potenziell langsam ist und Authentifizierungen benötigt
-
Die Übergabe von Content+Attributen muss berücksichtigt werden
-
Die Flow Engine wird verlassen
-
Die Provenance ist schwieriger zu verfolgen
-
Lösung mit PutMetro/ExitMetro
Über den PutMetro und einen über den MetroService verbundenen ExitMetro wird eine "Untergrundbahn" angelegt. Es können dabei auch viele PutMetro auf einen ExitMetro verweisen. Sobald ein FlowFile in den PutMetro geht, wird es direkt an den ExitMetro geleitet und kommt dort aus der "success" Relation.
An dem PutMetro können über Dynamic Properties noch Attribute gesetzt werden.
Ein typischer Anwendungsfall für dieses Konstrukt ist z.B. ein Prozess-Logging in ein externes System wie das Business Process Center. An diversen Stellen im Flow möchte man Daten (aus Attributen und/oder dem Content) gleichförmig in das BPC loggen, um den Staus des übergeordneten Business Prozesses festzuhalten. Hinter dem ExitMetro liegt in diesem Beispiel ein Processor, der den Status in das BPC schreibt.
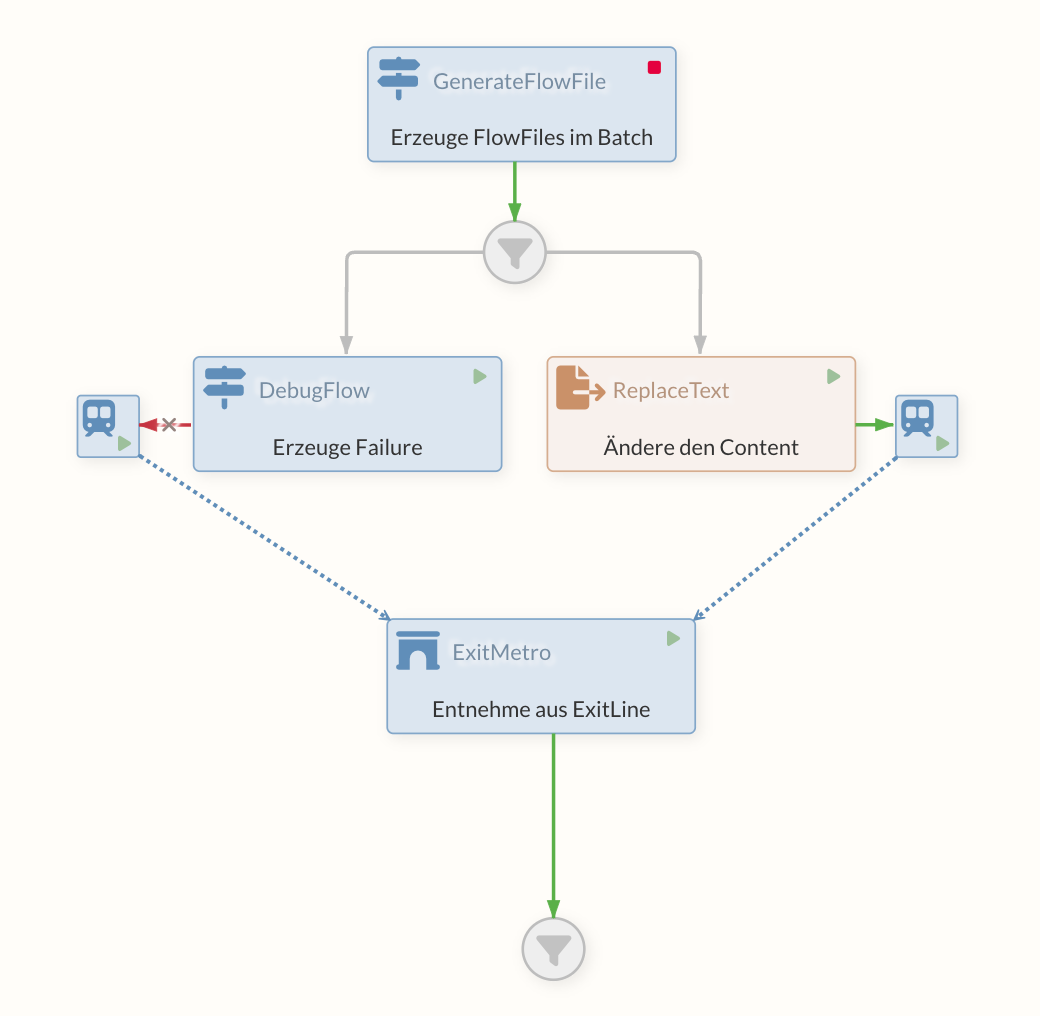
How-To
Ein weiteres Anwendungsbeispiel der beschriebenen Processors befindet sich zudem im Abschnitt How-Tos unter Metro.
Merge-Processors
Um unabhängige oder zuvor getrennte FlowFiles zu vereinen stehen unterschiedliche Processors zur Verfügung.
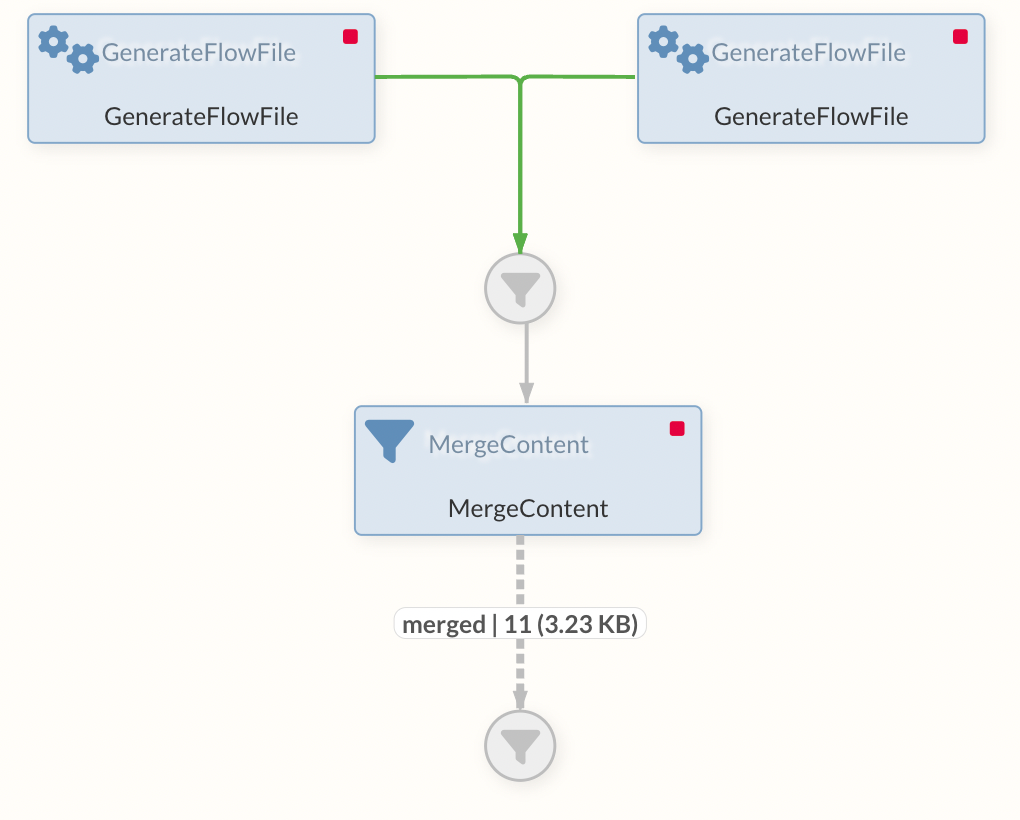
Hierbei werden je nach Processor unterschiedliche Strategien und Formate angeboten, die je nach individueller Anforderung angepasst werden können. In diesem Abschnitt befindet sich eine Übersicht über einige Processors, die zum Vereinen von FlowFiles genutzt werden können
MergeContent und MergeRecord
Die beiden Processors MergeContent und MergeRecord verfügen über viele Einstellungsmöglichkeiten, die zum Zusammenführen von FlowFiles genutzt werden können. Viele der Optionen sind in beiden Processors verfügbar, wobei es kleine Unterschiede gibt. Beispielsweise können bei der Record-orientierten Verarbeitung vom MergeRecord-Processor zusätzlich ein Reader und ein Writer definiert werden, wodurch beim Mergen ebenfalls eine Conversion erfolgen könnte. In Folgenden sind die Konfigurationsmöglichkeiten und die Funktionsweise der Optionen beschrieben:
-
Merge Strategy
Mit der Merge Strategy kann definiert werden, nach welchen Kriterien die FlowFiles kombiniert werden sollen. Hierbei stehen zwei unterschiedliche Vorgehen zur Verfügung, die für diesen Zweck ausgewählt werden können.-
Bin-Packing Algorithm
Der Bin-Packing Algorithmus ist die Strategie die Standardmäßig zunächst ausgewählt ist. Hierbei werden FlowFiles in einzelnen Behälter (Bins) gesammelt, bis die definierten Schwellenwerte erreicht sind. Mit dem ParameterMinimum Number of Entrieskann dadurch definiert werden, wie viele FlowFiles vorhanden sein müssen, damit diese in ein FlowFile kombiniert werden. Wenn die KonfigurationMaximum Group Sizenicht definiert ist, ist die Größe der dadurch generierten Bins nicht eingeschränkt und jedes Mal wenn derMinimum Number of EntriesSchwellenwert erreicht ist, werden alle FlowFiles in der Queue des Processors in ein FlowFile integriert.Neben der quantitativen Definition der gewünschten Größe der Bins ist es ebenfalls möglich, das Zusammenführen von FlowFiles abhängig von der Zeit durchzuführen. Mit der Option
Max Bin Agekann ein positiver Integer Wert als Dauer oder eine Zeiteinheit in Sekunden, Minuten oder Stunden definiert werden, nach der die Kombination der FlowFiles erfolgt.Darüber hinaus kann ein
Correlation Attribute Namefestgelegt werden, anhand FlowFiles in der Queue passend zueinander gruppiert werden. Dadurch ist es möglich, unabhängige FlowFiles aus der Kombination auszuschließen und durch die Vereinigung thematisch zusammenhängende FlowFiles zu erstellen. Hierbei ist allerdings zu beachten, dass nur ein Korrelations-Attribut festgelegt werden kann. Alle FlowFiles die das definierte Attribut nicht besitzen, werden nicht verarbeitet und bleiben daher in der Queue. -
Defragment
Die zweite angebotene Strategie um einzelne FlowFiles zu kombinieren ist die Defragment-Strategie, bei der spezifische Attribute zum Zusammenführen genutzt werden. Waren die einzelnen FlowFiles zuvor bereits in nur einem FlowFile enthalten und wurden im Laufe des Flows durch einen Split-Processor beispielsweise getrennt, befinden sich individuelle Attribute die bei dieser Strategie genutzt werden. Die durch das Splitten generierten Attributefragment.identifier,fragment.countundfragment.indexwerden verwendet, um die zugehörigen FlowFiles erneut zu vereinen. Diese Strategie lässt sich gut zusammen mit -Split Processors verwenden (z.B. SplitJson), welche die benötigten Attribute dann automatisch hinzufügen.
-
-
Merge Format
Mit derMerge FormatEinstellung kann festgelegt werden, in welchem Format die Zusammenführung der einzelnen FlowFiles erfolgen soll. Standardmäßig ist diese Option aufBinary Concatenationgesetzt, wodurch verschieden FlowFiles in ein einzelnes kombiniert werden. Optional können die Daten ebenfalls im ZIP, TAR oder in anderen Formaten verknüpft werden. -
Attribute Strategy
Zusätzlich steht in den Processors die Möglichkeit zur Verfügung, eine Strategie für die vorhandenen Attribute auszuwählen. Hierbei stehen zwei Optionen zur Verfügung, die im Folgenden beschrieben sind:-
Keep All Unique Attributes
Mit dieser Strategie werden alle einzigartigen Attribute beim Ergebnis-FlowFile beibehalten. Sollten mehrere einzelne FlowFiles vor der Verarbeitung ein Attribut teilen, dass zudem denselben Wert hat, dann wird das Attribut ebenfalls übernommen, wenn nicht alle FlowFiles das Attribut haben.Sollten die FlowFiles unterschiedliche Werte für ein gemeinsames Attribut haben, so wird dieses Attribut nicht übernommen. -
Keep Only Common Attributes
Attribute, die behalten werden sollen, müssen bei allen einzelnen FlowFiles die kombiniert werden vorhanden sein. Sollte das Attribut bei einem der FlowFiles fehlen, wird das Attribut nicht im Ergebnis integriert.
-