Grundlagen-Tutorial
Einführung
In diesem Tutorial bauen wir einen einfachen IGUASU Flow. Dieser wird
-
eine Datei über das Internet abrufen,
-
Daten zwischen verschiedenen Formaten konvertieren,
-
einen REST Service anbieten,
-
und diesen dann auch aufrufen.
Zusätzlich machen wir von den in IGUASU verfügbaren Analysetools Gebrauch.
Der fertige Flow:
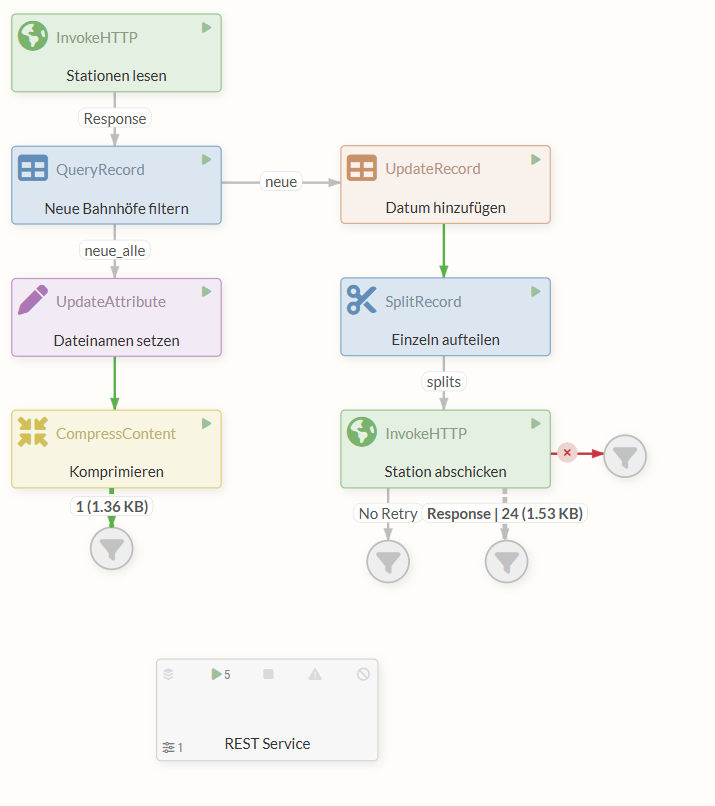
Ein Beispiel des abgeschlossenen Tutorials kann mit folgendem Link heruntergeladen werden: 30min-tutorial.json.
Wir werden den dort abrufbaren Flow nun Schritt für Schritt zusammenstellen.
Voraussetzungen
Für dieses Tutorial ist ein grundlegendes Verständnis von Datenformaten wie CSV, XML und JSON hilfreich. Kenntnisse über HTTP-Methoden (GET/POST), das Konzept von REST-APIs und einfache SQL-Abfragen sind ebenfalls von Vorteil. IGUASU-spezifische Begriffe und Konzepte werden im Laufe des Tutorials erklärt.
Wir verwenden in diesem Tutorial häufig die englischen Begriffe für Elemente der Benutzeroberfläche (z.B. 'Properties', 'Settings', 'Run Schedule'), da diese so in IGUASU angezeigt werden. Es erleichtert das Nachvollziehen der Schritte in der Software.
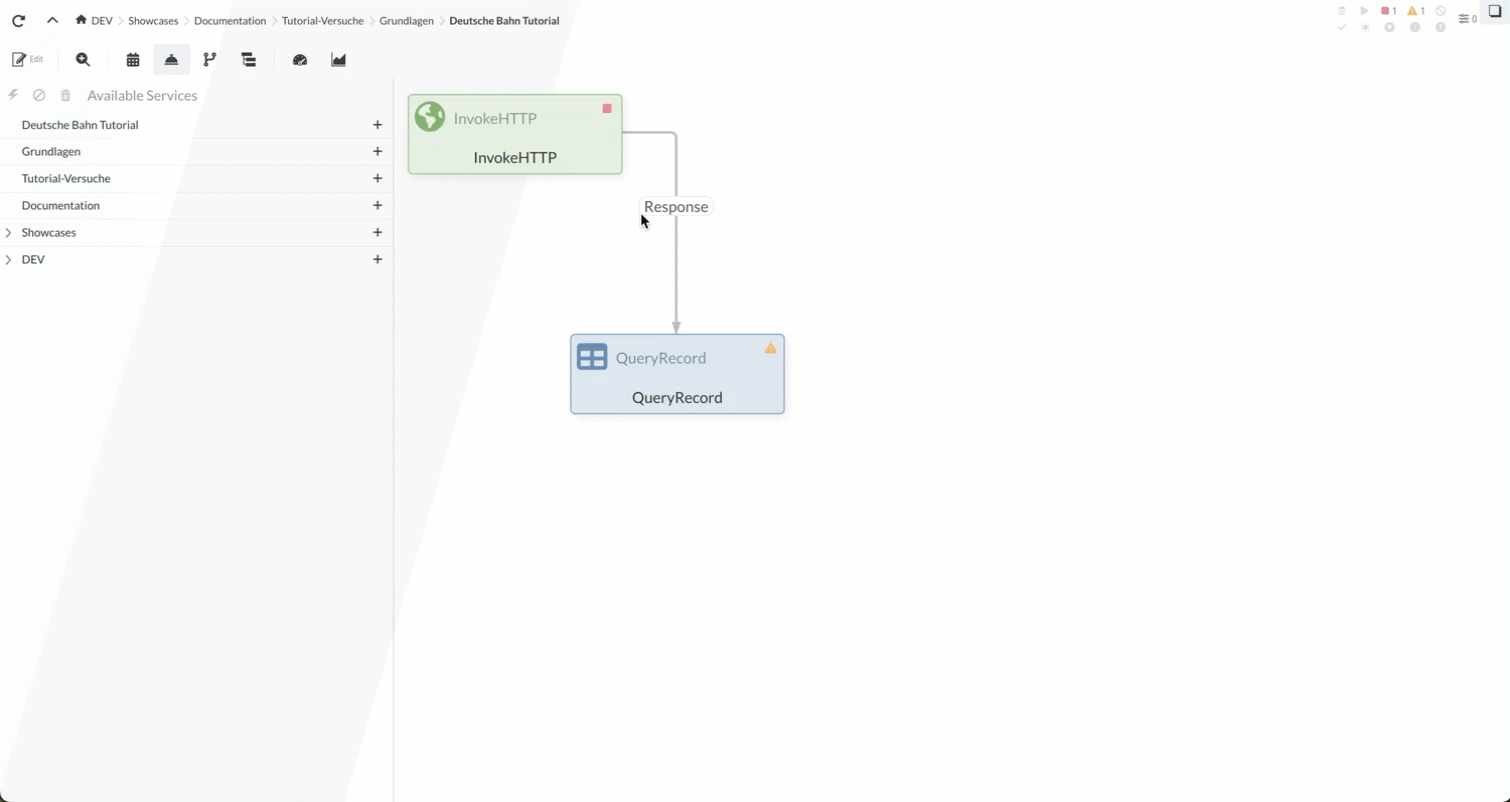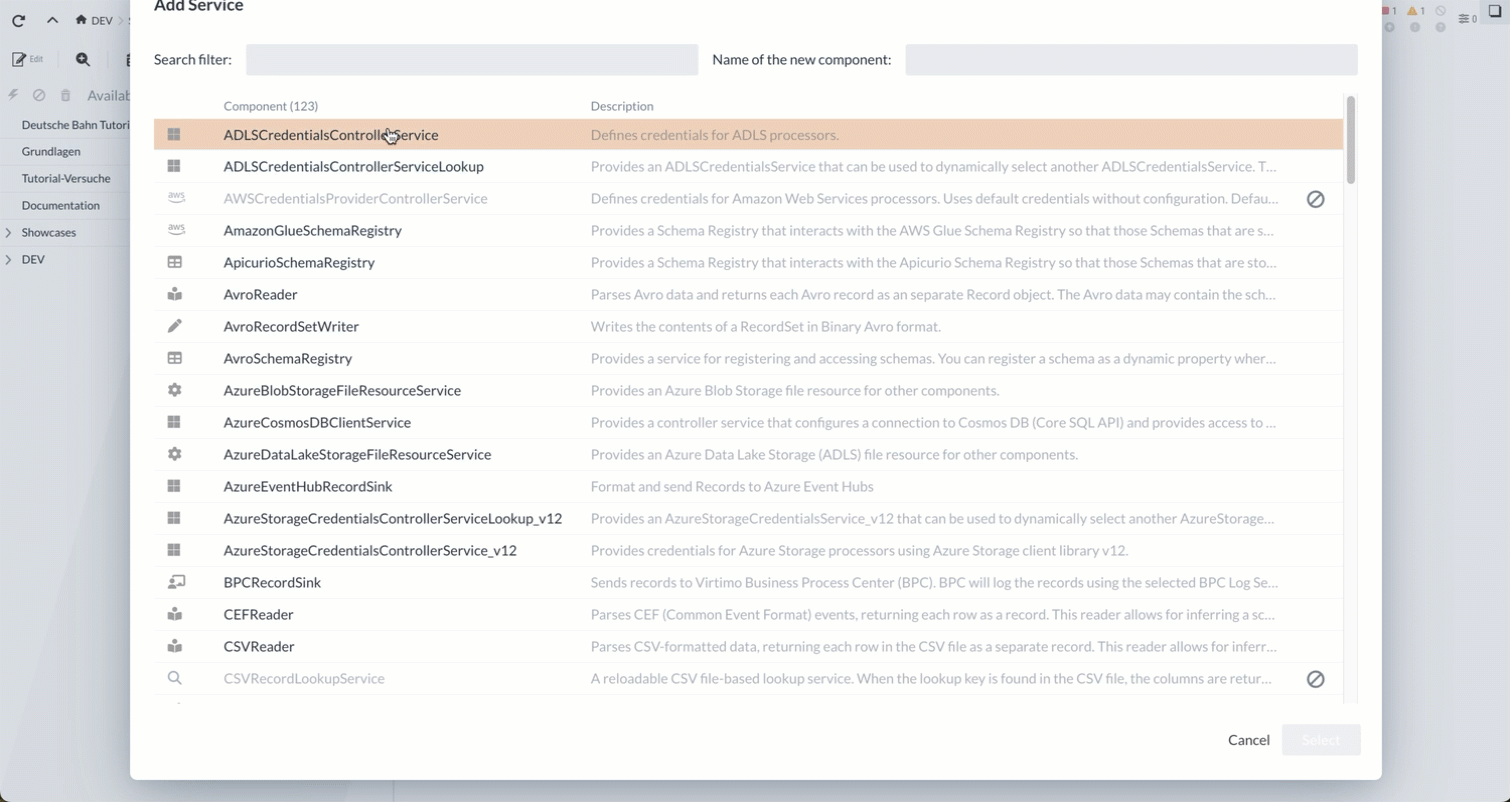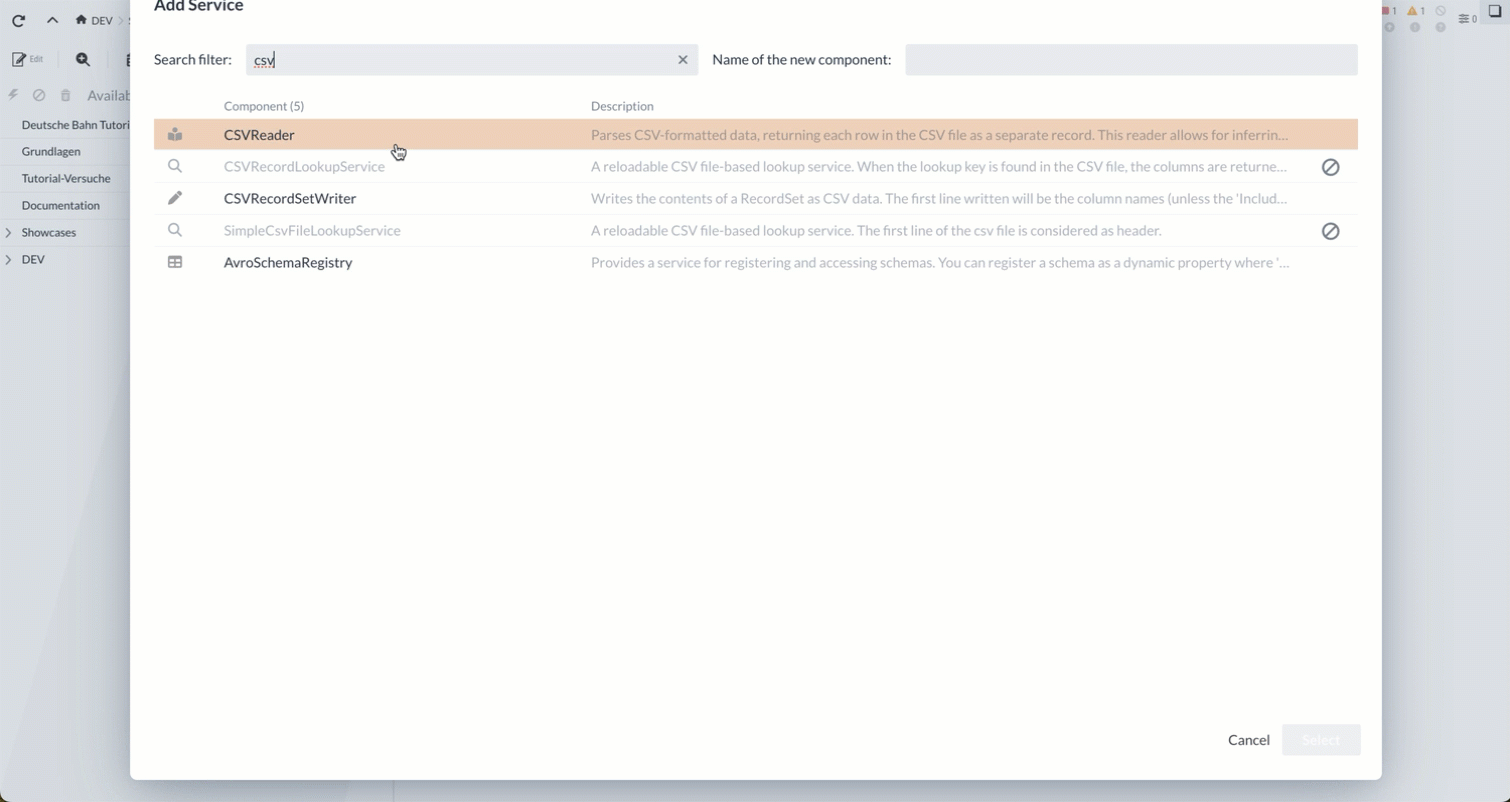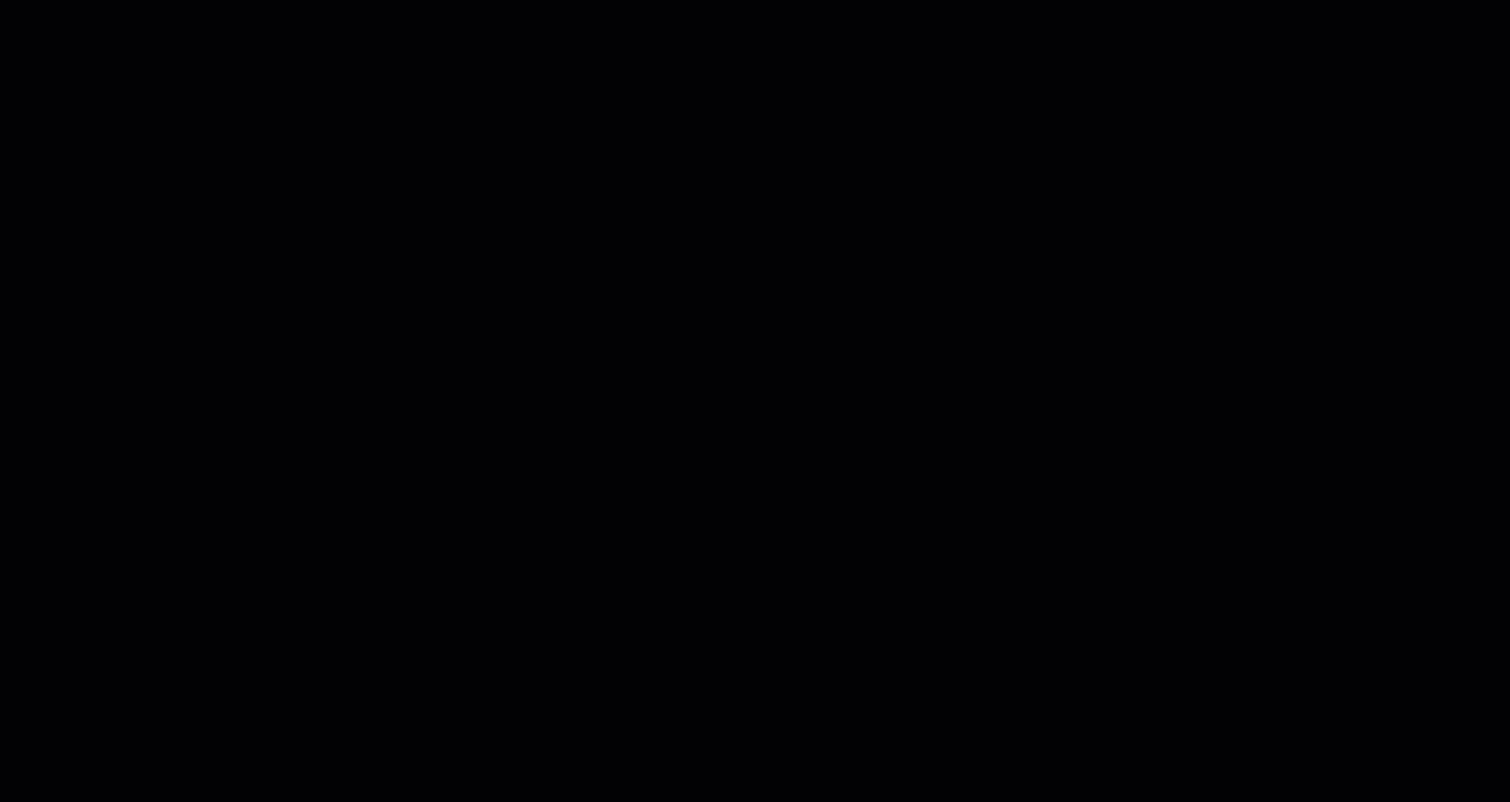
Teil 1: Bahnhöfe abrufen, filtern und speichern
Die zwei wichtigsten Komponenten in IGUASU sind die FlowFiles und die Processors.
Ein FlowFile ist ein Objekt, das entlang von Relations von einem Processor zum nächsten fließt.
Es besteht aus Content (beliebigen Daten) und Attributes (Metadaten).
Attributes sind Schlüssel-Wert-Paare, die Informationen wie z.B. den Namen einer Datei oder die URL einer Request enthalten.
FlowFiles werden von Processors erschaffen, verändert, an andere Processors weitergeleitet oder fallengelassen.
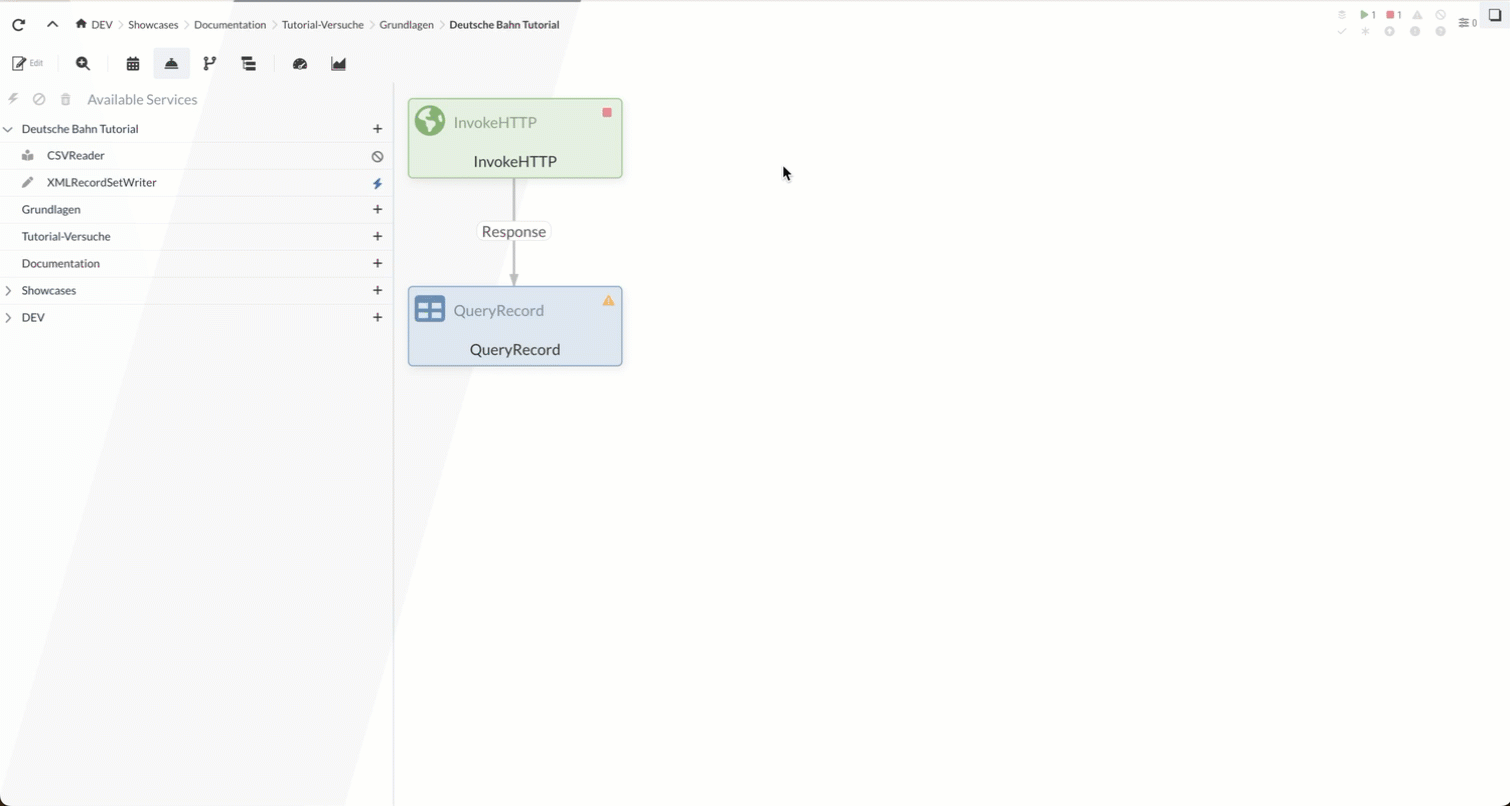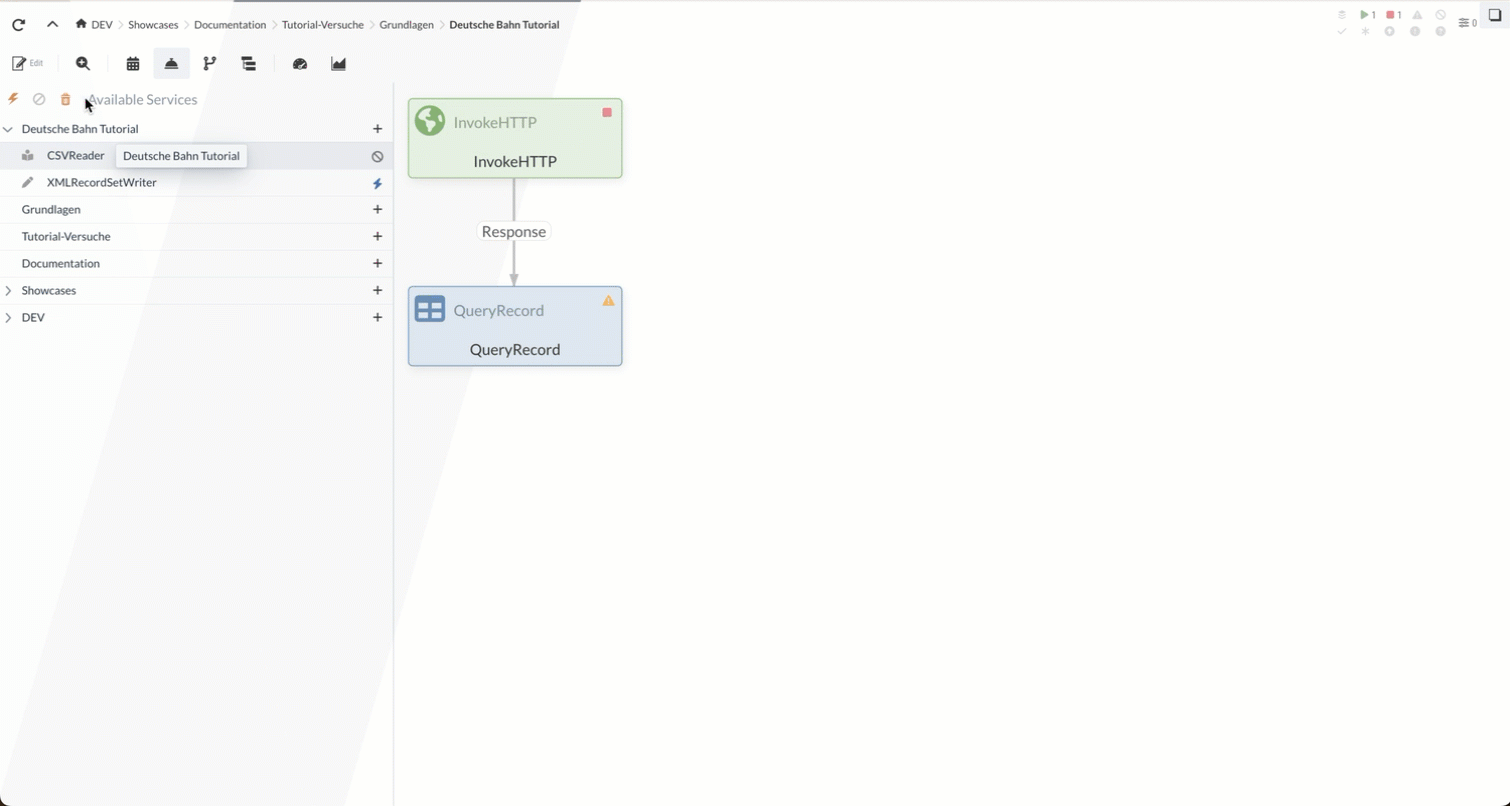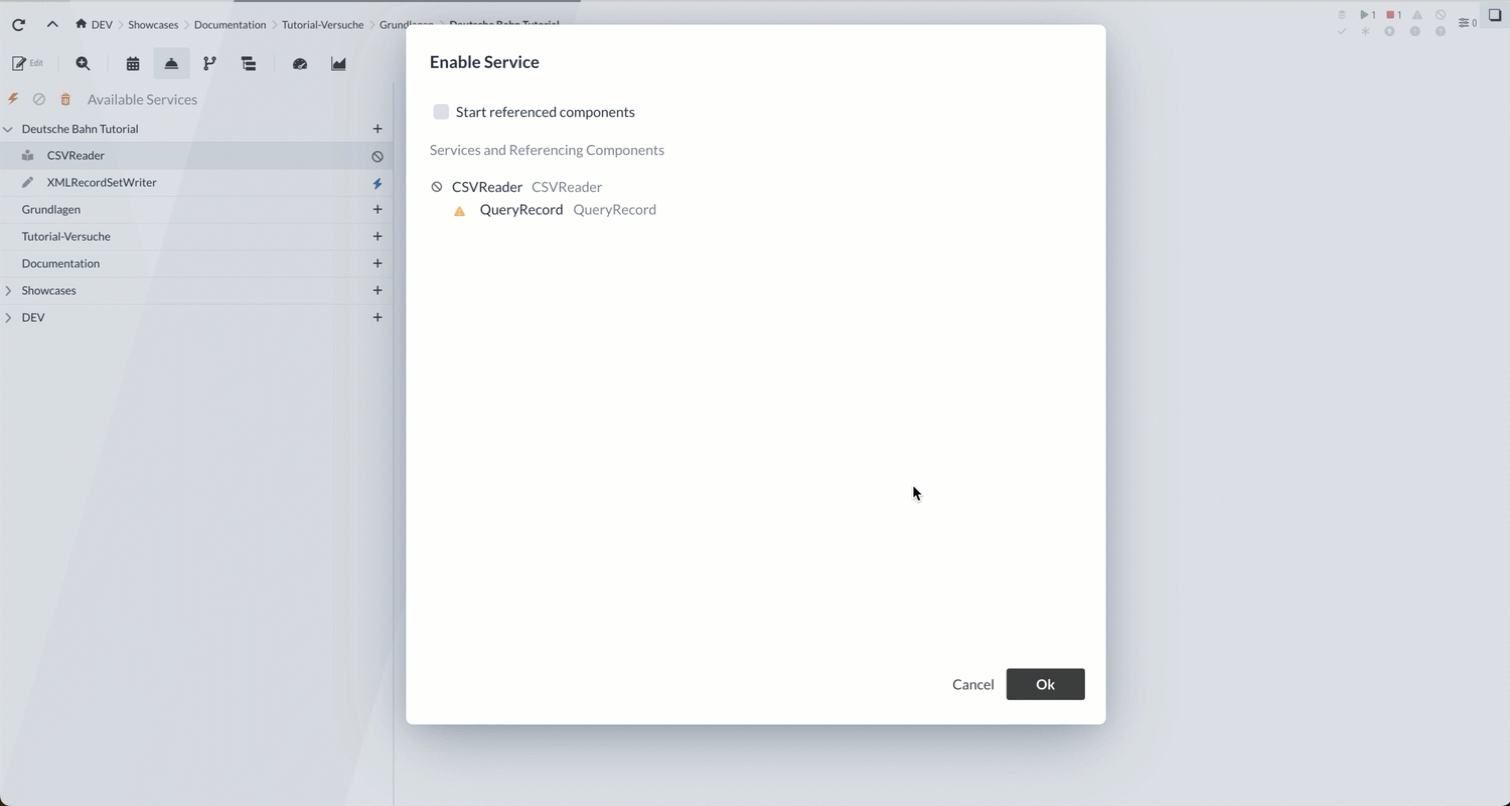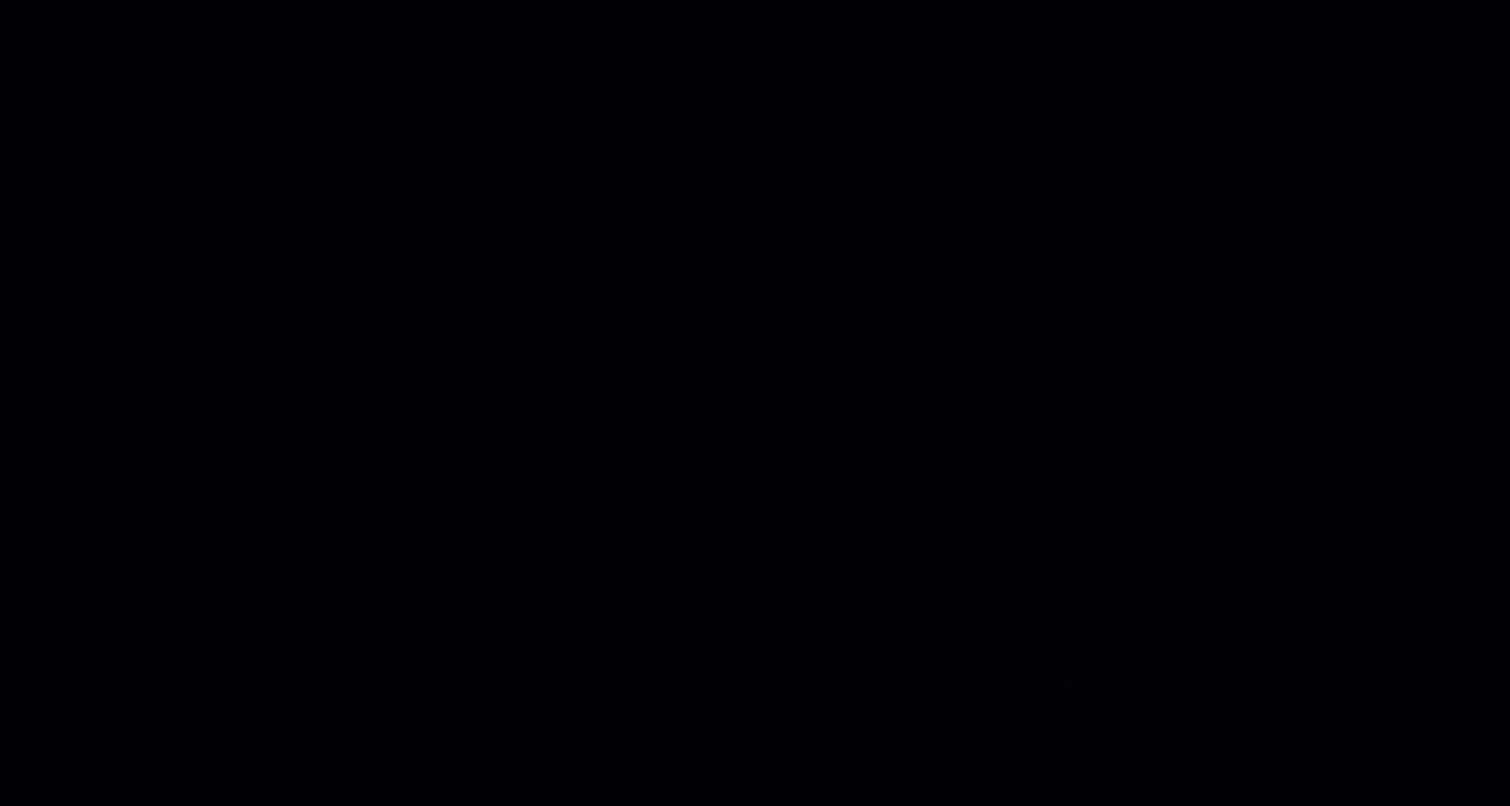
In diesem Teil des Tutorials werden wir zuerst mit einem InvokeHTTP Processor eine CSV-Datei mit Daten zu Bahnhöfen in Deutschland aus dem Internet abrufen. Diese Daten werden im FlowFile Content gespeichert.
Das FlowFile wird im zweiten Schritt an den QueryRecord Processor weitergeleitet. Dieser filtert aus dem Content (also den Bahnhofsdaten als CSV) die als neu gekennzeichneten Einträge zu Bahnhöfen heraus und konvertiert gleichzeitig die Einträge von CSV zu XML. Dabei macht der Processor von einem CSVReader und einem XMLRecordSetWriter Controller Service Gebrauch.
Mit dem nächsten Processor, dem UpdateAttribute Processor, setzen wir ein FlowFile Attribute, um den Dateinamen bei einem Export zu bestimmen.
Zuletzt kommt der CompressContent Processor zum Einsatz, mit dem wir den FlowFile Content, also die XML, komprimieren. Wir werden uns die komprimierte Datei am Ende anschauen - in einem echten Szenario könnte hier aber ein Processor stehen, der die Datei an ein externes System weiterleitet.
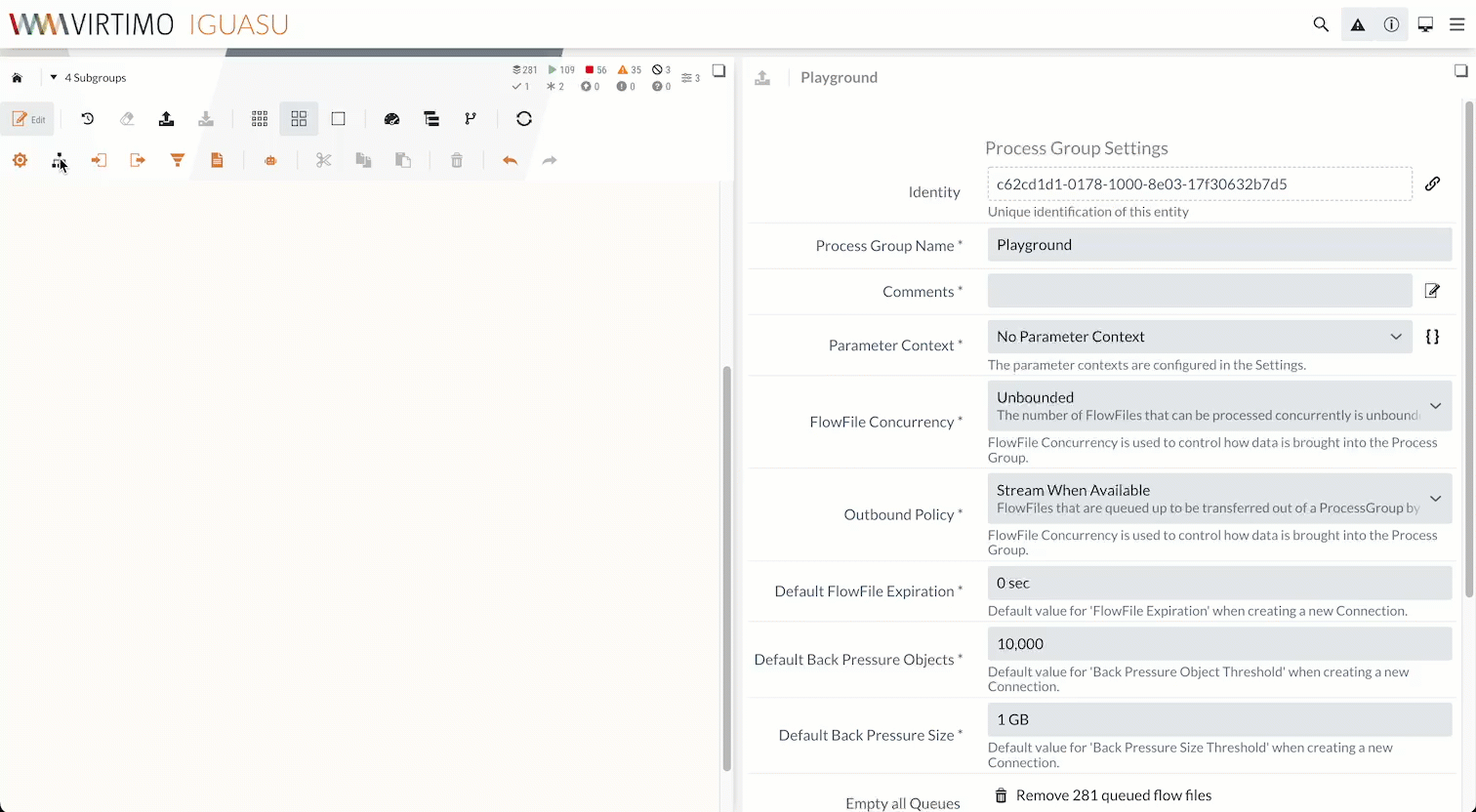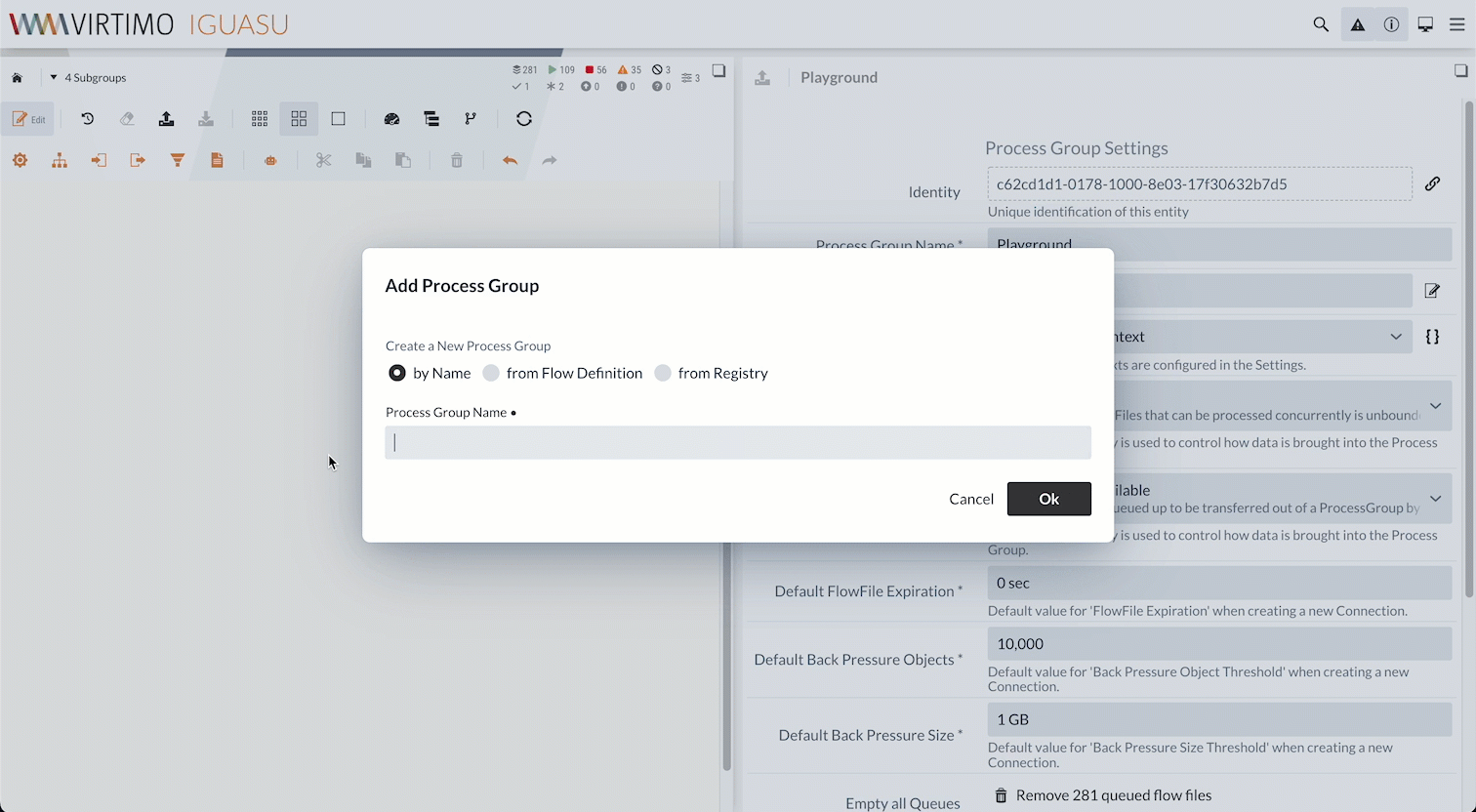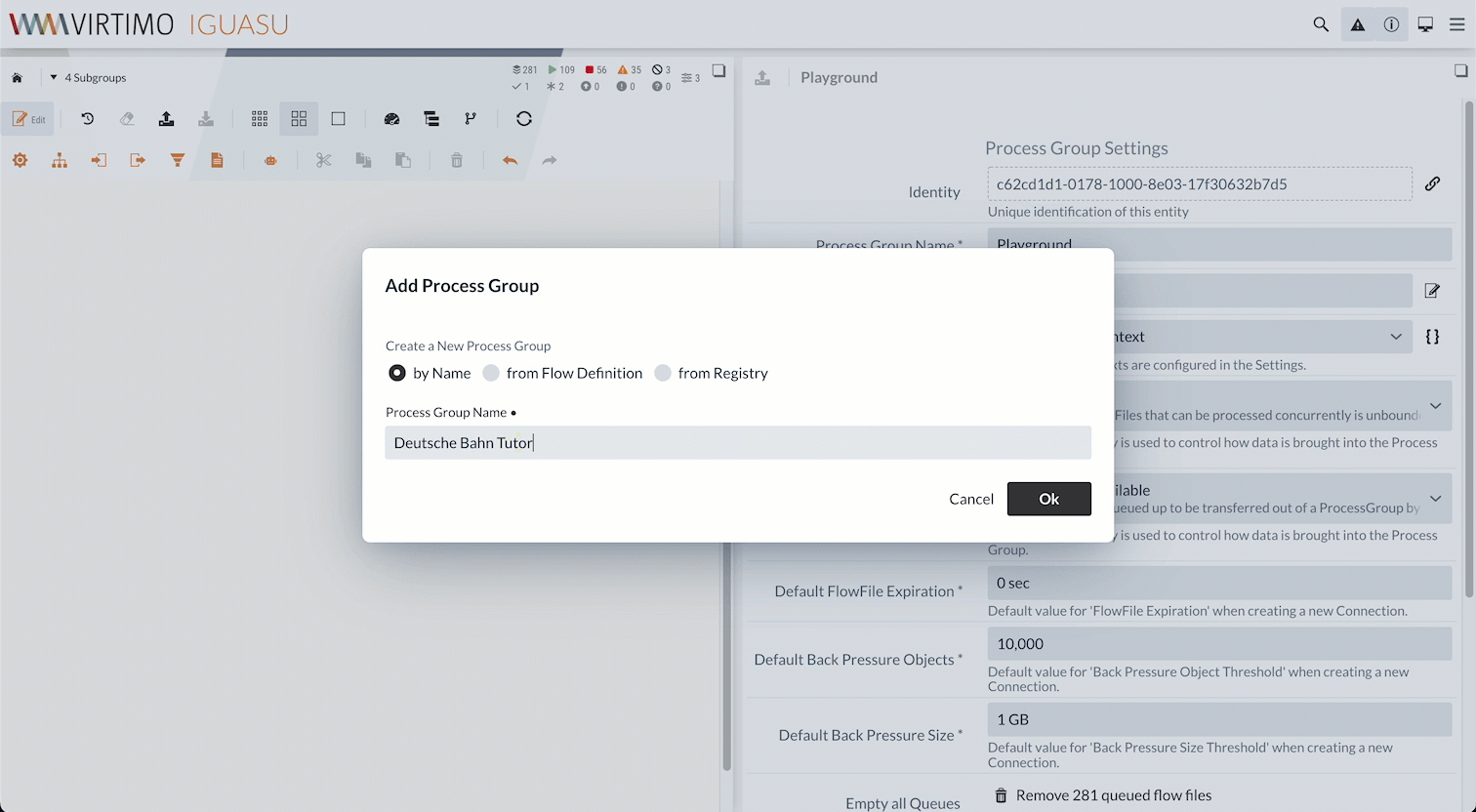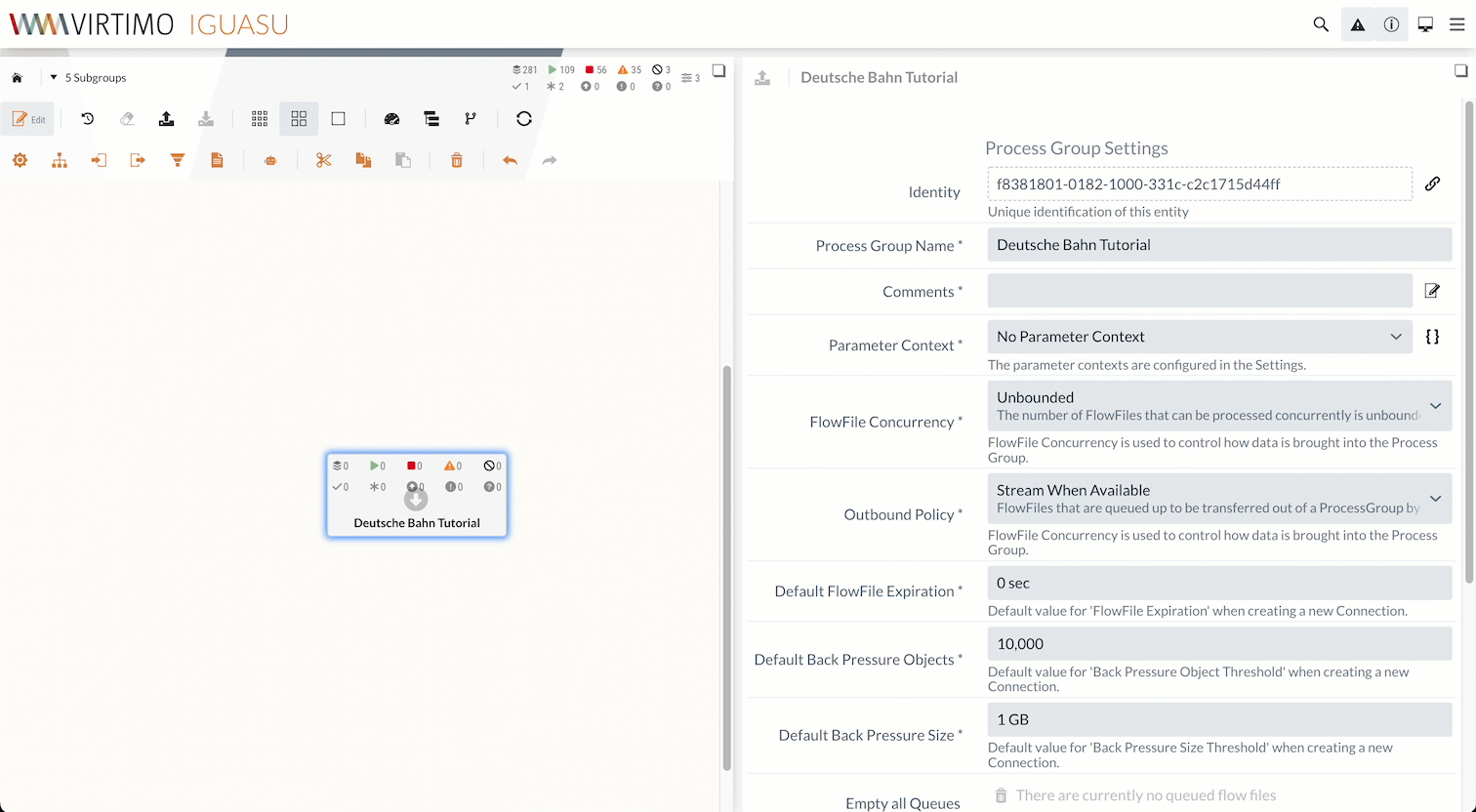
Zuerst erstellen wir eine neue Process Group, in der wir dann unseren Flow durch Processors implementieren.
Durch einen Doppelklick auf das erstellte Element gelangen wir in die erstellte Process Group.
1.1 InvokeHTTP Processor (Stationen laden)
Als Erstes werden wir einen InvokeHTTP Processor anlegen.
Der InvokeHTTP Processor kann beliebige HTTP-Requests ausführen.
Mit einem GET-Request auf die entsprechende URL laden wir die CSV-Datei herunter.
Die Datei wird intern in ein FlowFile übersetzt und kann an weitere Processors weitergeleitet werden.
Processor Konfiguration
Die Konfiguration der Processors erfolgt in den Properties- und Settings-Tabs des Moduleditors.

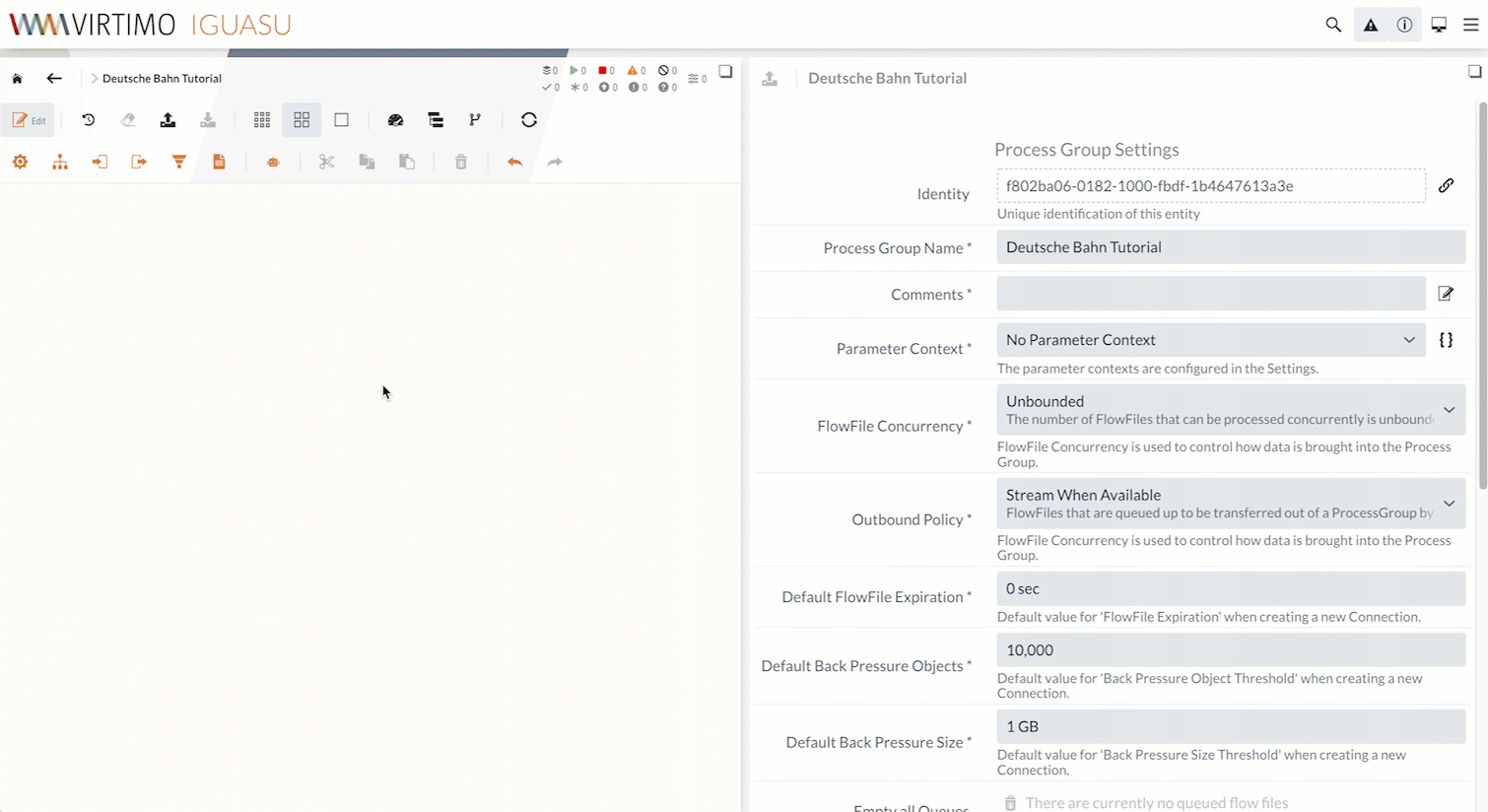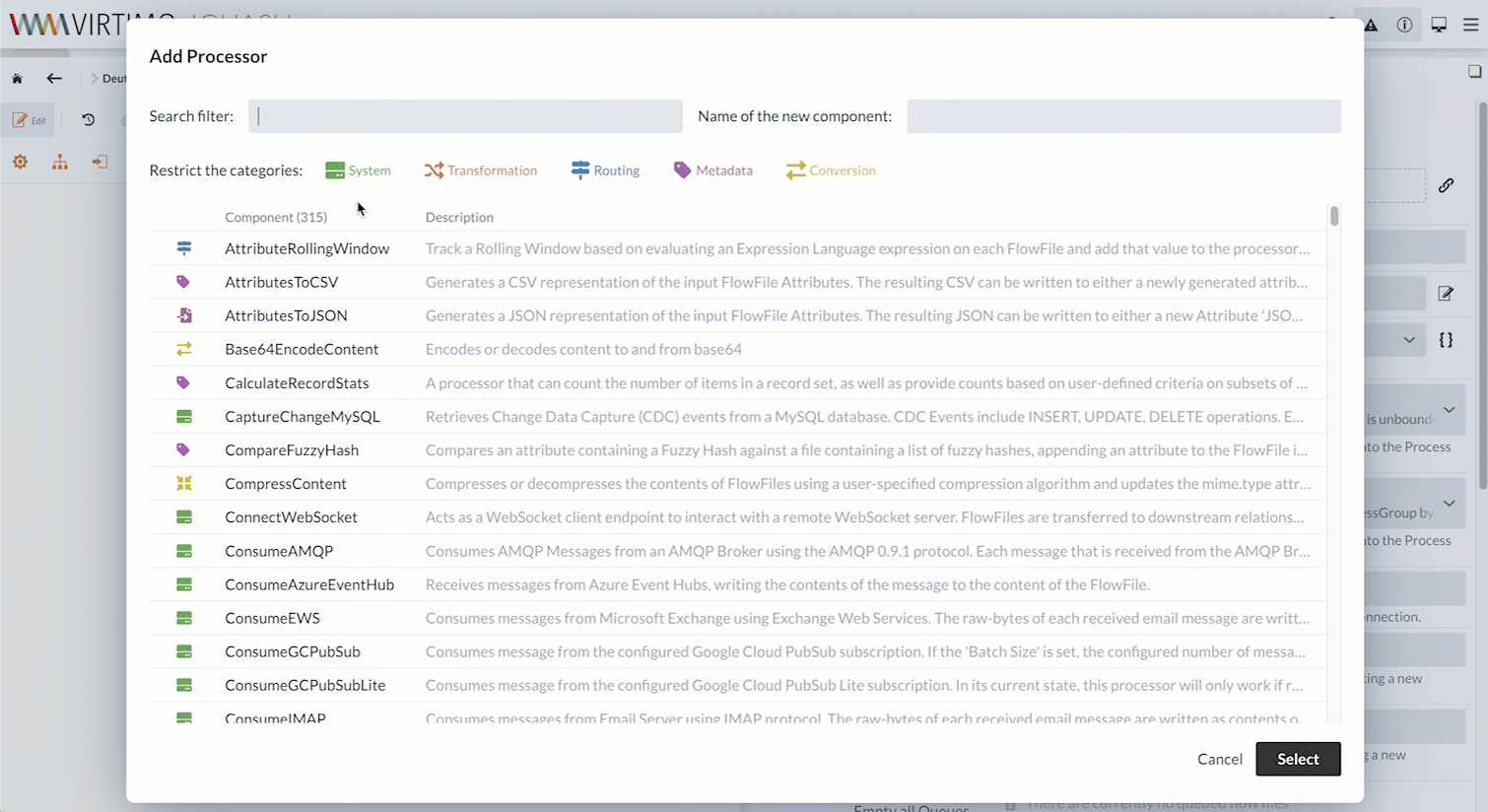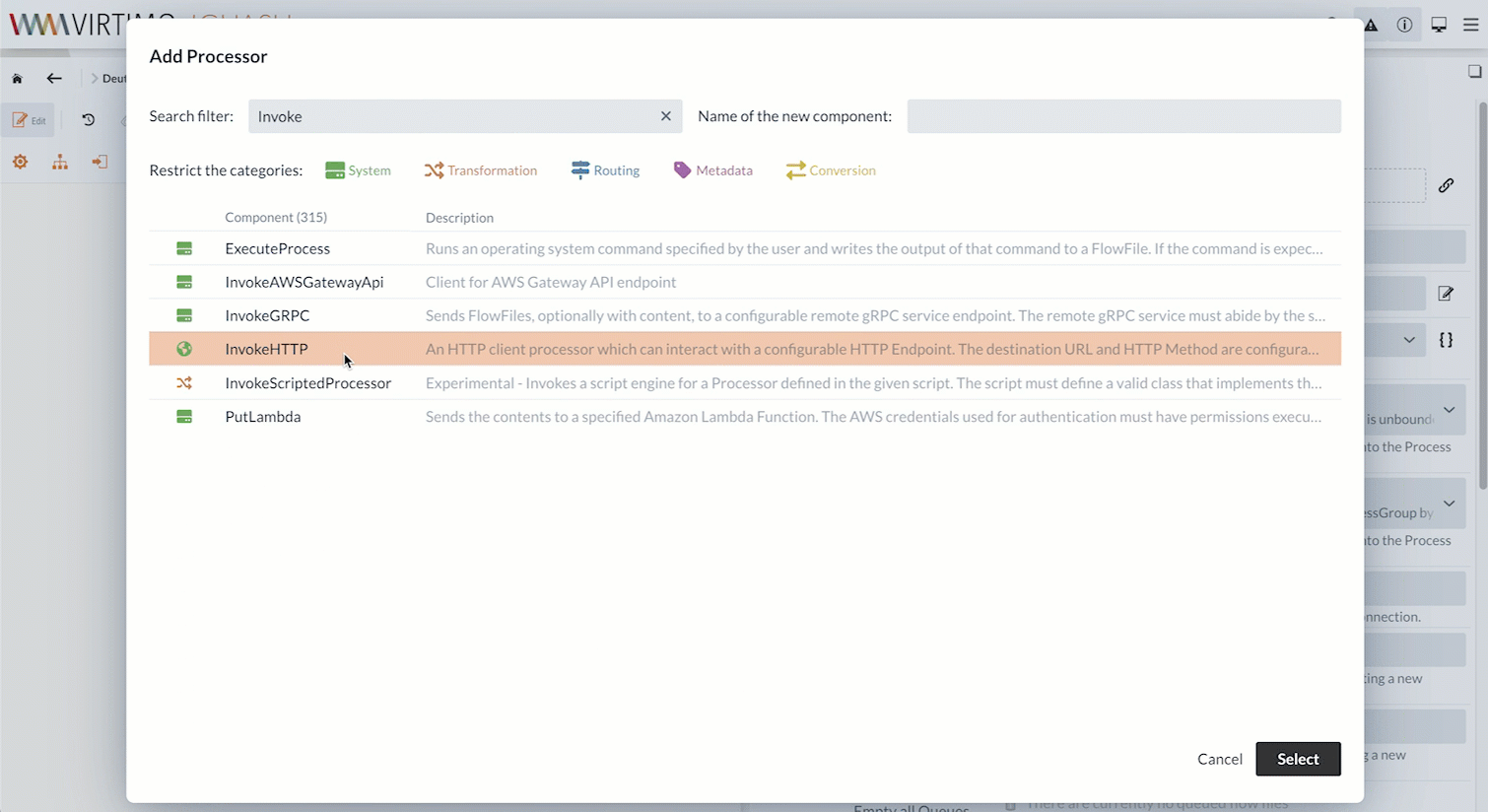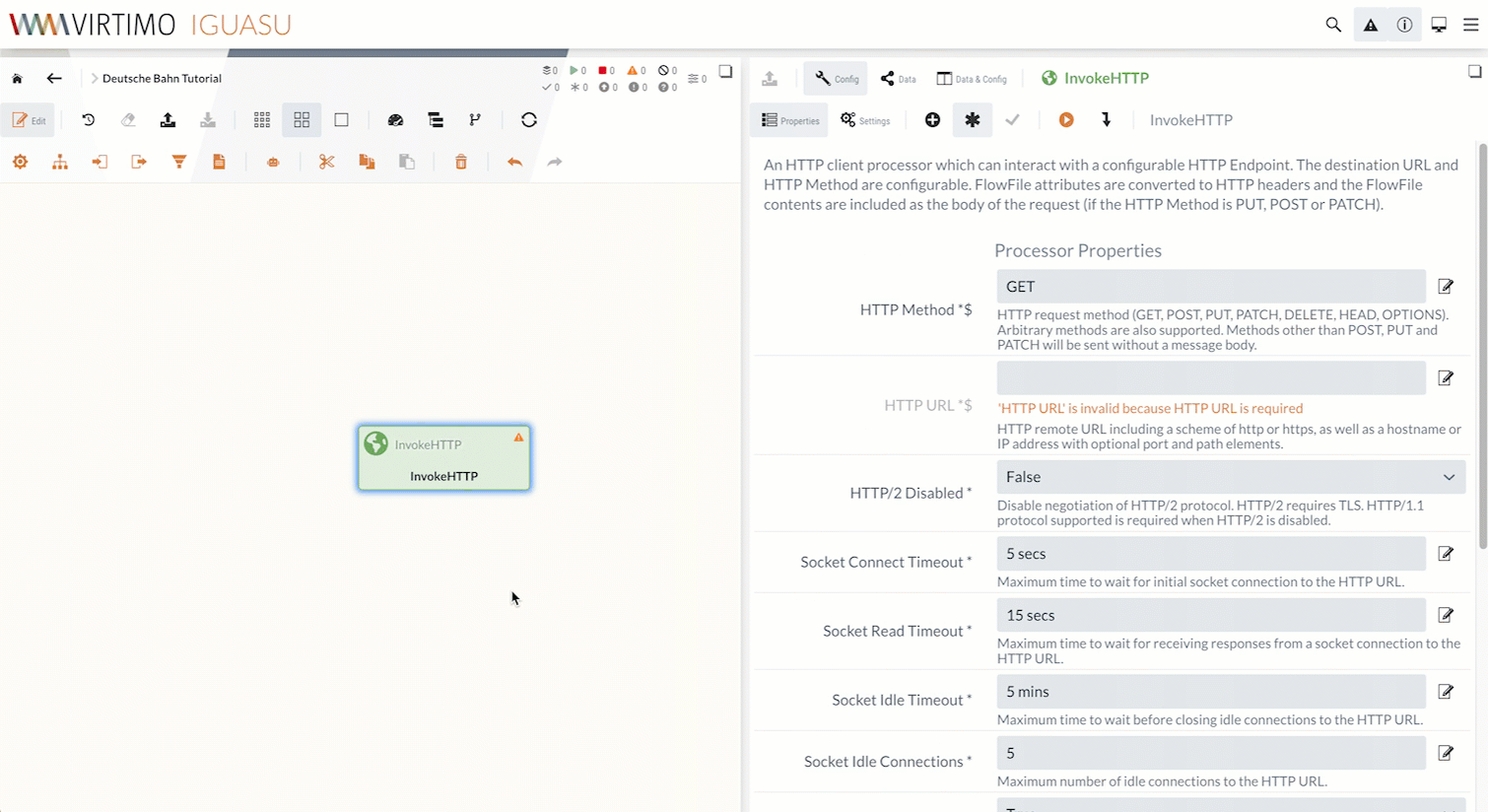
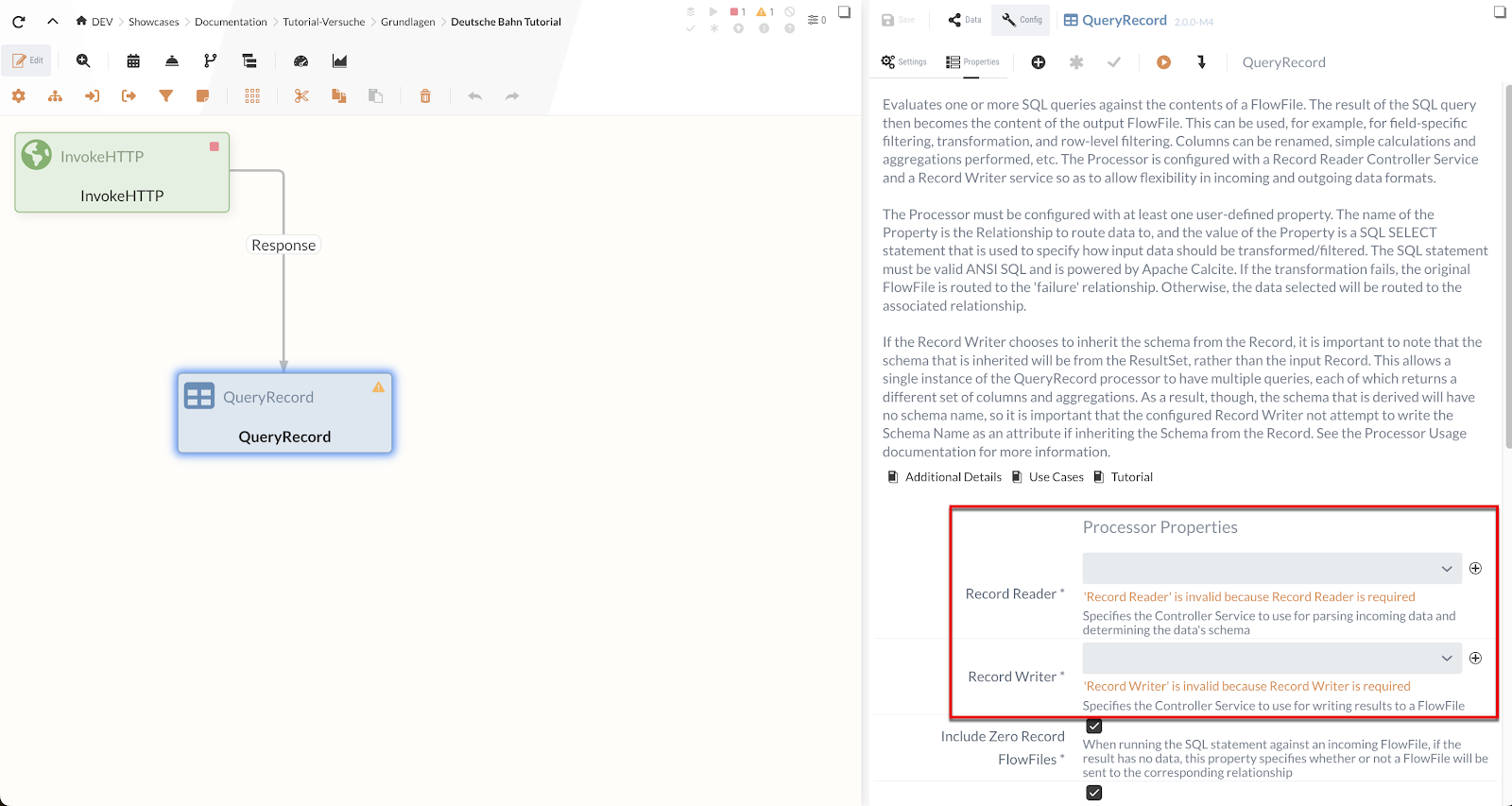
IGUASU validiert die Processor Konfiguration und zeigt im Moduleditor, welche Properties/Settings noch vervollständigt werden müssen.
Die noch nicht fertig konfigurierten Processors werden im Diagramm mit einem gelben Warndreieck (![]() ) markiert.
) markiert.
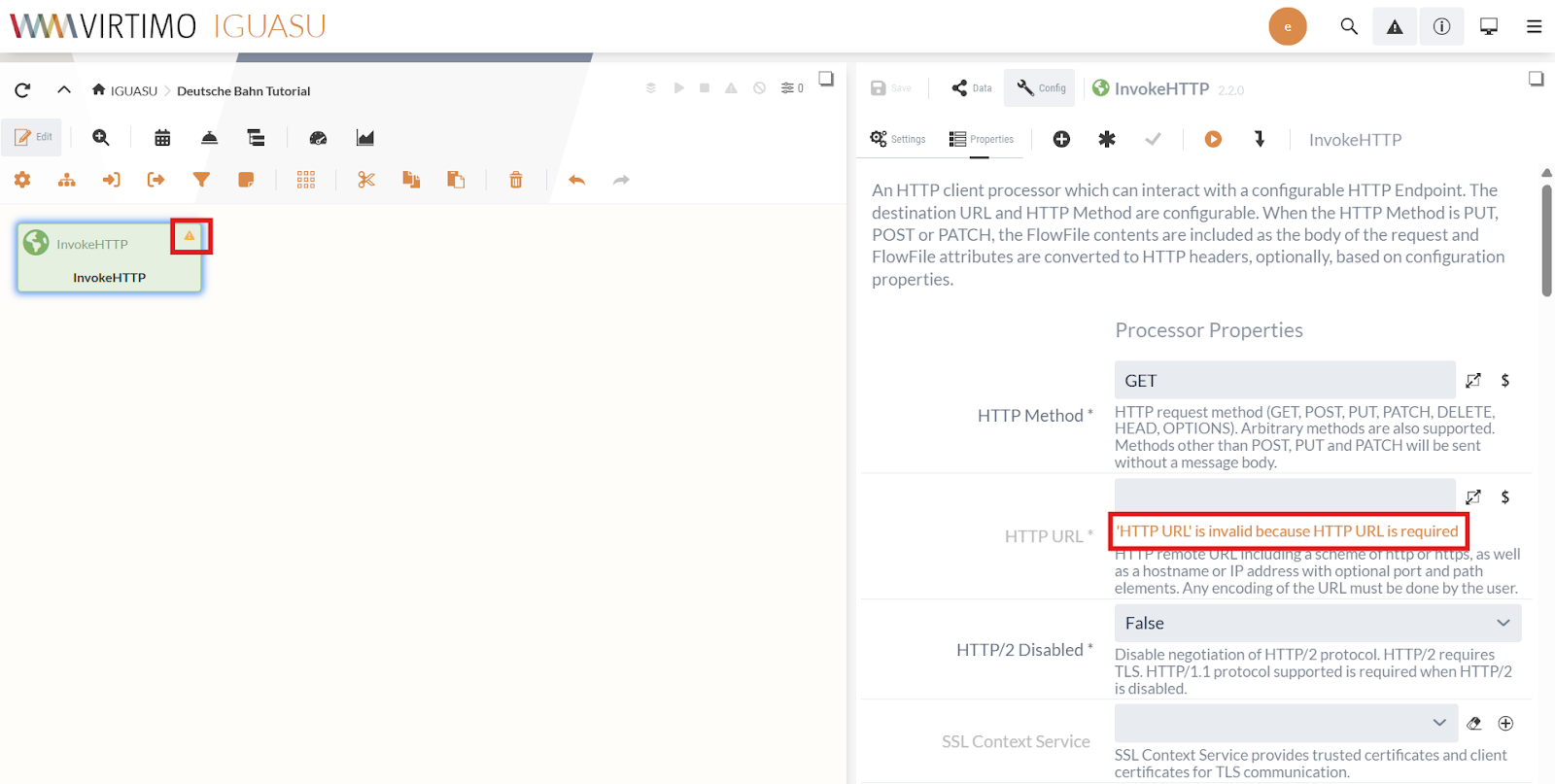
Fehler zu einem Feld werden direkt unter dem Feld angezeigt, wie auf dem obigen Screenshot für das Feld "HTTP URL" zu erkennen ist.
In den Processor Properties setzen wir die HTTP URL auf die URL der CSV:
https://docs.virtimo.net/de/iguasu-docs/user-guide/_attachments/tutorial-files/D_Bahnhof_2020_alle.csv
Der Request Type ist schon standardmäßig auf GET eingestellt, daher müssen wir in den Properties nichts weiter ändern.
In den Processor Settings setzen wir Run Schedule auf "60 sec", damit wir jede Minute nach Updates prüfen.
Für die Aufgabenstellung würde auch "1 day" genügen - der Scheduler startet immer neu, wenn der Processor über das Kommando "Start" in den Zustand RUNNING gesetzt wird.
Im Falle eines erfolgreichen Requests (2xx Status Code), wird die Relation Response ausgelöst und die heruntergeladene Datei entlang des Pfades als FlowFile weitergeleitet. Standardmäßig werden alle Relationen automatisch terminiert.
Wird eine Relation genutzt, um eine Verknüpfung zu einem anderen Element im Diagramm zu erstellen, wird diese automatische Terminierung aufgehoben.
In diesem Tutorial können wir alle nicht verwendeten Relationen unverändert terminieren lassen.

Unser InvokeHTTP Processor ist soweit fertig. Er holt die CSV-Datei und leitet diese über die Response Relation weiter. Die Erstellung des Processors, den wir mit dieser Response Relation verbinden, ist unter 1.2 QueryRecord Processor (Bahnhöfe filtern) beschrieben.
Isolierte Processor Ausführung
IGUASU bietet die Möglichkeit, Processors isoliert von der Ausführung im gesamten Flows laufen zu lassen und damit die konfigurierten Eigenschaften zu testen.
Dabei wird die gesetzte Konfiguration verwendet, ohne sie zu speichern.
Zwischen den Ausführungen kann sie beliebig verändert werden.
Wir nutzen die Ausführung des InvokeHTTP Processors jetzt, um zu sehen, ob die Liste der Bahnhöfe unter der angegebenen URL erreichbar ist und wie die zurückgegebenen Daten aussehen.
Die Ausführung im isolierten Zustand kann durch den  -Button im Moduleditor gestartet werden.
-Button im Moduleditor gestartet werden.
Nach der Ausführung wird die Ausgabe des Processors in der unteren Hälfte des Konfigurationsbereichs eingeblendet. Man kann nun die FlowFiles betrachten, die über die jeweilige Relation geschickt werden.
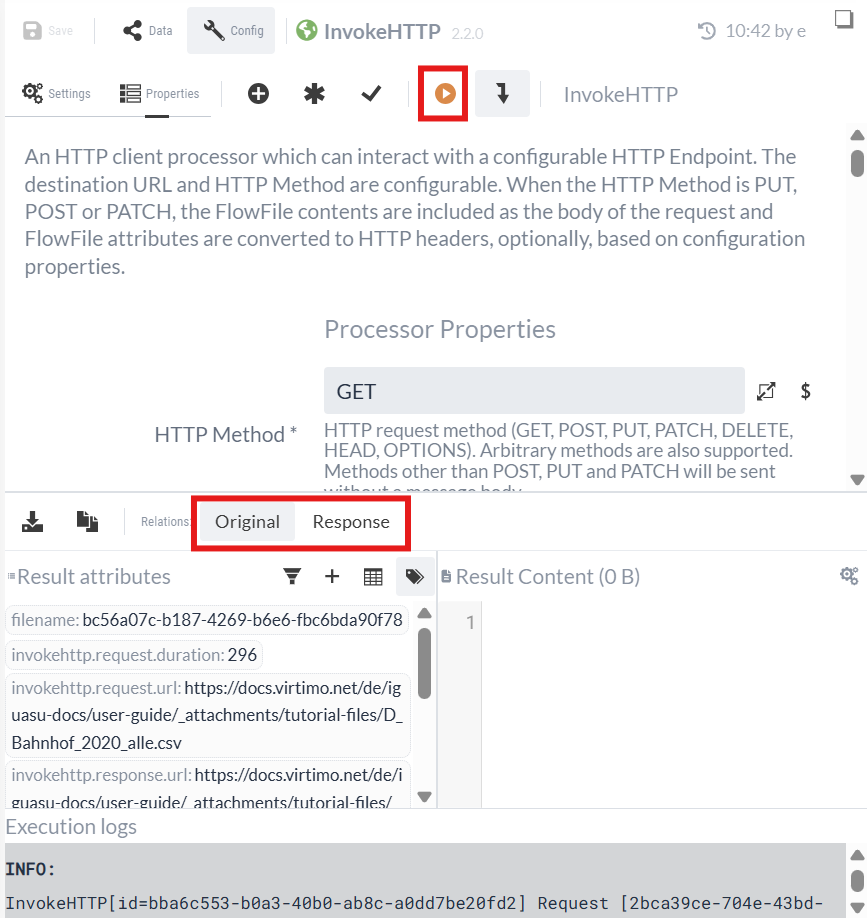
Der Processor konnte die CSV-Datei erfolgreich herunterladen.
Wir wählen die Response Relation aus:
-
In "Result content" sehen wir die heruntergeladene CSV-Datei.
-
In "Result attributes" stehen die Attribute des HTTP Response sowie weitere Standard-Attribute.
Wir können feststellen, dass die erste Zeile die Header enthält und die Daten mit einem Semikolon getrennt werden. Aus den Daten ist zu entnehmen, dass uns die Spalte "Status" die Information über die neuen Stationen verrät. Die neuen Stationen werden mit "neu" markiert.
Wir werden im weiteren Verlauf dieses Tutorials noch ein Beispiel für den Einsatz der Testausführung betrachten (siehe Isolierte Prozessausführung (Fortführung)).
1.2 QueryRecord Processor (Bahnhöfe filtern)
In diesem Abschnitt werden wir einen Processor anlegen, der die CSV-Datei entgegennimmt und nach neuen Bahnhöfen filtert.
Wir wissen aus der Testausführung, in welchem Format die Daten vorliegen und müssen den nachfolgenden Processor für die Verarbeitung bestimmen.
Einer der Processors, den wir für unser Anliegen verwenden können, ist der QueryRecord Processor.
|
Es ist nützlich, zu wissen, welche Art von Processors es gibt und wie sie arbeiten. Sie können sich hierfür die Liste der verfügbaren Processors anschauen und nach Schlagwörtern suchen. |
Der QueryRecord Processor selektiert über SQL-Queries den Content eingehender FlowFiles. Dazu müssen die Daten in einem Format vorliegen, dass NiFi als Records interpretieren kann - das CSV-Format gehört dazu.
Über das SQL kann man dann filtern, transformieren oder aggregieren.
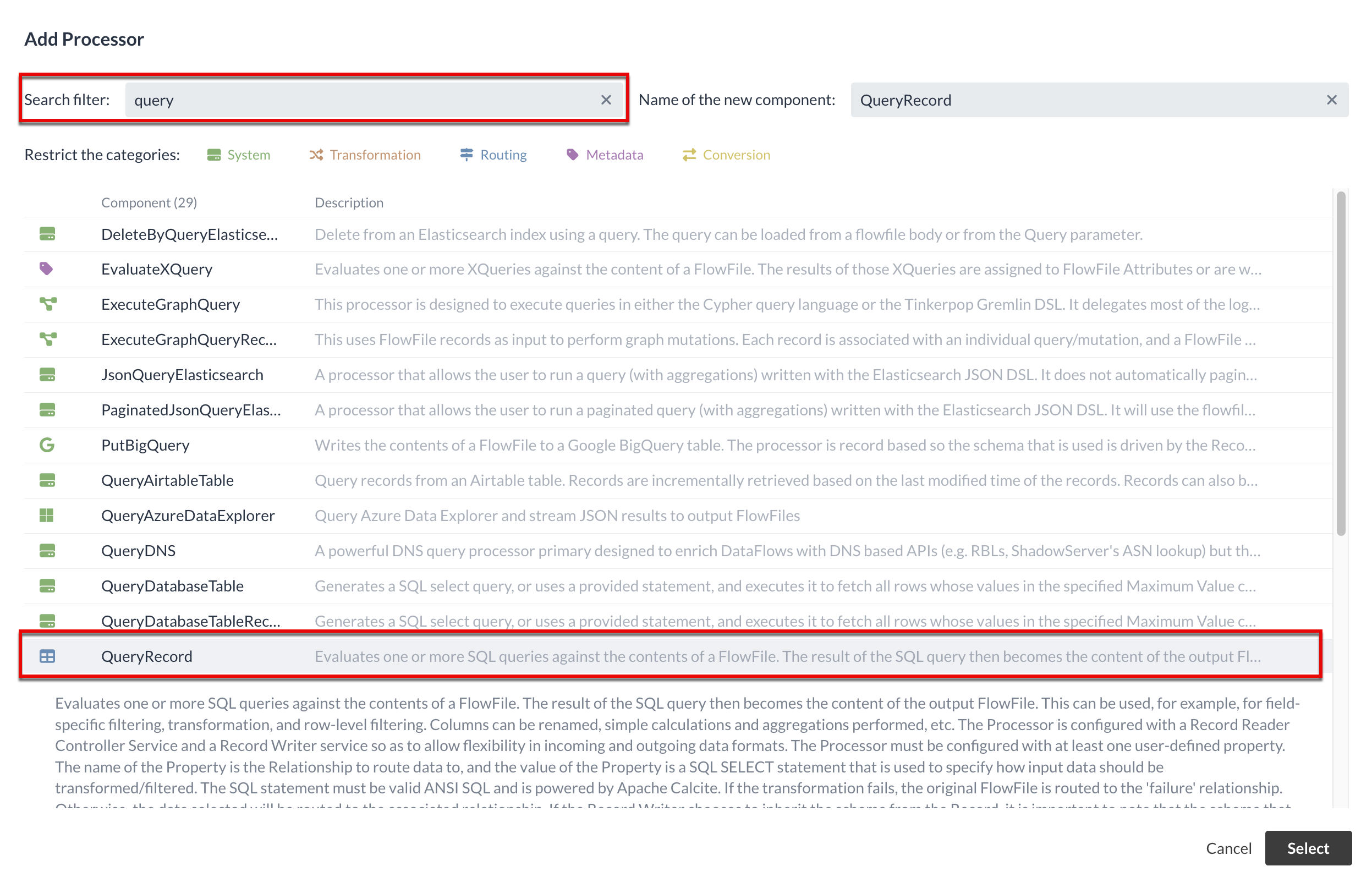
Die Ergebnisse der Queries werden als FlowFiles entlang einer selbstdefinierten Relation weitergeschickt.
Zuerst werden wir den Processor ins Diagramm einfügen und ihn mit der Response Relation des InvokeHTTP Processors verbinden.
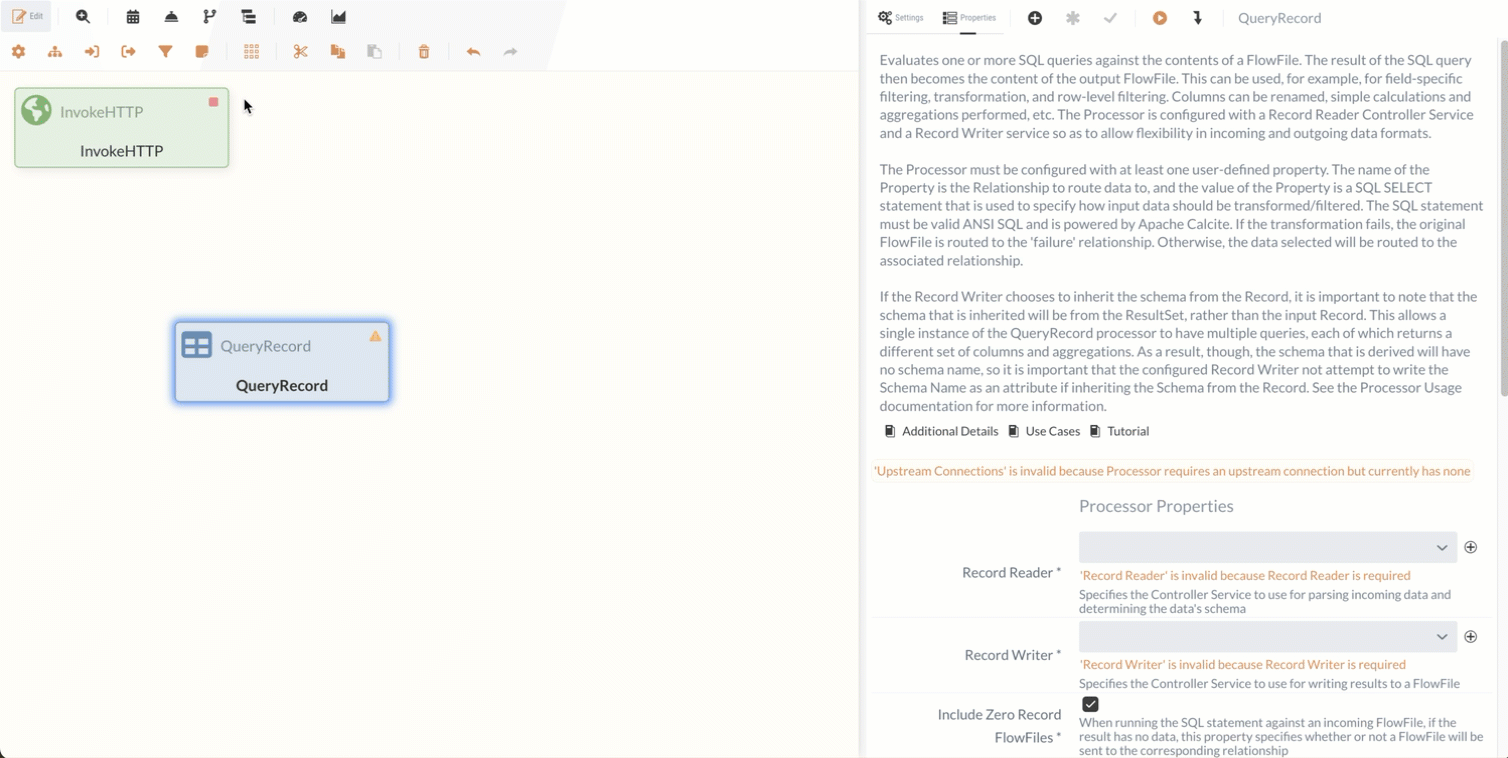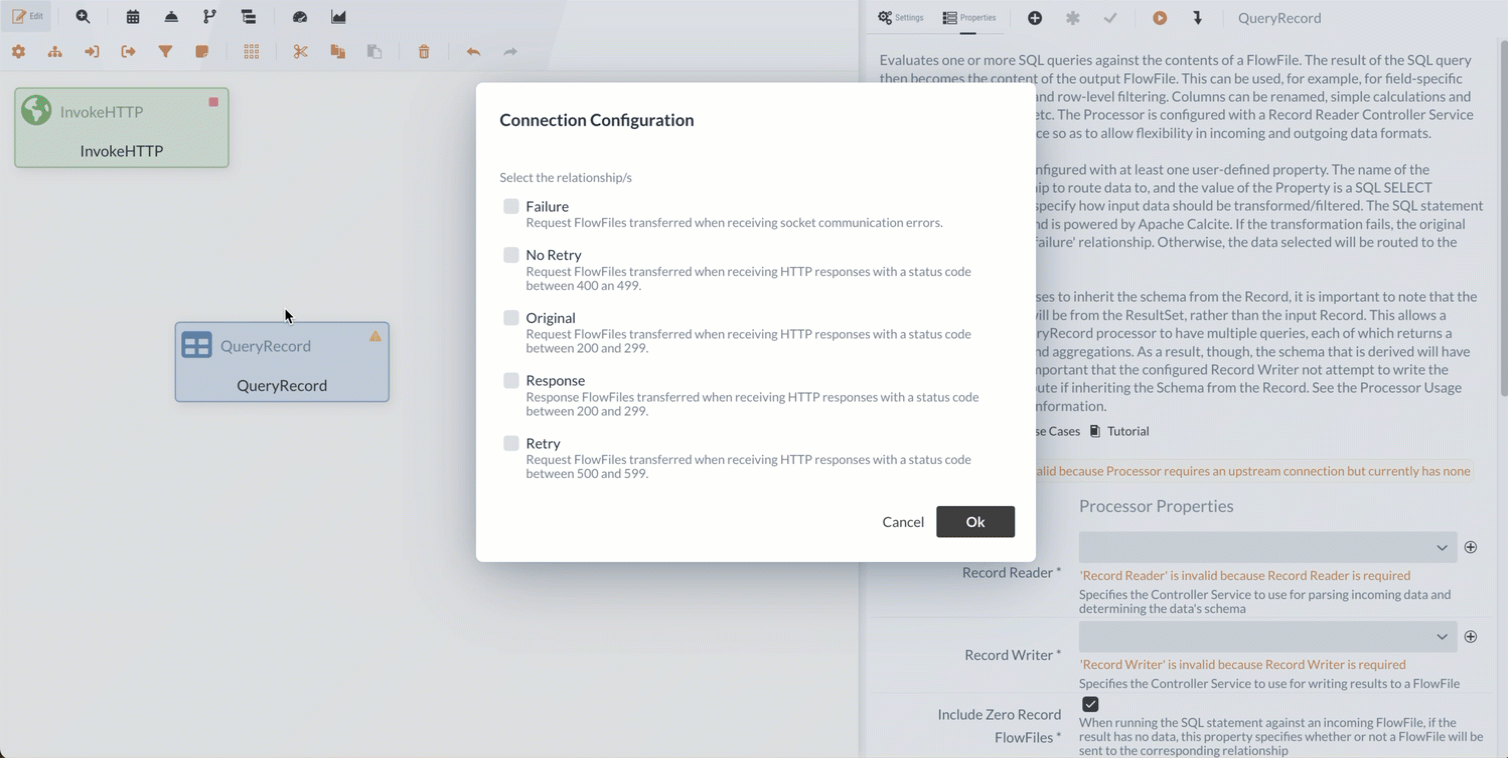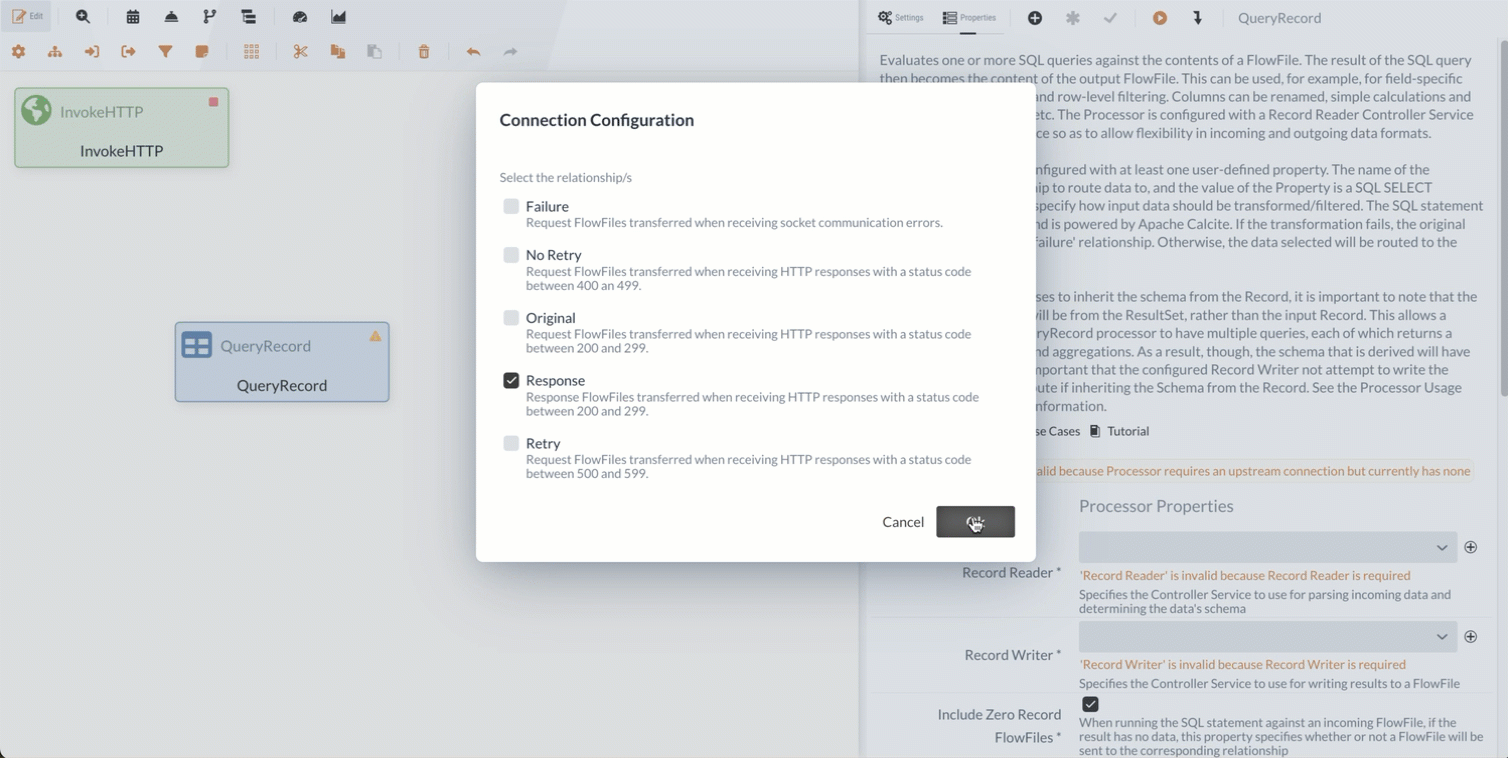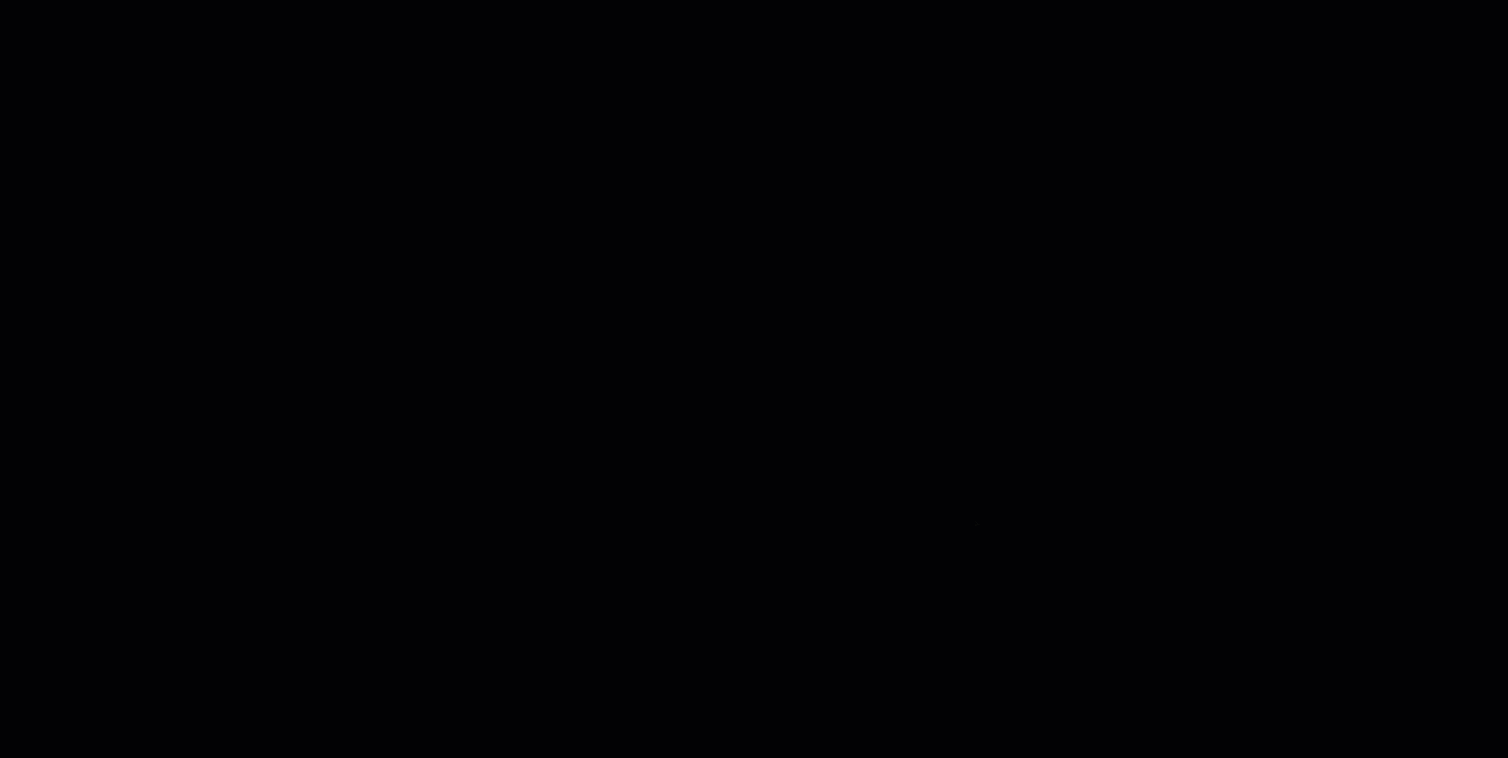
Als Nächstes müssen wir den QueryRecord Processor konfigurieren, damit er mit den eingehenden Daten wie gewünscht umgeht.
Controller Services
Bevor wir den QueryRecord Processor vollständig konfigurieren können, müssen wir uns mit Controller Services beschäftigen. Controller Services sind wiederverwendbare Komponenten in IGUASU, die zentrale Dienste für Prozessoren oder andere Services bereitstellen. Beispiele hierfür sind das Lesen/Schreiben bestimmter Datenformate oder die Verwaltung von Datenbankverbindungen.
Sie werden auf Ebene der Process Group konfiguriert und können dann von allen Processors innerhalb dieser Process Group oder in untergeordneten Process Groups genutzt werden. Der Vorteil liegt in der zentralen Verwaltung und Wiederverwendbarkeit dieser Konfigurationen.
Der QueryRecord Processor selbst ist unabhängig vom Ein- und Ausgangsformat der Daten. Er benötigt daher zwei Hilfskomponenten:
-
Einen Record Reader Controller Service:
Dieser liest die eingehenden Daten (z.B. CSV) und bereitet sie für den Processor auf. -
Einen Record Writer Controller Service:
Dieser nimmt die verarbeiteten Daten entgegen und schreibt sie in das gewünschte Zielformat (z.B. XML).
Das Eingangsformat des Record Reader und das Ausgangsformat des Record Writer müssen dabei nicht identisch sein. Somit eignet sich ein Processor mit Record Reader und Record Writer, wie zum Beispiel QueryRecord, neben seiner eigentlichen Funktion auch gut dazu, Daten von einem Format in ein anderes zu übertragen.
Der QueryRecord Processor bekommt vom InvokeHTTP Processor Daten im CSV-Format, wie wir z.B. in der Testausführung festgestellt haben.
Um diese Daten einzulesen, eignet sich ein CSV Reader Controller Service als Record Reader.
Im folgenden Schritt wollen wir die gefilterten Daten jedoch als XML zur Verfügung stehen haben, daher benutzen wir als Record Writer einen XMLRecordSetWriter Controller Service.
Diese Controller Services legen wir jetzt in den Einstellungen der Process Group an.
Damit der Processor Zugriff auf den jeweiligen Service bekommt, muss sich dieser entweder in derselben oder darüberliegenden Process Group befinden.
Folglich haben alle Processors Zugriff auf die Services, die in der Root Process Group liegen.
Um ins Konfigurationsmenü der Process Groups zu gelangen, klicken wir auf das ![]() -Icon.
Daraufhin wird der Process Groups-Baum auf der linken Seite aufgelistet.
-Icon.
Daraufhin wird der Process Groups-Baum auf der linken Seite aufgelistet.
Ansonsten wird die aktuelle Process Group immer als letztes Element im Pfad neben dem ![]() -Icon dargestellt.
-Icon dargestellt.
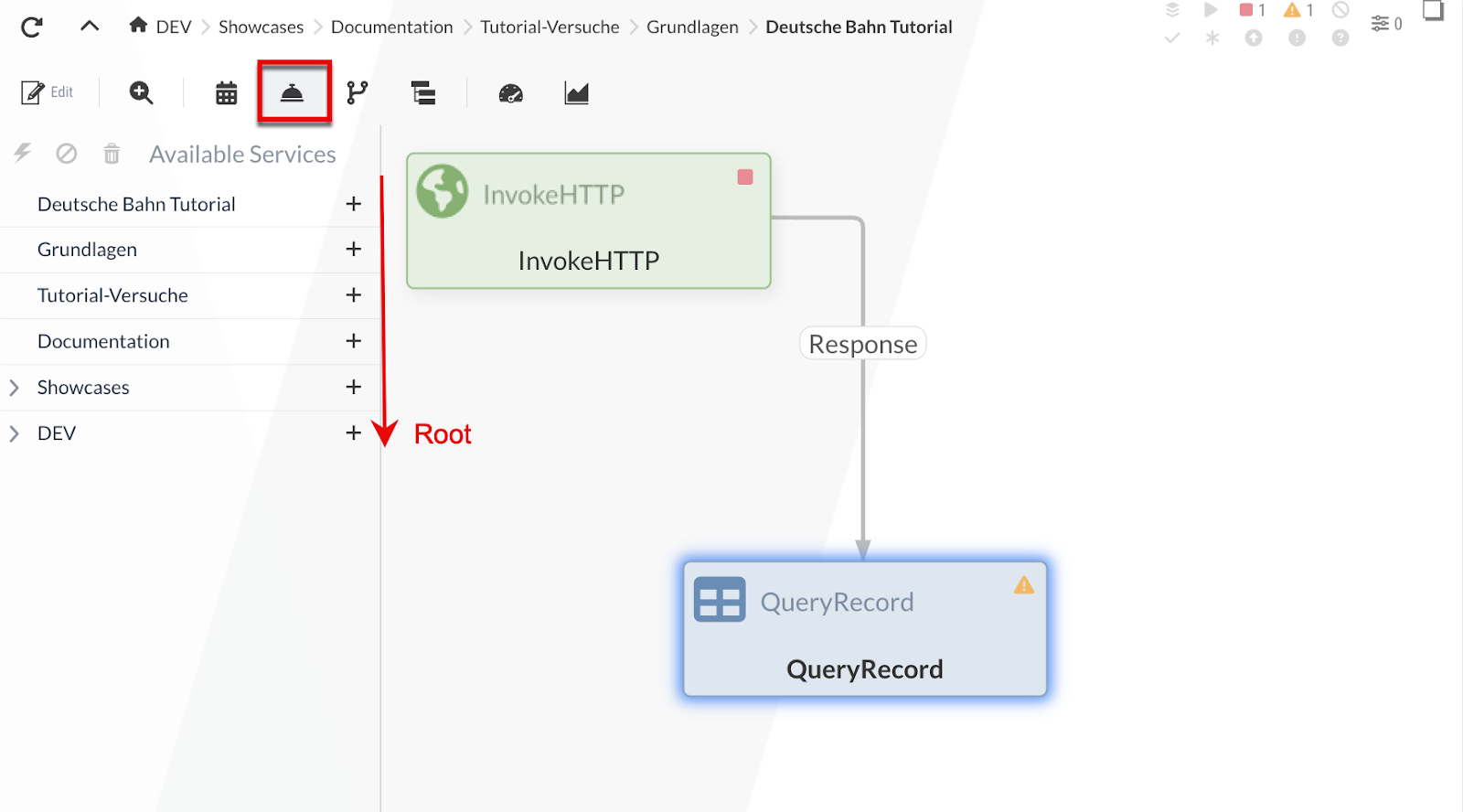
Der Process Groups-Baum beginnt oben mit der aktuellen Process Group und endet mit dem "[Root]". Über das -Icon können wir einen Controller Service zur Process Group hinzufügen:
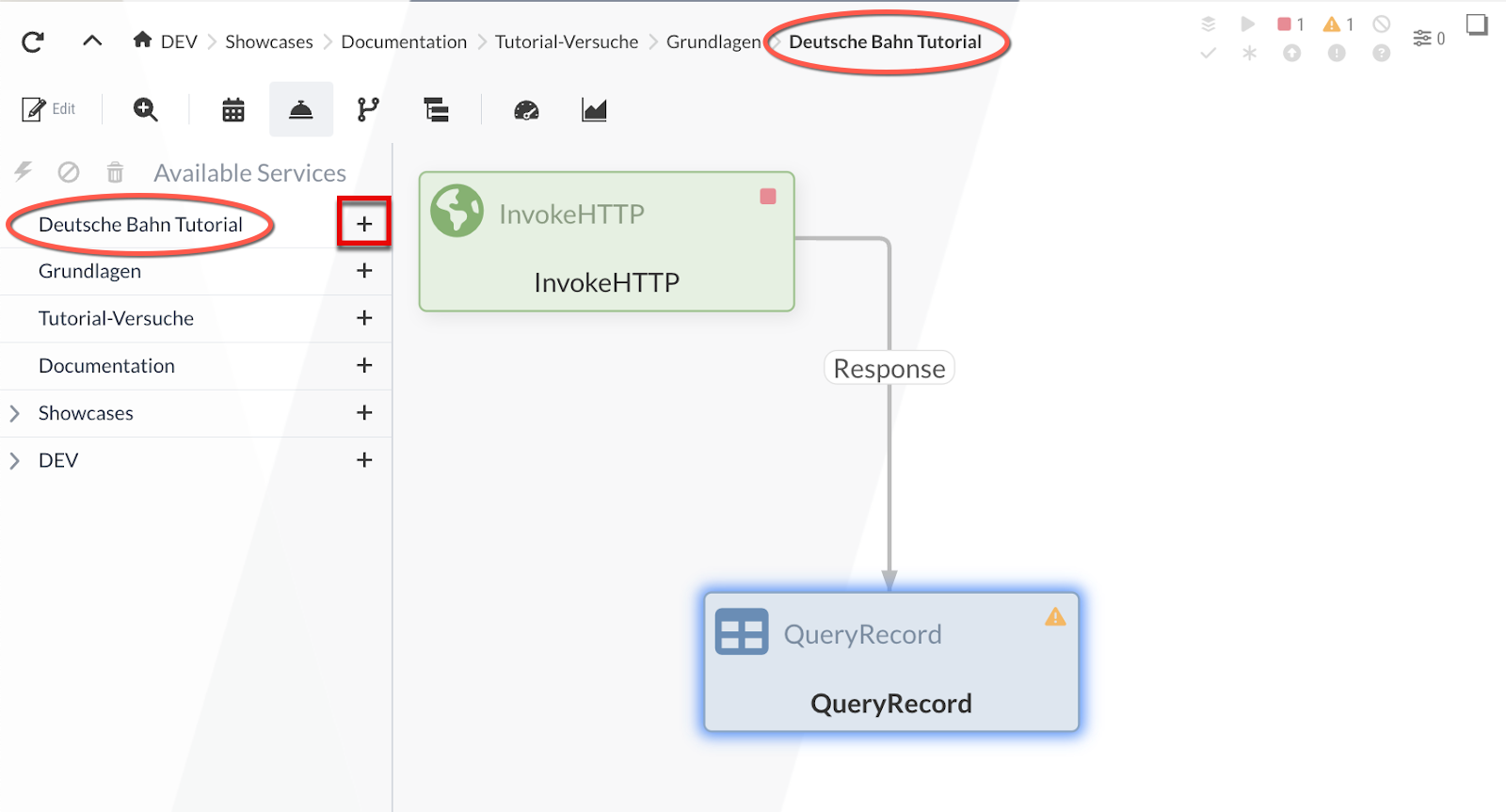
Für unser Beispiel werden wir einen CSVReader und XMLRecordSetWriter zur aktuellen Process Group hinzufügen. Nach dem Einfügen haben wir die Möglichkeit, die Services zu starten/stoppen bzw. zu konfigurieren.
In der Konfiguration des CSVReaders müssen wir das Trennzeichen (Value Separator) als Semikolon spezifizieren, die restlichen Einstellungen können auf den Standardwerten bleiben.
Beim XMLRecordSetWriter müssen wir einen Namen für den Root-Knoten und seine Einträge spezifizieren (Root Tag & Record Tag), beispielsweise mit "Root" und "Record". Diese Angaben sind optionale Felder, die durch das Stern-Icon in der Toolbar ein- und ausgeblendet werden können.
Die restlichen Einstellungen können unverändert bleiben.
Wir sind also fertig mit der Konfiguration der Record Reader/Writer und können sie nun aktivieren, sodass sie von anderen Processors eingesetzt werden können.
Die Services werden jeweils mit dem ![]() -Button gestartet:
-Button gestartet:
|
Die Controller Services werden nicht periodisch ausgeführt und haben auch keine Relationen, da sie nicht direkt im Flow hängen.
Sie werden von Processors, Reporting Tasks oder anderen Controller Services verwendet. |
Nun werden wir den CSVReader dem QueryRecord Processor als Record Reader und den XMLRecordSetWriter als Record Writer zuweisen (siehe Processor Properties).
Die Ein- und Ausgabedatentypen wurden definiert.
Daher verbleibt die Aufgabe, die Query zu schreiben, die die neuen Bahnhöfe ermittelt.
Bevor wir die Query schreiben, möchten wir an dieser Stelle ein weiteres Feature von IGUASU betrachten, welches uns bei der Erstellung und Konfiguration von Processors behilflich sein wird. Die Fortführung des Tutorials findet unter SQL Query statt.
Datenflow Analyze - Inspection Panel (Exkurs)
IGUASU bietet die Möglichkeit, die von den Processors verarbeiteten bzw. die durch die Processors geflossenen Daten anzuzeigen. Um dies in unserem Beispiel zu demonstrieren, müssen wir den Flow kurzzeitig starten, um Daten zu generieren.
Für diesen Zweck kann durch einen Rechtsklick auf einer leeren Fläche das Kontextmenü genutzt werden. Dort können wir alle Processors der aktuellen Process Group in den Zustand RUNNING versetzen, indem das Kommando Start ausgewählt wird. Anschließend können alle Processors über das Menü ebenfalls gestoppt werden.

Wenn nun die Event-Tabelle eingeschaltet ist (-Button in der Toolbar), wird durch das Selektieren eines Processors, der bereits Daten verarbeitet hat, unterhalb des Diagramms der Verlauf aller vom Processor in der Ausführung erstellten Events angezeigt. Solch ein Event beschreibt einen Verarbeitungsschritt bezogen auf FlowFiles im Processor.
Beispiele solcher Events:
-
Fork: Das FlowFile wurde von einem anderen FlowFile abgeleitet
-
Route: Das FlowFile wird entlang einer Relation weitergeleitet (mit Begründung)
-
Drop: Das FlowFile wird nicht mehr weiterverarbeitet
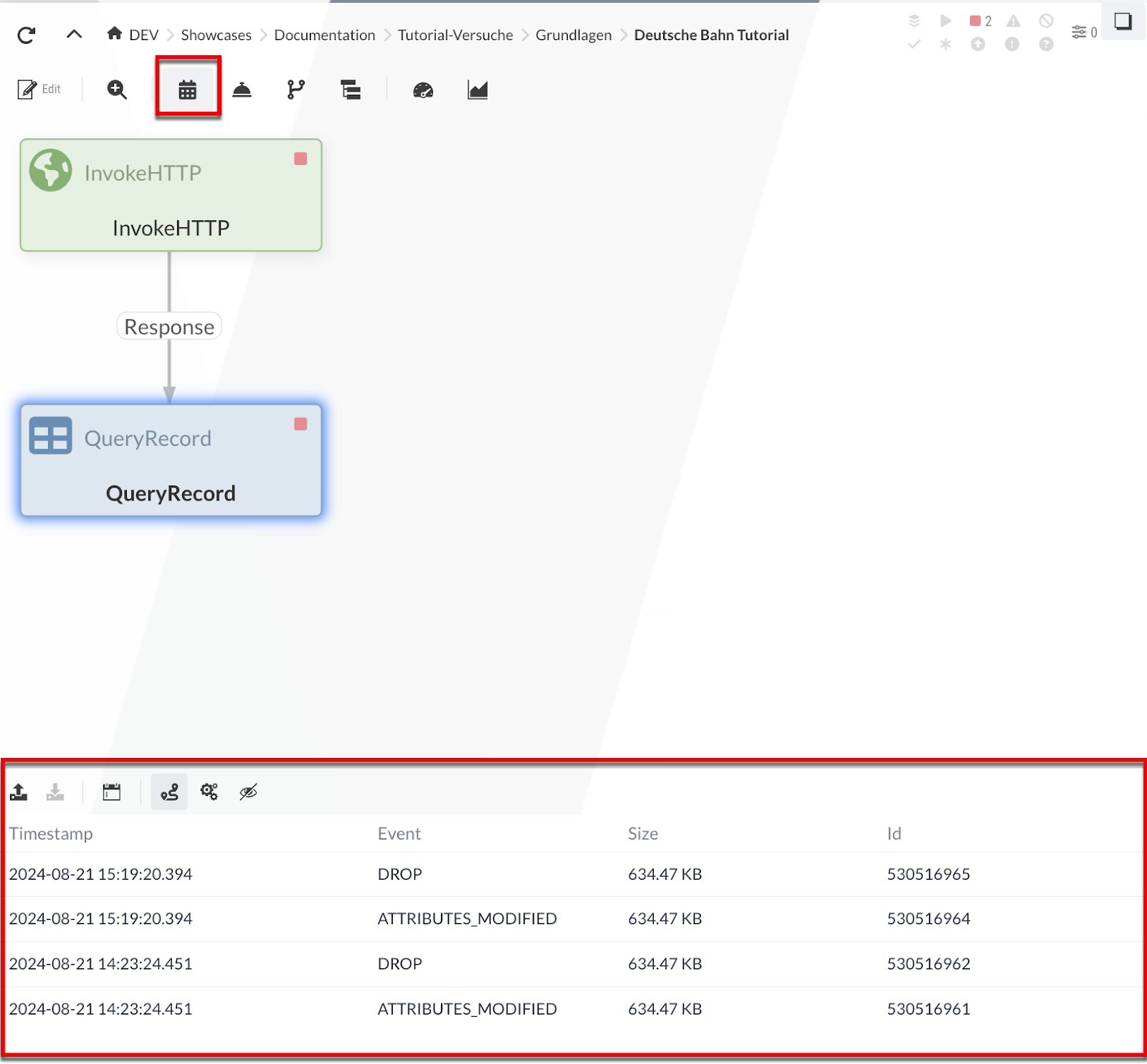
Nach der Selektion eines Events wird der Verlauf der dazugehörigen Processor-Ausführungen im Diagram hervorgehoben.
Die Nummern stellen die Ausführungsreihenfolge dar - man sieht, welche Processors in welcher Reihenfolge ausgeführt wurden.
Hier sind es genau die zwei Processors, die wir bisher haben.
In komplexeren Szenarien ist auch sichtbar, welche Zweige genommen wurden.
Zudem wird nach der Selektion eines Events das Inspection Panel geöffnet.
Dieses enthält detaillierte Informationen über das Event sowie die Eingangs- und Ausgangs-Daten der Ausführung des Processors.
Die Eingangsdaten können auch für die Testausführung eines Processors verwendet werden (siehe Isolierte Prozessausführung (Fortführung)).
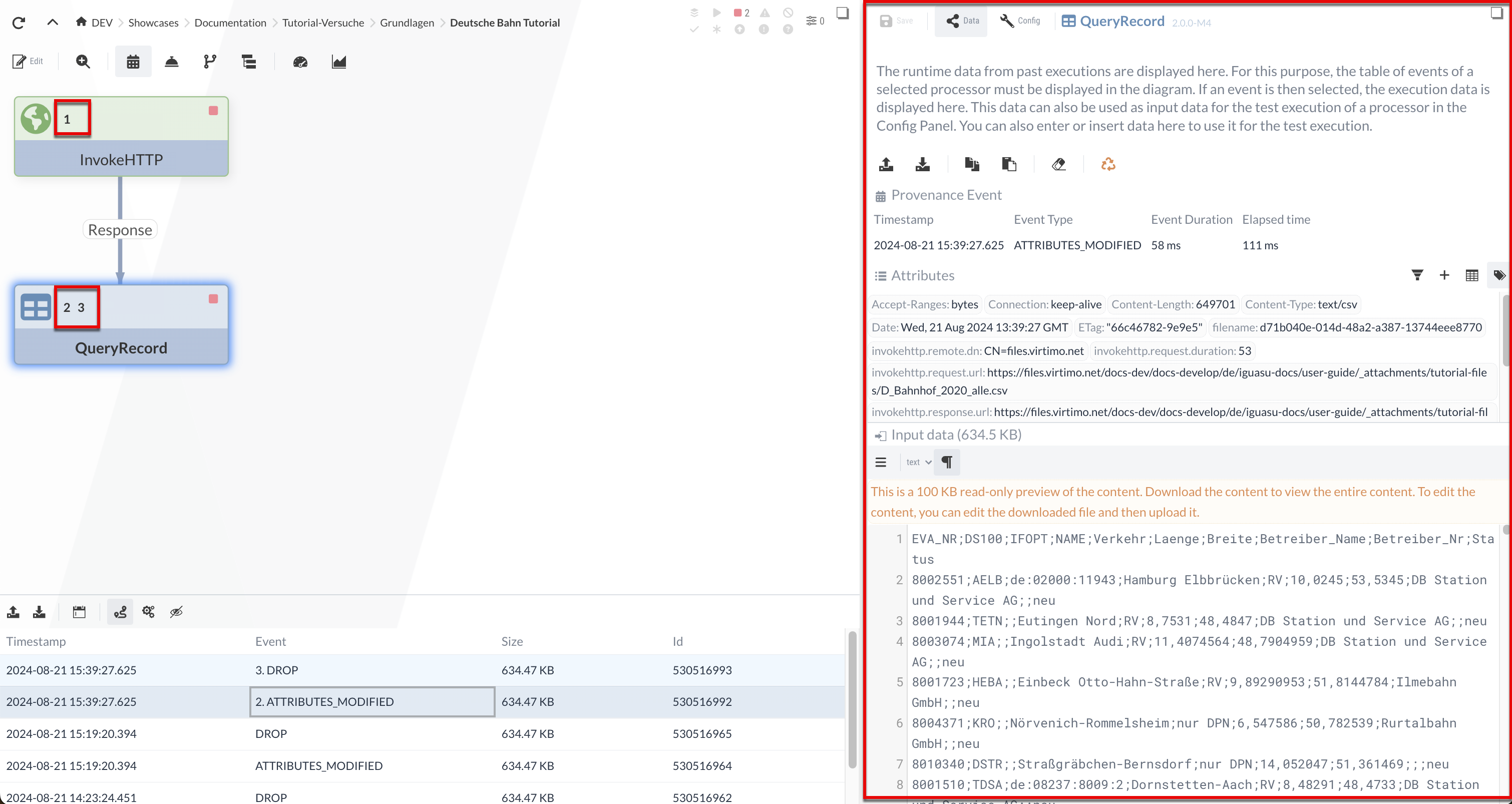
Die Daten des ausgewählten Events bleiben im Inspection Panel gespeichert und können für Testausführungen verwendet werden. Wir selektieren das Event im QueryRecord Processor und es wird der CSV-Input im Inspection Panel angezeigt - diesen Input werden wir später (Isolierte Prozessausführung (Fortführung)) für die Testausführung verwenden.
SQL Query
Nun wollen wir die CSV-Datei Mithilfe eines SQL-Befehls nach neuen Einträgen filtern.
Im Folgenden sind zwei Beispieleinträge aus dem CSV dargestellt - die neuen Bahnhöfe werden im Feld "Status" mit dem Wert "neu" gekennzeichnet.
EVA_NR,DS100,IFOPT,NAME,Verkehr,Laenge,Breite,Betreiber_Name,Betreiber_Nr,Status
8002551,AELB,de:02000:11943,Hamburg Elbbrücken,RV,10.0245,53.5345,DB Station und Service AG,,neu
8000032,NS,de:09662:28058,Schweinfurt Hbf,RV,10.212919,50.035313,DB Station und Service AG,5742,Der erste Eintrag mit der EVA_NR "8002551" ist somit ein neuer Bahnhof und der zweite mit der Nummer "8000032" nicht.
Mit der folgenden Query werden wir nach den neuen Bahnhöfen filtern:
SELECT * FROM FLOWFILE WHERE Status = 'neu'Die Queries werden als Dynamic Property mit dem -Button hinzugefügt.
Die Namen der ausgehenden Relationen entsprechen den Namen der Properties.
Wir legen eine Dynamic Property mit dem Namen "neue_alle" und der Query als Wert an.
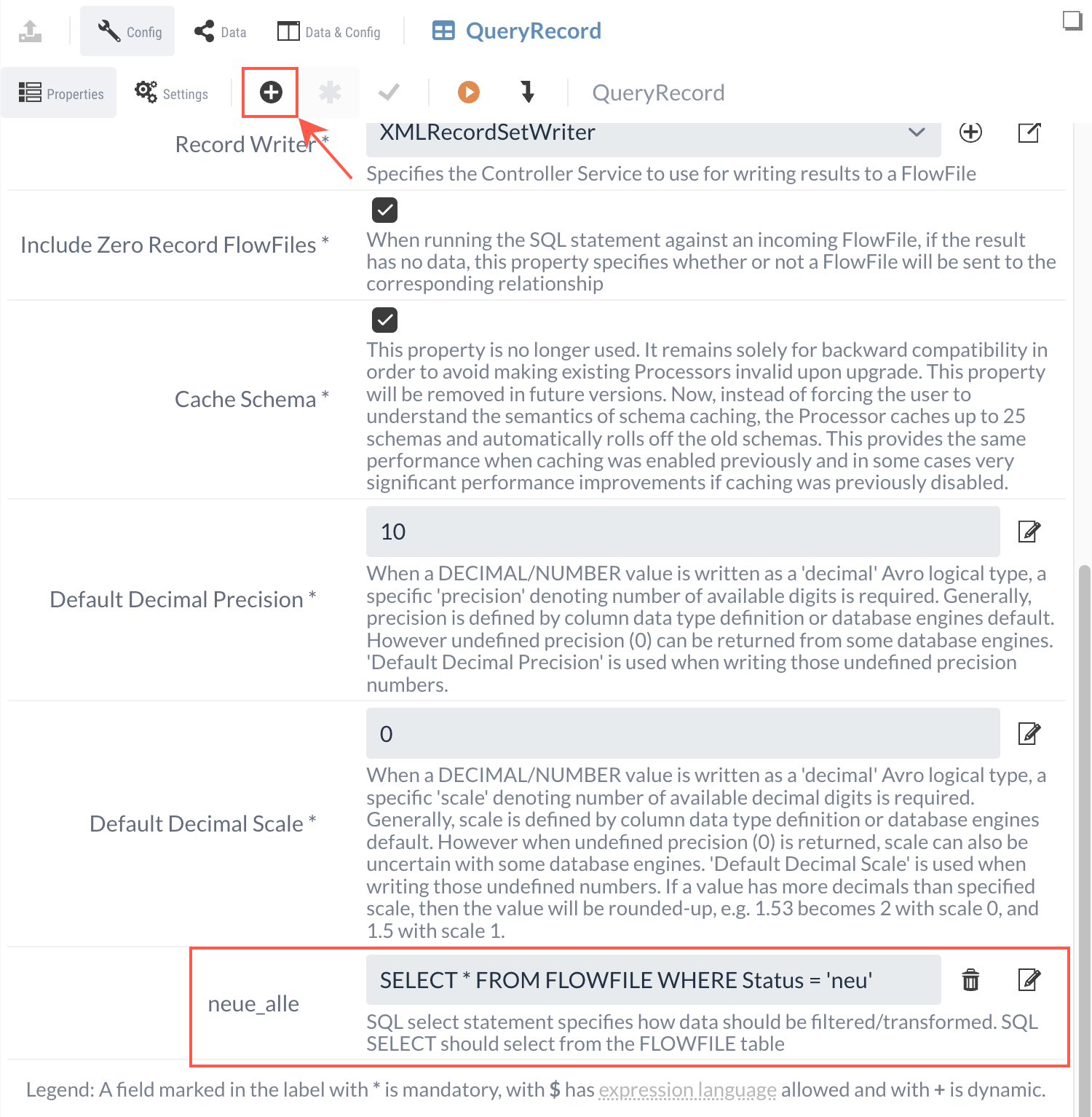
Nun gibt es eine neue Relation mit dem Namen "neue_alle", die das Ergebnis der Query als FlowFile an weitere Processors weiterleitet.
In den Processor Settings konfigurieren wir die nicht benötigten Relationen wieder zur automatischen Terminierung.
An dieser Stelle ist die Konfiguration von QueryRecord abgeschlossen und wir könnten zum nächsten Processor übergehen.
Allerdings bietet es sich an, zu prüfen, ob alles richtig konfiguriert wurde und der Processor sich erwartungsgemäß verhält.
Isolierte Prozessausführung (Fortführung)
Im Folgenden werden wir die Korrektheit des QueryRecord Processors mit der bereits erwähnten Testausführung überprüfen (siehe Isolierte Processor Ausführung). Wir werden sehen, ob der Processor die Daten erwartungsgemäß verarbeitet, indem wir ihn auf ein FlowFile ausführen und das Ergebnis prüfen.
|
Beim InvokeHTTP Processor war die Bereitstellung von Eingangsdaten (einem FlowFile) nicht nötig, da er zum Abrufen der Daten von einer URL keine Eingabedaten notwendig sind. |
Um die Daten einer früheren Ausführung zu verwenden, selektieren wir einen der Events in der Tabelle unter dem Diagramm.
Wird dann die isolierte Ausführung ausgewählt, werden die Ergebnisse im Konfigurationsbereich angezeigt.
|
Die Tabelle erscheint, wenn man einen Processor im Diagramm selektiert und dieser schon einmal im Zuge des Flows ausgeführt wurde. Die isolierten bzw. Testausführungen spielen dabei keine Rolle. |
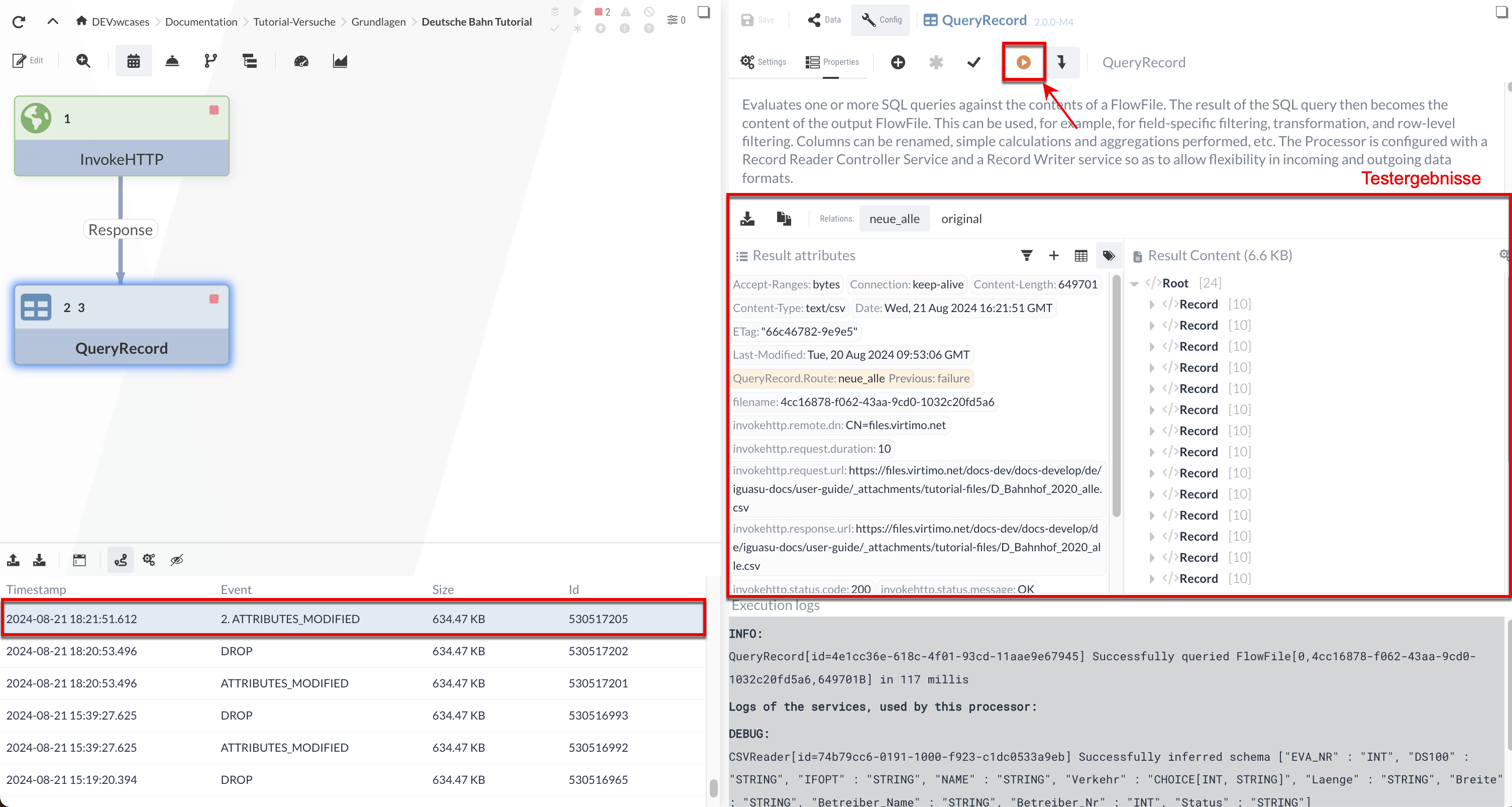
Nach der Ausführung über den -Button sehen wir, dass der QueryRecord Processor für zwei Relationen die Ergebnisse zeigt:
-
In der "originalen" Relation stehen die originalen Eingabedaten - hier schickt also der Processor einfach die Eingabedatei weiter.
-
In der "neue_alle"-Relation werden die durch die SQL-Query selektierten Stationen (mit Status='neu') als XML ausgegeben.
Die Record-Tags des XML haben wir im XMLRecordSetWriter spezifiziert. Wenn wir durch den Result content scrollen, können wir uns vergewissern, dass nur die neuen Bahnhöfe gefiltert worden sind.
Wir können die Eingabedaten für den Test auch manuell anpassen/eingeben. Um dies zu zeigen, merken wir uns vorerst, dass in Result content der erste neue Bahnhof die ID "8002551" besitzt.
Wir können überprüfen, ob korrekt gefiltert wird, wenn wir den Status dieses Bahnhofs in den Eingangsdaten auf alt ändern.
Dazu müssen wir ins Data-Panel wechseln und im Input data bei der Bahnhof ID 8002551 den Status von "neu" auf "alt" ändern.
Da in unserem Fall die Datei zu groß ist, müssen wir die Datei herunterladen und in einem Editor unserer Wahl bearbeiten.
Nachdem wir den Status geändert haben, können wir die Datei wieder hochladen.
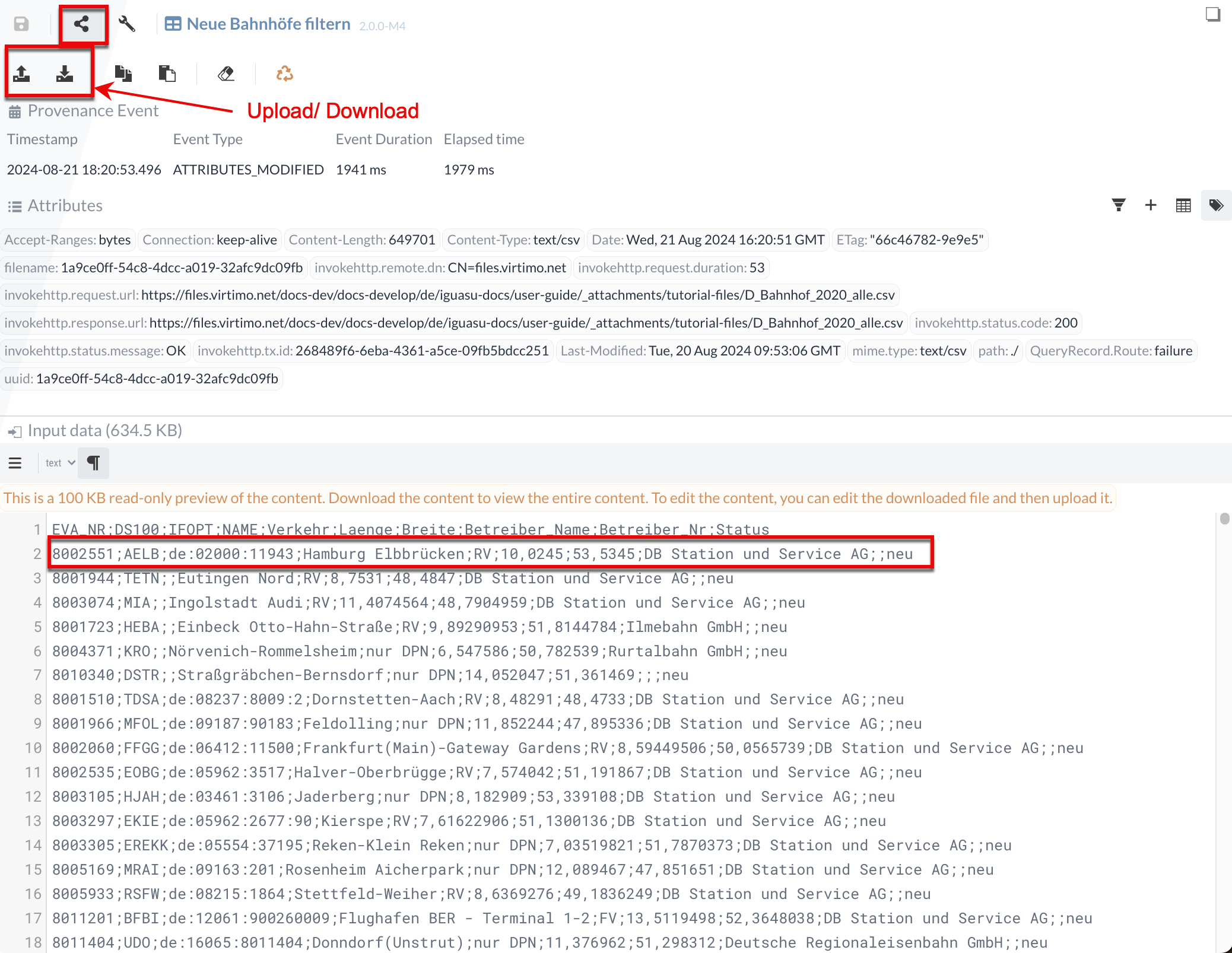
Nach erneutem Ausführen sehen wir, dass die "neue_alle"-Relation nun keinen Eintrag mit der Bahnhof-ID "8002551" enthält.
Genauso können wir die Query beliebig ändern und z.B. auf alle Trierer Bahnhöfe filtern:
SELECT * FROM FLOWFILE where NAME LIKE '%Trier%'.Man kann also in IGUASU mit den Processors experimentieren und ihre Ausgaben testen, bevor man sie im möglicherweise komplexen Flow ausführt.
1.3 UpdateAttribute Processor (Dateinamen setzen)
Unser Ziel für Teil 1 ist es, ein komprimiertes XML mit Informationen über alle neuen Bahnhöfe abzuspeichern. Diese komprimierte XML könnten wir dann als Datei über verschiedene Processors auf externe Systeme übertragen. Zum Beispiel könnten wir mit dem PutEmail Processor die Datei als Anhang mitgeben oder aber mit PutSFTP auf einem Fileserver ablegen. In vielen Fällen übergeben wir dabei den Content als Datei.
Wir können den Namen dieser Datei bestimmen, in dem wir das Attribut “filename” setzen, das von den Processors dann ausgelesen wird.
Auch, wenn wir in diesem Tutorial den Content nur per IGUASU-Benutzeroberfläche herunterladen, wird auch der Name der Download-Datei durch dieses Attribut gesetzt.
Mit dem UpdateAttribute Processor können wir beliebige Attribute der FlowFiles anlegen und ändern.
Wir fügen einen UpdateAttribute Processor zum Diagramm hinzu und verbinden diesen mit der "neue_alle"-Relation aus dem QueryRecord Processor.
Das Anlegen neuer Attribute über den UpdateAttribute Processor erfolgt durch das Erstellen einer dynamischen Property.
Der Name dieses dynamischen Properties entspricht dann dem Namen des Attributs, das angelegt (oder geändert) werden soll.
Der Inhalt entspricht dann dem (neuen) Wert.
Den Inhalt möchten wir auf das aktuelle Datum setzen. Da sich das Datum täglich ändern wird, können wir den String nicht statisch eintragen, sondern müssen diesen dynamisch passend zum Tag generieren.
Dafür nutzen wir die Expression Language, mit der wir dynamische Funktionen in Ausdrücke für Properties eintragen können.
Die Expression ${now():format('yyyy-MM-dd')} würde ein aktuelles Datum wie "2020-11-19" ergeben.
Da wir die Datei als XML abspeichern wollen, können wir an die Expression noch das statische ".xml" anhängen und mit einem Prefix "Stations_" versehen: Stations_${now():format('yyyy-MM-dd')}.xml.
Das ergibt dann "Stations_2020-11-19.xml".
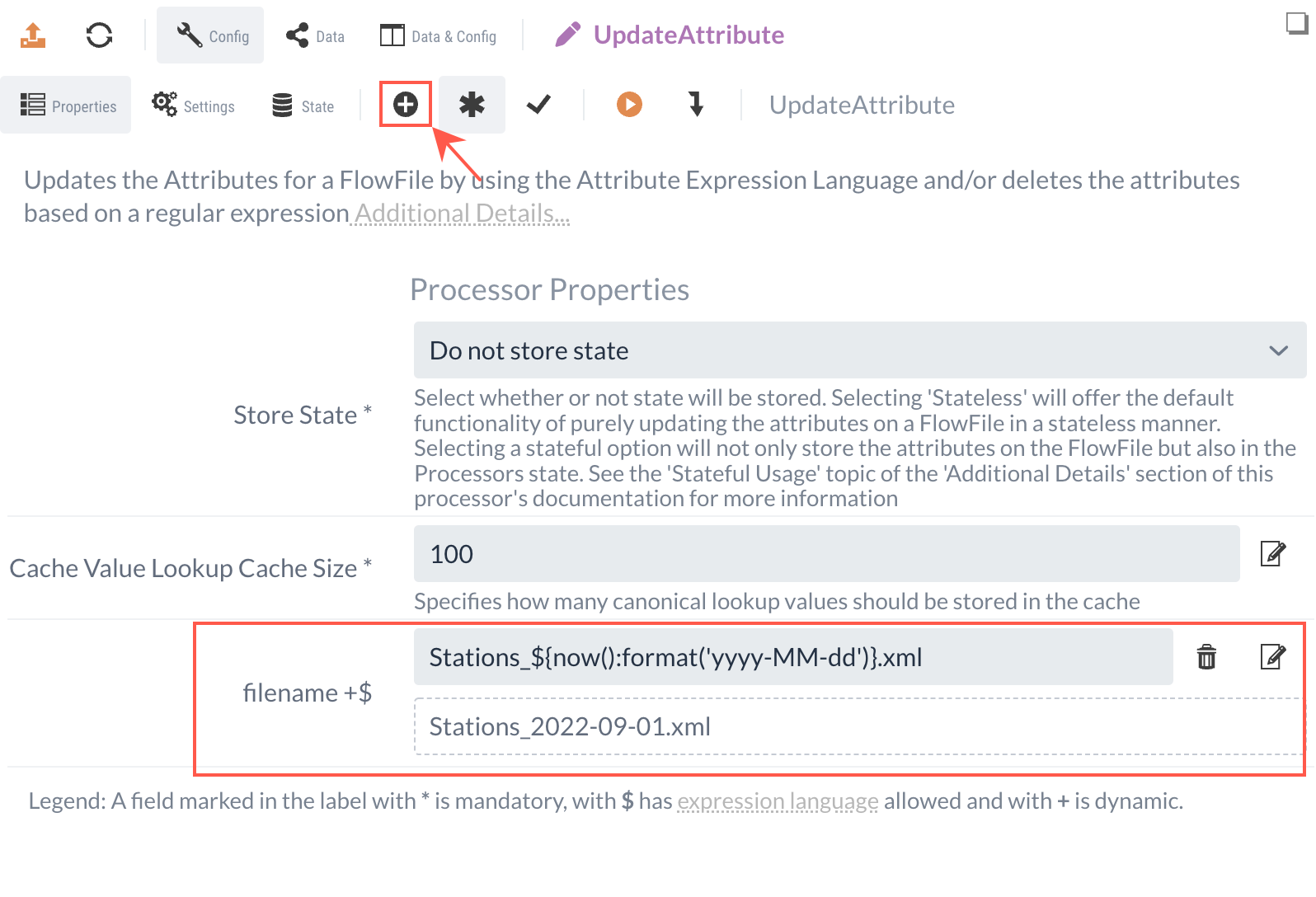
Der UpdateAttribute Processor ändert nur die definierten Attribute des FlowFiles, nicht den Content. Das resultierende FlowFile mit dem nun angepassten "filename" werden wir an den nächsten Processor weiterleiten.
1.4 CompressContent Processor (Komprimieren)
In diesem Schritt komprimieren wir das FlowFile. Dazu setzen wir den CompressContent Processor ein. Wir müssen den Processor zum Diagramm hinzufügen und nur noch die Relation aus dem UpdateAttribute anlegen.
In den Einstellungen sollten wir:
-
den Haken bei "Update Filename" setzen, damit die Dateiendung des Attributs "filename" entsprechend angepasst wird
-
die Kompressionsrate auf 9 setzen
-
das Format auf "gzip" setzen.
Das komprimierte FlowFile leiten wir an den letzten Processor weiter.
1.5 Ablauf testen
Wir können uns vorstellen, dass die komprimierte XML-Datei im nächsten Schritt an ein externes System weitergeleitet oder aber zur Sicherung abgespeichert wird.
Wir simulieren diesen Schritt, indem wir die Analyse Tools von IGUASU nutzen, um den Content herunterzuladen, die Datei zu entpacken und schlussendlich das XML zu betrachten.
Dafür lassen wir die FlowFiles in ein Funnel-Element laufen, um sie später zu betrachten.
Ein Funnel ist ein einfaches Element in IGUASU. Es dient dazu, FlowFiles aus einer oder mehreren eingehenden Verbindungen zu sammeln, beendet aber den Datenfluss an dieser Stelle. Das ist nützlich, um Zweige eines Flows abzuschließen oder um FlowFiles gezielt für eine manuelle Inspektion über die Benutzeroberfläche 'aufzufangen', ohne dass ein weiterer Processor sie verarbeitet.
Durch einen Rechtsklick ins Diagramm und die Auswahl Start können wir alle Processors der Process Group starten. Wenn wir alles richtig gemacht haben, sollten wir nach kurzer Zeit sehen, dass ein FlowFile unsere Processors durchlaufen hat und nun vor dem Funnel wartet.
Wir klicken auf dieses wartende Flowfile, um auf der rechten Seite die FlowFile und eine Übersicht der Queue auf dieser Relation zu sehen.
Über das -Icon im Content-Bereich können wir den Inhalt des Contents herunterladen.
Wenn wir die Datei herunterladen, sollten wir sehen, dass der Name “Stations_[yyyy-MM-dd].xml.gz” ist - wie vorher von uns bestimmt. Die Dateiendung “.gz” weist auf eine mit gzip komprimierte Datei hin. Wenn wir die Datei entpacken und die daraus resultierende XML in einem Editor öffnen, können wir nun die neuen Bahnhöfe als XML betrachten.
Teil 2: REST Service implementieren
Um den REST Service getrennt zu pflegen, legen wir für diesen eine neue Process Group als Subgroup zur aktuellen an. Das machen wir, indem wir im Edit-Modus den -Button aus der Leiste oben auf die Diagrammfläche ziehen. Wir können die neue Process Group, die wir “Validierung per REST” nennen, mit einem Doppelklick auf das entsprechende Element aufrufen.
Unser Ziel in diesem Teil ist es, einen REST-Endpunkt zu erstellen, der Informationen zu Bahnhöfen als JSON entgegennimmt, dabei das Format überprüft und dementsprechend eine Response zurückschickt.
Um das zu realisieren, benötigen wir zuerst einen HandleHttpRequest Processor, der auf einem bestimmten Port horcht und die Anfragen entgegennimmt.
Die entgegengenommenen Anfragen werden weitergeleitet an einen ValidateJson Processor, der überprüft, ob die eingegangene Nachricht einem definierten Format entspricht.
Schlussendlich schicken wir eine Response zurück mit einem von zwei HandleHttpResponse Processors, je nachdem, ob es in einem der vorherigen Processors zu Fehlern kam oder nicht.
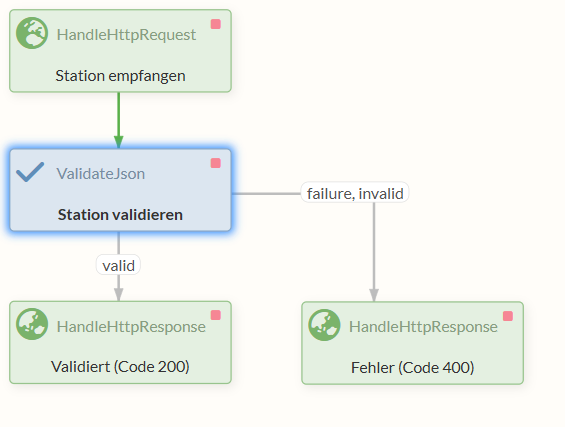
2.1 HTTP-Anfragen bearbeiten
Zunächst benötigen wir einen Processor, der die HTTP Anfragen empfängt und weiterleitet.
Dafür eignet sich der HandleHttpRequest Processor.
In der Konfiguration setzten wir den Listening Port auf "3333".
Das ist der Port, an dem der Processor auf Anfragen horchen wird.
Außerdem müssen wir einen neuen StandardHttpContextMap Controller Service anlegen, der dafür sorgt, dass die HTTP Session zwischen den Processors erhalten bleibt.
Wir legen, wie aus Teil 1 bekannt, einen neuen StandardHttpContextMap Controller Service an, diesmal jedoch innerhalb der aktuellen Process Group Validierung via REST.
Wir könnten den Controller Service auch in der Parent Process Group “Deutsche Bahn Tutorial” oder gar in der Root Process Group anlegen, da die Controller Services einer Process Group auch allen Sub-Process Groups zur Verfügung stehen.
Jedoch vermeiden wir es hier, da wir den Controller Service ausschließlich in dieser Process Group verwenden wollen.
Es bietet sich an, bei der Erstellung dieses Controller Services den Namen mit einem Prefix "REST" zu versehen, um Verwechslung mit einem anderen StandardHttpContextMap Controller Services zu vermeiden.
Die optionale Property Allowed Paths befüllen wir mit “/validate”.
Das hat zur Folge, dass der Processor nur Requests mit diesem Pfad in der URL entgegennimmt.
Alle Requests, die nicht an localhost:3333/validate gehen, werden automatisch mit einem Code 404 (Not Found) beantwortet.
Weil wir einen REST Service anbieten, an den Daten zur Überprüfung geschickt werden sollen, sollte der Client beim Senden der Daten die “POST” HTTP Methode benutzen. Daher entfernen wir die Häkchen an den Einstellungen “Allow GET”, “Allow PUT” und “Allow DELETE”, sodass nur noch “Allow POST” aktiviert ist.

Um die Anfragen zu beantworten, benötigen wir außerdem zwei weitere HandleHttpResponse Processors.
Der erste soll bei erfolgreicher Validierung dem Client einen Code 200 als Erfolgsmitteilung zurückgeben.
Der andere wiederum soll bei Auftreten eines Fehlers dies dem Client mit einem Code 400 mitteilen.
In einem realen Szenario wäre es angemessen, die unterschiedlichen Fehlerfälle (keine valide JSON übergeben, JSON Schema Validierung fehlgeschlagen) auch unterschiedlich zu beantworten und auch weitere Informationen zum Fehler zu liefern. Für dieses Tutorial beschränken wir uns auf die Response mit dem Code 400 für beide Fehlerfälle.
Wir erstellen zwei HandleHttpResponse Processors und setzen in beiden Fällen unseren "REST StandardHttpContextMap" Controller Service in das Feld HTTP Context Map.

Das Feld HTTP Status Code setzen wir entsprechend auf 200 beziehungsweise 400.

2.2 Anfragen validieren
Im nächsten Schritt wollen wir die erhaltenen JSON-Daten auf das richtige Format überprüfen. Dafür eignet sich der ValidateJson Processor, der JSONs anhand von JSON Schema validieren kann.
Ein JSON-Schema ist dabei selbst ein JSON, das Vorgaben zum Aufbau und Inhalt eines anderen JSON macht, also ein Schema definiert. Der ValidateJson Processor prüft, ob unser JSON die Vorgaben des JSON-Schemas erfüllt oder nicht.
Mit dem folgenden JSON-Schema definieren wir ein JSON Objekt, das einen Eintrag zu einem Bahnhof repräsentiert. Es hat genau drei Einträge:
-
“NR”, ein Integer
-
“NAME”, ein String
-
“CREATED”, ein String, der zusätzlich auch als Datum formatiert sein muss
{
"type": "object",
"properties": {
"NR": {
"type": "integer"
},
"NAME": {
"type": "string"
},
"CREATED": {
"type": "string",
"format": "date"
}
},
"required": ["NR", "NAME", "CREATED"]
}Dieses Schema muss in das "JSON Schema" Property eingetragen werden. Ansonsten können die Standardeinstellungen des Processors beibehalten werden.
Die resultierende Konfiguration des ValidateJson Processors sollte schlussendlich so aussehen:
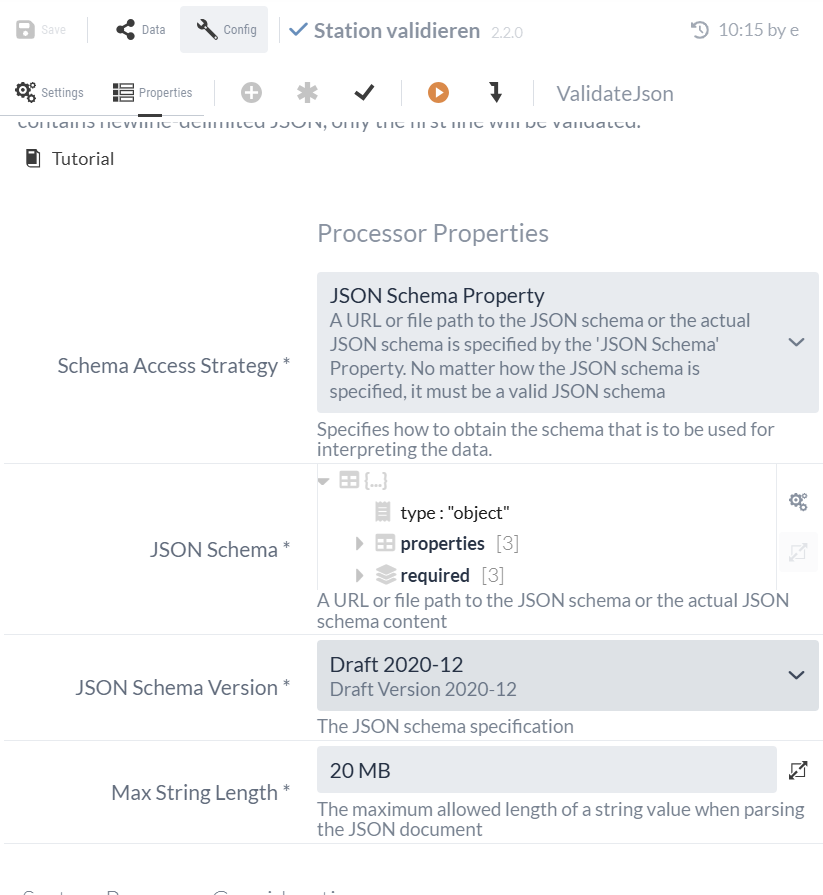
| Mit der Optionsleiste des 'JSON Schema'-Propertys können wir zum Beispiel zwischen dieser Objektansicht und der Textansicht des JSON Schema umschalten. |
Die validen Einträge werden entlang der "valid"-Relation zum HandleHttpResponse Processor mit der erfolgreichen Response Code 200 geschickt, während im Falle eines Validierungsfehlers der andere HandleHttpResponse Processor den Response Code 400 zurückschickt.
Am Ende sollte sich folgender Flow ergeben:
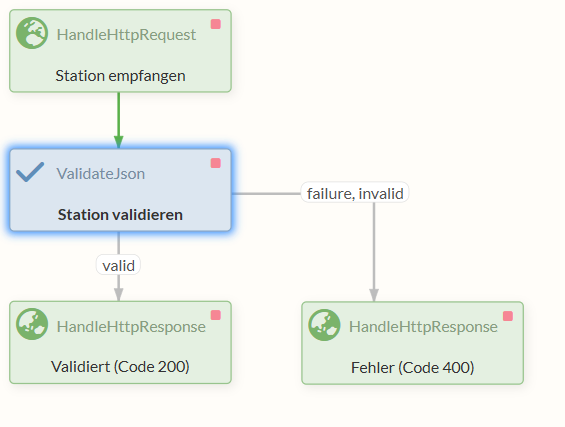
Unser als untergeordnete Process Group implementierter REST Service zum Überprüfen der Daten ist nun fertig und kann gestartet werden.
Teil 3: Daten einzeln an REST Service schicken
In diesem Teil nehmen wir die bereits vorhandenen Daten zu neuen Bahnhöfen und fügen mit dem UpdateRecord Processor jedem Eintrag noch das heutige Datum als Eigenschaft hinzu. Gleichzeitig nutzen wir den Processor, um die Daten von XML zu JSON zu konvertieren.
Die FlowFile wird weitergeleitet zu einem SplitRecord Processor. Dieser packt jeden Eintrag für einen Bahnhof in ein eigenes FlowFile und leitet diese weiter, sodass der nächste Processor, ein InvokeHTTP Processor, statt einem FlowFile mehrere FlowFiles mit jeweils einem Eintrag (Record) erhält. Jede FlowFile wird hierbei unabhängig von den anderen behandelt.
Die Aufgabe dieses Processors ist es, die JSON an den im Teil 2: REST Service implementieren erstellten REST Service zu übergeben, der den Eintrag überprüft und je nach Ergebnis der Überprüfung eine Antwort zurückgibt.
In diesem Tutorial verwenden wir unseren eigenen REST Service, um beide Seiten der Kommunikation zu demonstrieren. In realen Szenarien würden Sie in der Regel einen externen REST Service aufrufen.
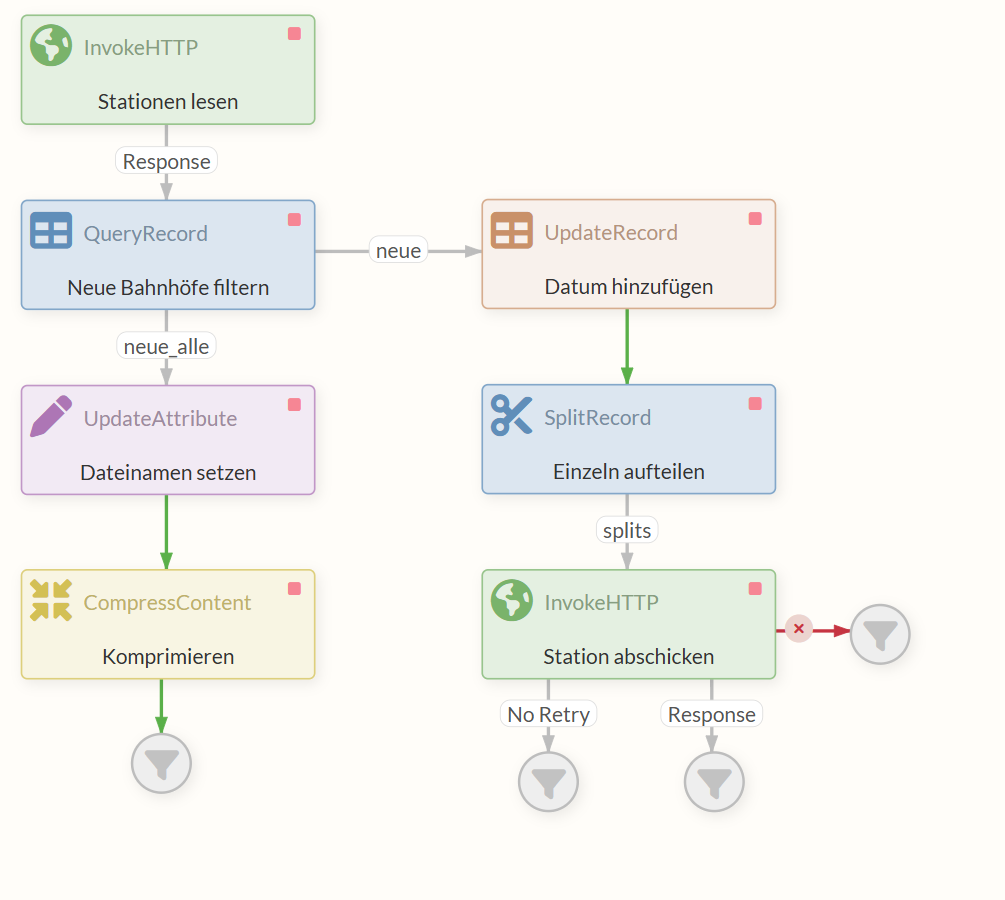
3.1 QueryRecord anpassen (auf Bahnhofnummer und Bahnhofname reduzieren)
In diesem Teil wollen wir aus den CSV-Daten der Bahnhöfe zwecks einer besseren Übersicht nur die Bahnhofsnummer (EVA_NR als NR) und den Bahnhofsnamen (NAME) behalten.
Wir können den vorher erstellten QueryRecord Processor benutzen, um alle anderen Informationen zu entfernen und gleichzeitig, wie auch zuvor, die Daten in ein XML-Format übertragen.
Dazu erstellen wir eine neue Dynamic Property mit dem Namen “neue” und setzen als Wert das passende SQL Statement.
SELECT EVA_NR as NR, NAME FROM FLOWFILE
where Status = 'neu'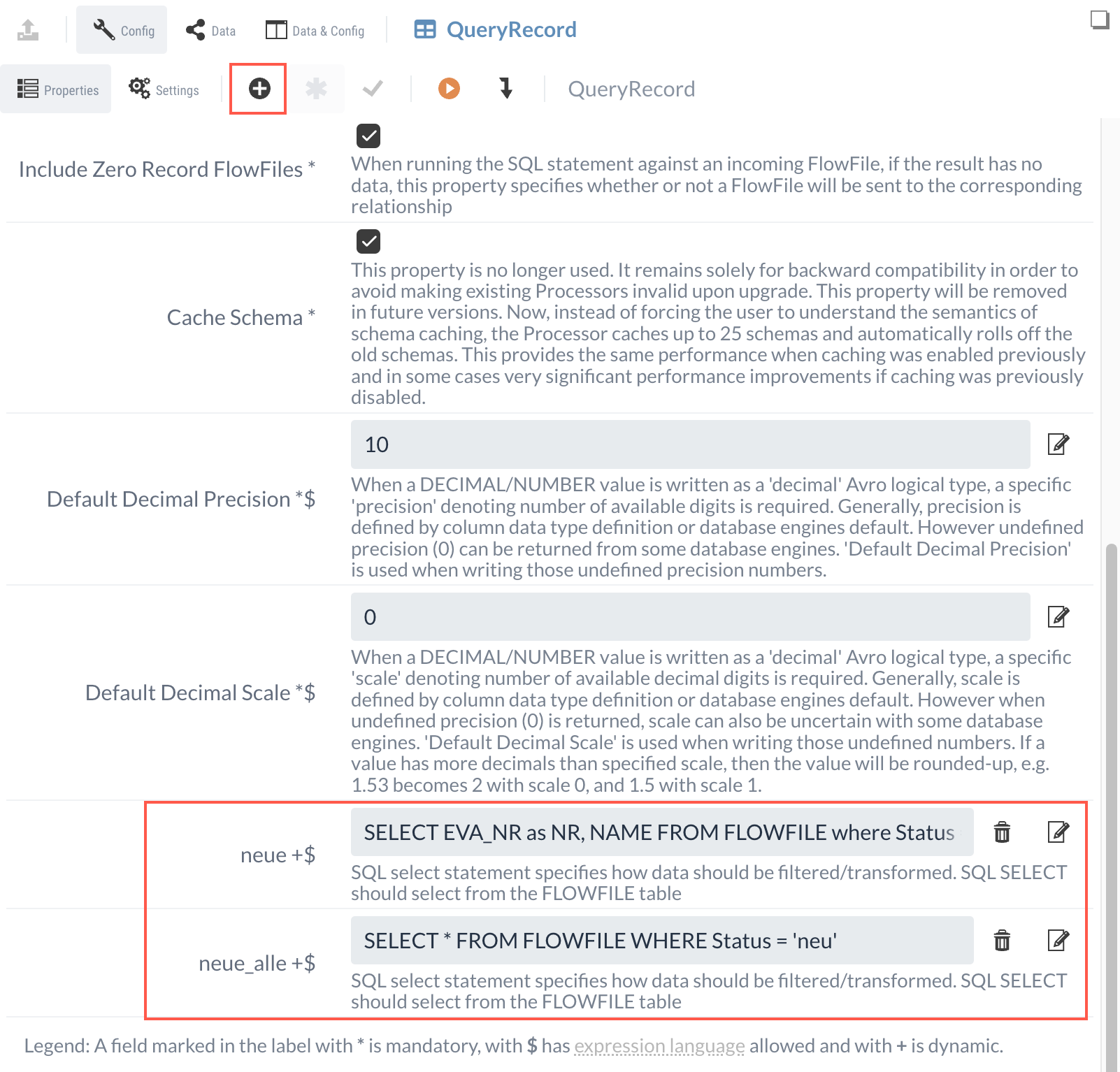
Sowohl “neue” als auch “neue_alle” sind jetzt Ausgänge des QueryRecord Processors. Um die Funktion zu überprüfen, können wir eine Testausführung mit den vorhandenen CSV-Daten machen (siehe Isolierte Prozessausführung (Fortführung)).
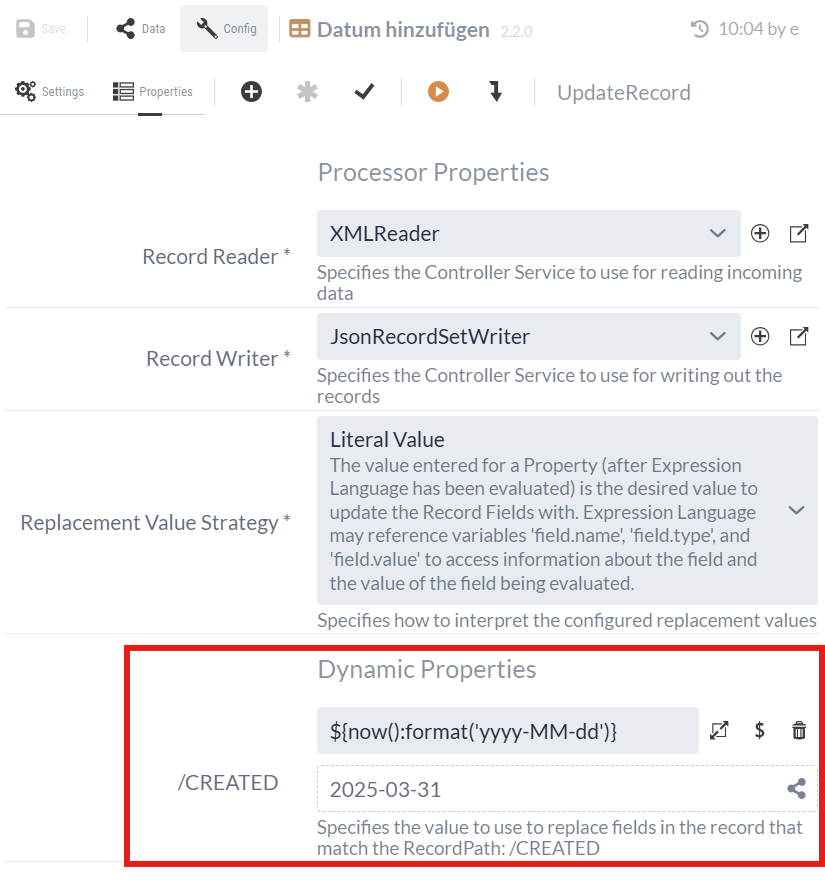
3.2 UpdateRecord Processor (Datum hinzufügen)
Wir wollen, dass sowohl Teil 1 als auch Teil 2 bei jeder Ausführung des Flows durchlaufen werden. Daher werden wir Teil 1 nicht verändern, sondern lassen beide Teile parallel existieren und laufen.
Hierzu verbinden wir unseren nächsten neuen Processor, den UpdateRecord Processor, mit dem gerade angelegten “neue”-Ausgang des QueryRecord Processors. Dieser gibt somit an zwei verschiedene Ausgänge zwei unterschiedliche FlowFiles weiter, die unabhängig voneinander behandelt werden.

Wir wollen jetzt, neben der Nummer und dem Namen des Bahnhofs, zu jedem Eintrag noch das aktuelle Datum hinzufügen. Damit wollen wir zeigen, dass die Informationen dem heutigen Standpunkt entsprechen. Wir verwenden hierfür den UpdateRecord Processor.
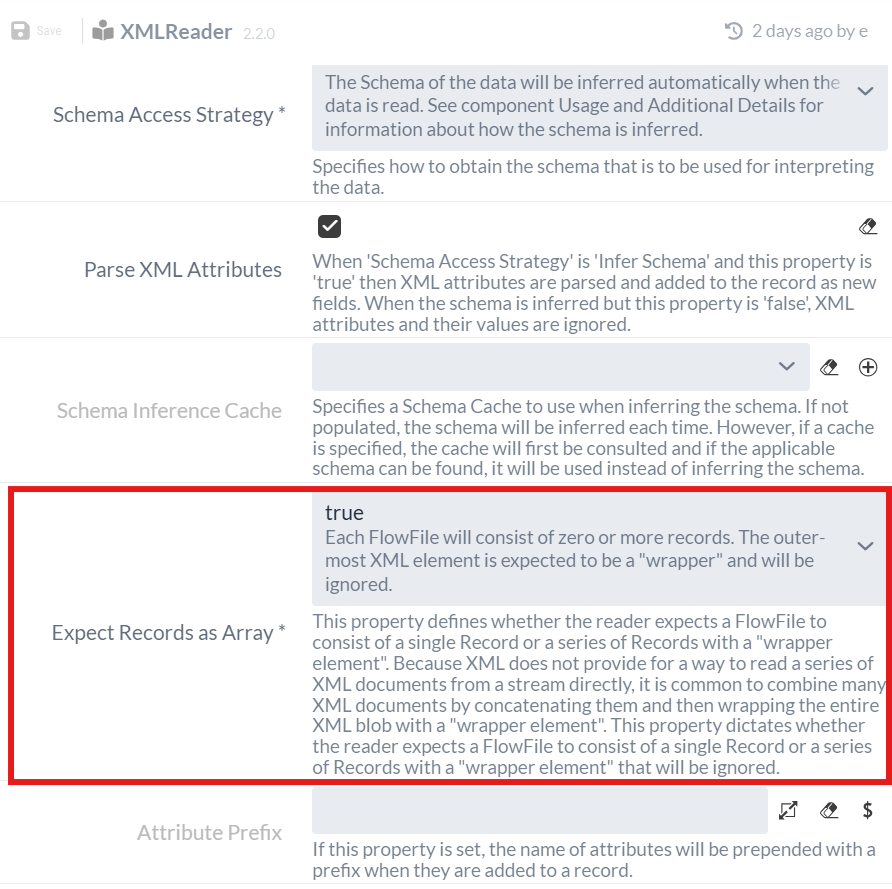
Wie beim QueryRecord Processor in Teil 1, müssen wir einen Record Reader Controller Service und einen Record Writer Controller Service spezifizieren. Da wir unsere Daten im XML-Format von QueryRecord bekommen, brauchen wir einen XMLReader.
Diesen müssen wir, wie im ersten Teil, als Service zur Process Group hinzufügen und in der Konfiguration die Einstellung Expect Records as Array auf "true" setzen, da die Daten als Array im XML ankommen (siehe "Result content" unter Testausführung des QueryRecord Processors).
Für den Record Writer werden wir einen JsonRecordSetWriter Processor mit Standardeinstellungen verwenden. Damit werden die Stationen aus dem XML- in das JSON-Format umgewandelt, da wir letztendlich ein JSON an die REST-Schnittstelle schicken wollen.
Anschließend fügen wir ein Dynamic Property über den -Button hinzu.
Wir nutzen wieder die Expression für das aktuelle Datum und fügen dieses damit zu jedem Record hinzu.
Der Name des Dynamic Property gibt dabei den Namen des zusätzlichen Feldes im Record vor.
(Dieses Vorgehen ähnelt dem vorhergehenden Schritt mit dem UpdateAttribute Processor im ersten Teil des Tutorials, siehe 1.3 UpdateAttribute Processor (Dateinamen setzen).)
|
Da der Wert über einen Record Path angegeben wird, beginnt der Name des Dynamic Property mit einem Schrägstrich ('/'), also z. B. |
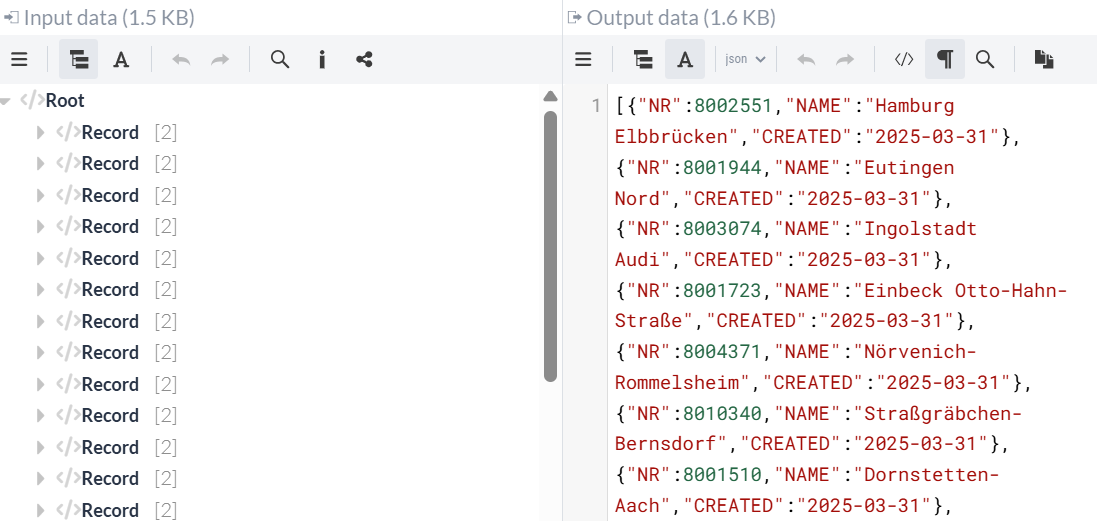
Bei der Ausführung werden die Stationen jeweils aus XML in JSON umgewandelt und mit dem aktuellen Datum hinter dem Namen "CREATED" versehen:
3.3 SplitRecord Processor (Bahnhöfe einzeln aufteilen)
Die FlowFile mit der JSON leiten wir nun in einen SplitRecord Processor weiter. Mit diesem Processor werden wir die Liste der Bahnhöfe in einzelne Elemente aufteilen, sodass pro Bahnhof ein Aufruf des REST-Services erfolgen kann.
Da die Daten im JSON-Format ankommen, brauchen wir einen JSONTreeReader als Record Reader, den wir wieder als Controller Service erzeugen müssen.
Die Standardeinstellungen können beibehalten werden.
Für den Record Writer können wir den JsonRecordSetWriter verwenden, den wir vorher für den UpdateRecord Processor angelegt haben.
Record Reader: JsonTreeReader
Record Writer: JsonRecordSetWriter
Records Per Split: 1
3.4 InvokeHTTP Processor (Bahnhöfe abschicken)
Jedes FlowFile aus dem SplitRecord Processor wird jetzt noch an einen weiteren InvokeHTTP Processor weitergeleitet. Mit diesem Processor rufen wir den REST Service zur Überprüfung der JSON-Daten auf und übergeben den FlowFile Content, also das JSON mit dem Eintrag zu einem Bahnhof, als Body.
HTTP Method: POST HTTP URL: http://localhost:3333/validate
Der Flow sieht nun wie folgt aus:
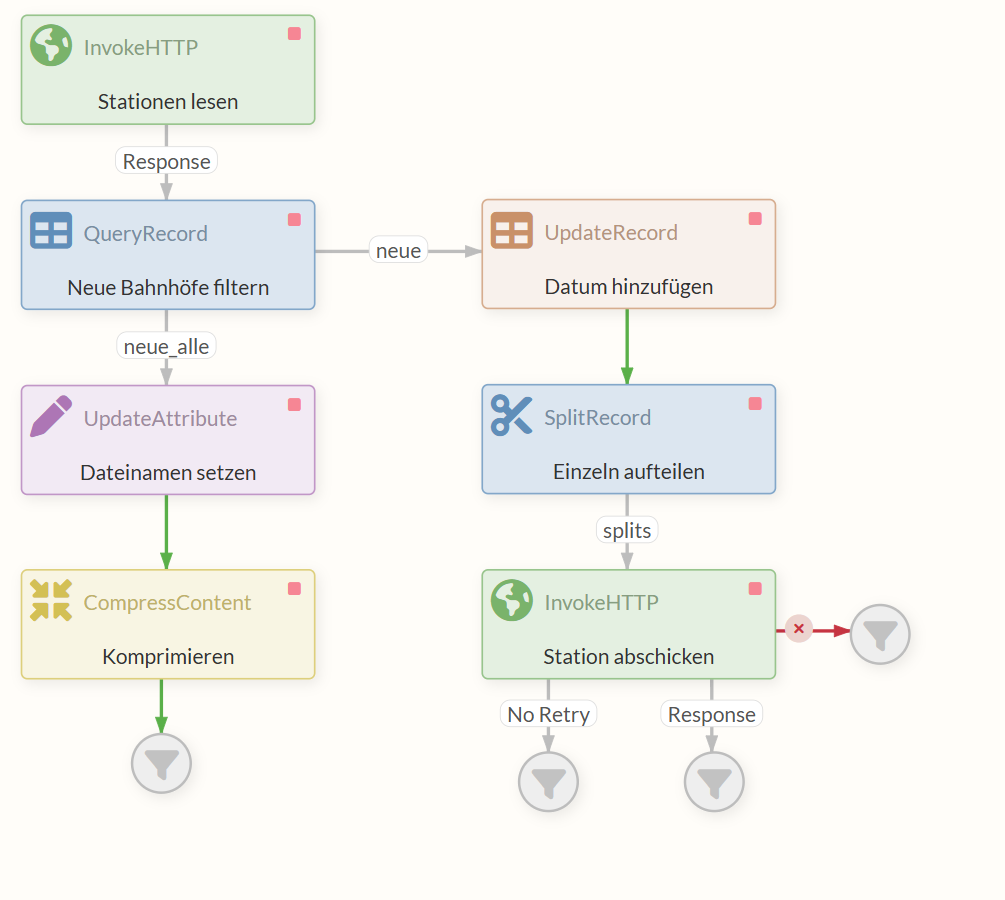
3.5 Ausführung des fertigen Flows
Durch einen Rechtsklick ins Diagramm und die Auswahl Start starten wir alle Processors.
Der obere InvokeHTTP Processor sendet eine HTTP-Anfrage zum Erhalt der CSV-Datei. Sobald er diese mit der Response erhält, wird das FlowFile weitergereicht an den QueryRecord Processor.
Hier spaltet sich der Flow in zwei Branches.
Links wird über die “neue_alle” Relation eine XML aller neuen Bahnhöfe mit allen vorhandenen Infos an den UpdateAttribute Processor übergeben.
Mit dem UpdateAttribute Processor wird das Attribute “filename” gesetzt, das den Namen der später ausgegebenen Datei bestimmt.
Die Content und Attributes umfassende FlowFile wird weitergereicht an den CompressContent Processor, wo aus der XML ein mit gzip komprimierter Datenstrom wird. Dieser landet schlussendlich in der Relation zum Funnel, wo wir uns den Content anschauen und herunterladen können.
Auf dem anderen Branch des Flows wird vom QueryRecord Processor über die “neue”-Relation eine XML ebenfalls mit Daten zu den neuen Bahnhöfen, jedoch nur den Namen und die Nummer, übergeben. Der UpdateRecord Processor fügt dann jedem dieser Einträge eine weitere Information hinzu, nämlich das heutige Datum.
Gleichzeitig konvertiert er die Daten in das vom REST-Endpunkt erwartete JSON-Format. Dieses JSON mit Einträgen zu Bahnhöfen geht dann in den SplitRecord Processor, wo jeder Eintrag einzeln in ein FlowFile gepackt wird, sodass nun statt einem mehrere FlowFiles den Processor verlassen.
Jedes dieser FlowFiles läuft einzeln über die “splits” Response in den InvokeHTTP Processor, der für jede der FlowFiles eine Request mit dem JSON aus dem Content an den von uns implementierten REST Service sendet.
Jedes FlowFile mit validen JSON-Daten produziert eine Response des REST Service mit Status Code 200 und wird dementsprechend in die Relation “Response” geleitet.
Ausblick
Dieses Tutorial hat Ihnen die Grundlagen der Flow-Erstellung mit IGUASU gezeigt.
Für reale Anwendungsfälle bietet IGUASU weit mehr Möglichkeiten.
Dazu gehören beispielsweise fortgeschrittene Strategien zur Fehlerbehandlung und viele weitere spezialisierte Processors und Controller Services, die über den Rahmen dieser Einführung hinausgehen.