Metro-Processors
Metro-Processors open up the basic possibility of routing FlowFiles directly from one Processor (PutMetro) to another (GetMetro/ExitMetro) without having to connect them to a Connection. This opens up completely new possibilities for implementation in various scenarios. These different scenarios are described here:
Accessing a FlowFile from an earlier step in the flow (GetMetro)
It is often necessary to need a FlowFile from an earlier processing step again later. However, only the FlowFile that resulted from the last processing step is available.
To solve this problem, there are also the following options, which are first presented here with their disadvantages before we show the Metro solution:
Existing solution approaches
-
Write data to attributes, which are then dragged along until they are used
-
Attributes should not contain large amounts of data
-
You have to convert the data to attributes and then possibly write it back to the content if the Processor used requires this
-
Attributes are always passed along to each Processor and potentially processed
-
-
Create a bypass - e.g.B. with ForkEnrichment/JoinEnrichment or MergeContent
-
This is primarily intended for enriching structured content such as JSON
-
The structure is therefore then different and you potentially have to transform it again
-
The Diagram is bloated and you have to draw a connection from the original occurrence to the use, which can be much later
-
-
Storage in a third-party system
-
You need a third-party system
-
You have to take care of the cleanup yourself or make sure that the data is trans be sure that the data is available in the same transactional form as in the flow itself
-
Makes deployments/staging more difficult
-
Solution with PutMetro/GetMetro
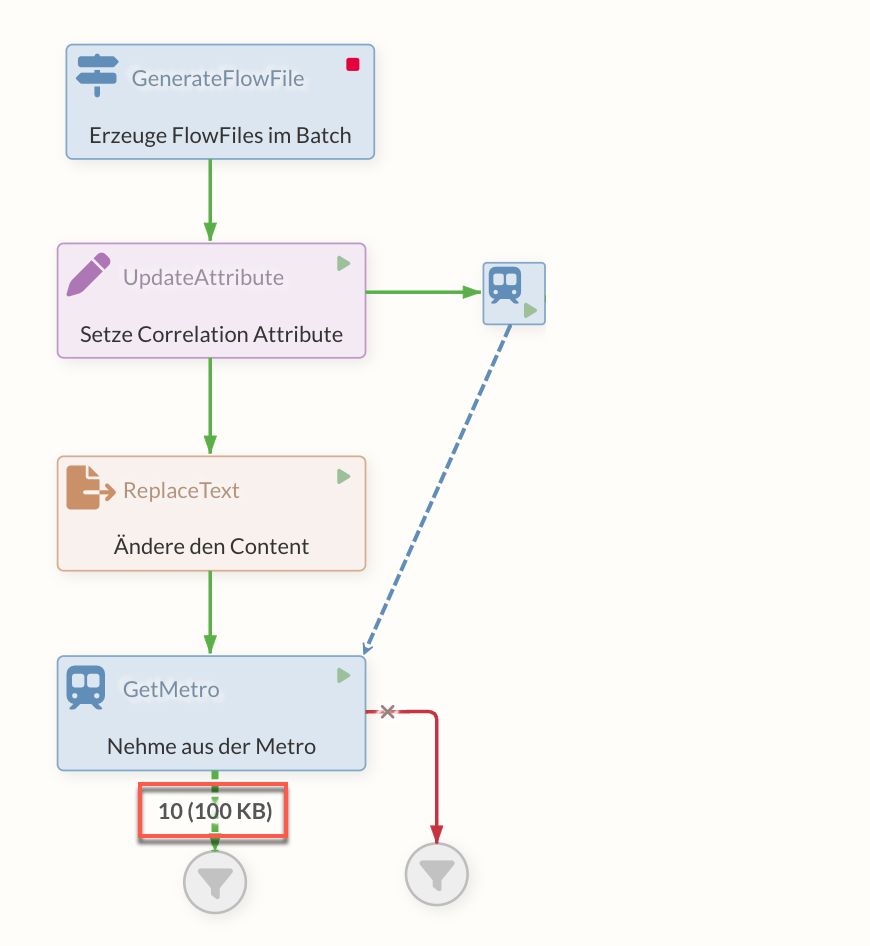
The FlowFile, which is needed later, is written to the queue before a PutMetro Processor in addition to normal processing. This Processor has a MetroLineController Service, which it shares with the later GetMetro Processor - this creates the subway path between these Processors, so to speak, which is not directly visible in the Diagram.
If the original FlowFile now comes to the GetMetro Processor, it asks the PutMetro Processor connected to the Service for a FlowFile in its queue that has the same value of an attribute as the original FlowFile. This is the relevant configuration on the GetMetro - the name of the correlation attribute from which this correlation can be established.
The FlowFile that is located before the PutMetro Processor now comes out at the output of the GetMetro Processor. Here it is taken out of the queue (and also into the success relation of the PutMetro, if this should have a connection).
|
If the cached FlowFiles have already been retrieved by a GetMetro Processor, they are no longer available. This can result in errors during further access attempts. |
Dynamic properties can be set on the Processors, which are then added as attributes to the FlowFiles.
Advantages of this solution
-
The Diagram remains clear
-
No external systems are required
-
Everything is solved with Flow means
-
The transactionality remains - the FlowFile before the PutMetro is only removed, when the FlowFile has been passed on by the GetMetro
-
The processing speed is high
-
Limits of Process Groups can be overcome
Disadvantages of the solution
-
Compared to a bypass, you cannot see the connection directly when you look at the diagram
-
Limits of Process Groups can be overcome .. this is not only an advantage, but also a disadvantage if using them leads to confusing flows. This should be considered.
Calling another flow (ExitMetro)
If I want to call another flow at many points in a flow, there are the following options with their disadvantages:
-
Modeling via a (versioned) Process Group, which is always directly integrated at the points
-
Relatively complex to model and maintain
-
Each sub-process group is its own instance and has, for example also has its own queues and sequences → therefore not really ONE other flow is called, but many of the same
-
-
Call via external options, e.g. HTTP/REST
-
An external protocol is used, which is potentially slow and requires authentication
-
The transfer of content+attributes must be taken into account
-
The flow engine is abandoned
-
Provenance is more difficult to track
-
Solution with PutMetro/ExitMetro
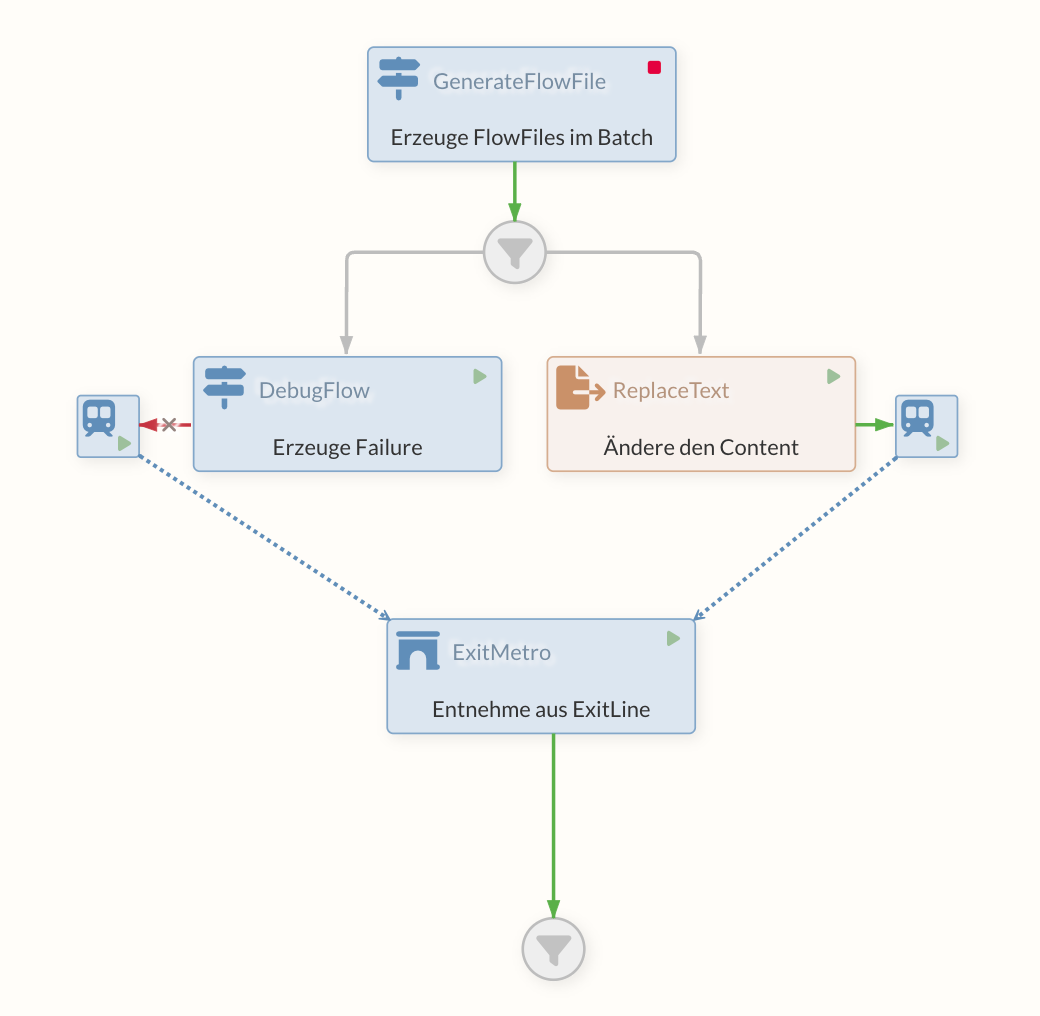
A "subway" is created via the PutMetro and an ExitMetro connected via the MetroService. Many PutMetros can also refer to one ExitMetro. As soon as a FlowFile goes into the PutMetro, it is routed directly to the ExitMetro and comes out of the "success" relation there.
Attributes can still be set on the PutMetro via Dynamic Properties.
A typical use case for this construct is, for example, process logging in an external system such as the Business Process Center. At various points in the flow, you want to log data (from attributes and/or the content) uniformly to the BPC in order to record the status of the higher-level business process. In this example, there is a Processor behind the ExitMetro that writes the status to the BPC.
How-To
A further application example of the Processors described can also be found in the How-Tos section under Metro.